因此,對于汽車電子數字化產品的研究,完全可以吸取軟件無線電的以下主要思想:第一,要使汽車電子產品擺脫硬件結構的束縛;第二,并不是不要硬件;第三,汽車電子產品應該具有開放性和兼容性,開放是指對使用的開放、對生產的開放和對研制的開放。下面,就基于軟件無線電的思想探討DSP和FPGA在汽車電子中的主要應用。
基于DSP和FPGA的車用語音信號處理
汽車電子產品中的語音處理主要涉及到語音的數字化處理、語音編解碼、語音壓縮和語音識別。國外比較熱門的汽車電子產品之一就是語音識別系統,語音識別系統具有潛在的應用前景,包括聲控電話、語音操作導航、聲控選擇廣播頻道、防盜語音鑒別等。例如,一種基于隱式馬可夫模型(HMM)的與講話人無關、100條指令識別的應用,由文獻可知,那幺聲學HMM模型的大小將為。進行包括輸入語音采樣的細分/開窗、MFCC提取、概率計算和Viterbi搜尋等適時處理,對DSP的運算量要求一般為10000萬次乘加(MAC)運算。對于連續語音信號的識別,則要求更好的數字信號處理速度和更大的存儲空間。
由于語音識別系統要對聲音進行實時處理和采樣,需要大量的運算,如果以它們20%的計算資源分配用于1000萬次MAC語音識別應用,那么需要處理器能夠具有5000萬次MAC的能力。因此,必須采用DSP和FPGA才能完成其任務。DSP和FPGA的處理速度對語音信號處理應用系統的復雜性和性能起著決定性作用,高速DSP和FPGA的實現可實現聲道自適應和聲域自適應等現代語音處理和識別技術。從理論上講,DSP和FPGA處理速度越快,汽車語音處理和識別產品的應用性能就越好。
隨著應用日益多樣化,DSP和FPGA演變成不再是一塊獨立的芯片,而變成了構件內核。這使得設計師能選擇合適的內核和專用邏輯“膠結”在一起形成專用DSP和FPGA方案,以滿足信號處理的需要。目前,還出現把DSP核和ASIC微控制器集成在一起的芯片。汽車電子系統使用通用DSP和FPGA來實現語音合成,糾錯編碼。而語音合成、語音壓縮與編碼是DSP最早和最廣泛的應用,矢量編碼器用于將語音信號壓縮到有限帶寬的信道中。
]]>ADSP-21xx
結構特點
16-bit定點DSP
帶8-bit保護位的40-bit
ACC單周期執行指令多數指令
可以條件執行
尋址模式
立即數尋址、寄存器直接尋址、存儲器直接尋址、以及寄存器間接尋址。對于ADSP-219x,還有寄存器事后修改、立即修改、直接和間接偏移尋址模式。其程序序列具有內部循環計數和循環堆棧,從而實現零開銷循環。每個地址發生器支持四個循環緩沖器,每個循環緩沖器又有三個寄存器,用來定義循環的終點、長度和訪問的地址。一個地址發生器支持位倒序尋址。ADSP-219x支持十六個循環緩沖器,通過使用一個地址發生器影子寄存器和一組基寄存器,以增加循環緩沖的靈活性。
特殊指令
ADSP-219x可以有條件地執行大多數指令。其do until命令可以建立任意長度的指令序列,作四層嵌套循環。ADSP-219x則支持八層嵌套。ADSP-21xx是非流水機型,因而不會對轉移或子程序調用帶來影響。
開發支持
ADI公司的軟件和硬件開發工具包括該公司的VisualDSP集成開發環境、在線仿真器和開發套件。VisualDSP提供對優化的C編譯器、匯編器、連接器及調試器的接口。該公司的仿真器適用于通用的串口總線、PCI、以及以太網主機平臺。其EZ-Kit Lite包括一個評估板和有限的、但功能齊全的VisualDSP。
TigerSharc DSP
結構特點
16-bit定點DSP
VLIW(超長指令字)結構可以在一個機器周期內執行四條指令
該系列DSP具有SIMD(單條指令多個數據)的能力
第一個TigerSharc DSP集成了6 Mbit的RAM
尋址模式
立即數尋址、位倒序尋址、塊循環、寄存器直接尋址和寄存器間接尋址。其SIMD存儲器傳輸機制使單個取數和存儲指令在兩個存儲器塊和兩個計算單元之間作數據傳輸。
特殊指令
指令集直接支持高精度和低精度類型數據之間的轉換,如在單周期內將定點數轉換成浮點數,將16-bit數轉換為32-bit數。TigerSharc沒有硬件模式,其指令集支持算術功能,如帶符號的和不帶符號的整數和小數運算。這將簡化高級語言的編程。在各種情況下都提供優化的飽和模式。
開發支持
ADI公司的軟件和硬件開發工具包括該公司的VisualDSP集成開發環境、在線仿真器和開發套件。VisualDSP提供對優化的C編譯器、匯編器、連接器及調試器的接口。該公司的仿真器適用于通用的串口總線、PCI、以及以太網主機平臺。其EZ-Kit Lite包括一個評估板和有限的、但功能齊全的VisualDSP。
SHARC DSP
結構特點
16-bit定點DSP
支持定點和浮點運算
新的SIMD錘頭運算(Hammer-head operates)
集成有大的SRAM
尋址模式
立即數尋址、索引尋址、位倒序尋址、塊循環、寄存器直接尋址和寄存器間接尋址。(對于片外存儲器的訪問,必須采用間接尋址。)
特殊指令
SHARC提供位操作、平方根的倒數、條件子程序調用、零開銷單條指令和塊指令循環、定點數和浮點數的比較、以及大多數指令的條件執行。SHARC支持IEEE-754單精度浮點數(23-bit尾數、8-bit指數以及符號位),40-bit擴展精度IEEE格式(32-bit尾數)。
開發支持
ADI公司的軟件和硬件開發工具包括該公司的VisualDSP集成開發環境、在線仿真器和開發套件。VisualDSP提供對優化的C編譯器、匯編器、連接器及調試器的接口。該公司的仿真器適用于通用的串口總線、PCI、以及以太網主機平臺。其EZ-Kit Lite包括一個評估板和有限的、但功能齊全的VisualDSP。其SHARC匯編語言以一種代數式語法為基礎。
Lucent
DSP-16xx
DSP 16000
DSP 16xx
結構特點
16-bit定點DSP
具有16316-bit的乘法器
36-bit的ALU/移位器
所有片種都有片內ROM
工作在2.7-4.75V
特殊指令
單條指令/塊指令的硬件循環,條件子程序調用,比較,混合尋址,指數檢測,bit位提取、移位和替換。沒有旋轉指令。
開發支持
其硬件開發系統包括在線仿真器。評估板和演示板。軟件開發工具包括匯編器/連接器,調試器,軟仿真器和應用程序庫。EDA廠商還提供將DSP軟仿真器模塊插入的系統級的仿真工具。
DSP 16000
結構特點
雙MAC單元
支持16332-和32332-bit的乘法ALU
支持16-、32-、40-bit運算
X和Y存儲器具有32-bit數據寬度
尋址模式
寄存器和存儲器直接尋址,寄存器間接尋址,立即數尋址以及寄存器+置換尋址。由于器件不提供位倒序尋址,只能用軟件來實現。支持兩個并發的循環緩沖器。尋址模式面向指針算術運算。
特殊指令
支持16-bit和32-bit的混合指令。因為轉移需要三個機器周期,許多指令的條件執行可以避免轉移。Redo指令可以重新運行用do指令裝入cache的代碼。其追索編碼器將加速Viterbi比較指令的執行,并產生模式控制的效果。此外,用戶可以使用比較指令來決定Viterbi處理的最小公共通道。其他的特殊指令還有旋轉、取負、取絕對值和定點算術運算。
開發支持
軟件工具包括ANSI C 編譯器、匯編器、連接器、調試器和軟仿真器。硬件工具包括在線仿真器和開發板。基于Gnu C的C編譯器進行局部和全局的優化,以便進行C源代碼的調試,也可作C和匯編混合代碼的調試。匯編器支持ANSI C預處理,允許文件包含、宏置換、條件匯編,以及各種常數格式。該匯編器還允許表達式包含多個用戶定義的標號,并支持預處理偽指令,使匯編器與調試器共享宏運算。調試器支持單個或多個同類的或不同類的處理器的集成調試。支持數據和指令斷點、接近實時的軟件仿真、混合的C代碼和匯編代碼調試、廣泛的代碼分析、用TargetView通信系統通過JTAG來作獨立的或連網的硬件仿真、硬件跟蹤,以及片內的周期計數。廣泛的片內調試硬件可以實時監視許多處理器。在調試器中單步運行代碼時,可以圖形化地顯示通過DSP的數據流。這樣,用戶可以觀察到處理器中沒有充分使用的部分,修改代碼來提高效率。Synopsys COSSAP, Cadence SPW, 以及 Mathworks Matlab 等第三方的工具也支持 DSP16000的仿真。軟件工具的價格為1500美圓,硬件工具的價格為5000至7000美圓。
Motorola
DSP-56800
DSP 563xx
DSP 56800
結構特點
16-bit定點DSP
帶有控制功能的DSP
可以中斷的硬件do循環
工作于2.7V和70MHz
尋址模式
寄存器直接尋址、短的或長的存儲器直接尋址、七個存儲器間接尋址、以及立即數尋址。還支持短的轉移偏置和循環緩沖器的模數計算。
特殊指令
可以作單指令或塊指令的硬件do或repeat循環。與ALU運算并行的單個或雙的并行搬移指令,在取指令的同時允許作兩個存儲器訪問。允許對任何寄存器或存儲器作位操作。在作單周期乘法和MAC的同時,作取整、加、減、平方。使用一個條件轉移指令和比較指令,實現搜索和分類算法。如果特定的條件為真,則DSP執行從一個寄存器到另一個的傳輸(例如,存儲一個數列里最大值的索引值)。
開發支持
使用OnCE口,通過JTAG接口作片上仿真。CodeWarrior提供集成的開發環境,其中包括C編譯器、匯編器、連接器、軟仿真器、以及圖形化的源代碼和匯編級的調試器。其評估模塊為DSP56824EVM,開發系統為DSP-56824ADS。
DSP 563xx
結構特點
24-bit定點DSP
七級流水,包含兩個取指、一個解碼、兩個地址產生、以及兩個執行
具有條件ALU指令
以寄存器為基礎的結構
與核執行單元并發的六通道DMA操作
多數器件工作于3.3V,并兼容5V的I/O;有些器件工作于1.8V,兼容3.3V的I/O
與核并行工作的濾波器協處理器
特殊指令
桶型移位器支持多bit移位指令,可以在兩個方向上移動任意多位。該移位器還支持bit流解析與產生。支持并行ALU指令的條件執行。如果測試條件為假,則處理器執行NOP指令。563xx執行16-bit的算術運算,這對于諸如LD-CELP等壓縮算法非常有用。通常,用24-bit的結構來作16-bit的運算時,性能會有所降低,因為必須用軟件對24-bit的數作舍入運算。
開發支持
開發系統可以用于評估芯片和目標系統。該系統包括應用開發模塊、主機接口卡、命令轉換器、匯編器、軟仿真器、以及C編譯器。以JTAG為基礎的OnCE口可用于實時檢查所有的內部總線,記錄最后的十二條指令。MOTOROLA提供用于DSP563xx系列的套裝的56種硬件的和軟件的工具。第三方的工具包括Tasking的編譯器和調試器,Domain Technologies的調試器。
Lucent/Motorola
StarCore SC100
StarCore SC100
結構特點
16-bit定點DSP核
DSP結構可以升級
可變長度指令提高代碼的效率和并行性
更好的C程序編譯器
尋址模式
寄存器直接尋址、地址寄存器間接尋址、與程序計數器相關的尋址模式、以及用立即數來決定感興趣的數據或地址的特殊尋址模式。
特殊指令
SC140的多個乘法器支持帶符號的和無符號操作數,包括小數與整數格式的運算及其各種組合。其MAC單元支持加、減、取負、取絕對值、以及清零。MAC單元還支持除法、比較、最大值/最小值運算,在寄存器、算術移位和取整之間轉移。通過將寄存器中的值看成是打包成對的16-bit的操作數,支持單指令多數據(SIMD)的最大值/最小值、加、減(MAX2,ADD2,SUB2)。使用這些指令,可以在單個周期內執行八個加法,或最大值/最小值運算。SC140包括一個專門的最大值/最小值運算單元,和維特比(Viterbi)的左移指令一起工作,以便有效地實現維特比編碼算法。
開發支持
其開發工具包括匯編器、優化器、連接器、軟仿真器、ANSI C編譯器及與C11兼容的C/C11編譯器。該編譯器支持ITU/ETSI標準。
Texas Instrument
TMS320C2000
TMS320C5000
TMS320C6000
TMS320C2000
結構特點
16-bit定點DSP
哈佛結構支持兩個分開的總線結構
雙訪問RAM允許在同一個周期內讀或寫RAM兩次
工作于3.3V
綜合介紹
TI的TMS320C2000 DSP是基于320C2xLP核。C2xLP核具有4級流水,工作在40MHz。具有JTAG仿真模塊。
C2xLP有一個中心算術邏輯單元(CALU),及32-bit的累加器(Acc)。Acc也是CALU的一個輸入。Acc的其他輸入包括16316-bit的乘法器通過定標移位器,以及輸入數據定標移位器。軟件可以通過進位位旋轉Acc的內容,來實施位操作和測試。
為了實現小數的算術運算和驗證小數的乘積,C2xLP的乘積寄存器的輸出通過乘積移位器,以抑制運算中產生的多出來的bit。該乘積定標移位器允許作128個乘積累加而不會產生溢出。基本的乘積累加(MAC)周期,包括將一個數據存儲器的值乘以一個程序存儲器的值,并將結果加給累加器。當C2000循環執行MAC,則程序計數器自動增量,并將程序總線釋放給第二個操作數,從而達到單周期執行MAC。
C2xLP可以訪問64000個16-bit的I/O口。C2000的外設,諸如串口、軟件等待狀態發生器等都映射為數據或I/O空間。用戶程序必須使用其他的I/O地址來訪問映射在I/O空間的片外外設。C2000系列中的多數芯片可以產生0-7個等待狀態。
C2000系列由C20x和C24x系列組成。C20x的目標是低性能的電信設備,而C24x的目標是數字化的馬達控制。
C24x系列的芯片具有事件管理器,以便支持馬達控制。該事件管理器具有三個加/減定時器和九個比較器,可以和波形產生邏輯配合產生12PWM的輸出。支持同步的和異步的PWM產生。它還支持一個空間向量PWM狀態機,用開關功率晶體管來實現,以延長晶體管的壽命和降低功耗。一個關機段產生單元也有助于保護功率晶體管。此外,事件管理器還集成了四個采集輸入,其中的兩個用于光編碼器正交脈沖的直接輸入。
C24x系列的芯片還集成有10-bit的A/D變換器,在500ns的時間內對模擬信號作變換。另外還有8個或16個復用輸入通道。有些新的C24x系列的芯片還有自動排序的能力,按順序作16個變換,一個獨立的采樣/保持(S/H)預定標器,通過支持不同的輸入阻抗,給用戶以極大的靈活性。有些C24x系列的芯片有8K-32K字的閃爍存儲器(flash)。
尋址模式
立即數尋址、分頁的存儲器直接尋址(指令里的7-bit和數據頁指針的9-bit形成數據存儲器的地址)、寄存器間接尋址(使用8個輔助寄存器中的一個)、輔助寄存器自動增量或減量尋址。沒有循環緩沖。
特殊指令
MAC和數據移動指令(MACD)增加了將片內RAM的數據塊移向MAC單元。當CPU使用輸入的數據值時,CPU將該數據值移至下一個存儲器單元。MACD也是使用循環緩沖器的一個替代方法,對于卷積和橫向濾波器是很有用的。C2000可以作單指令循環、乘法并累加前一個積、乘法并減去前一個積、累加前一個積并移動數據、多條件轉移和調用、存長立即數到數據存儲器、向左或向右旋轉累加器、數據塊移動。
開發支持
TI的Code Composer4.10是一個集成的開發環境,支持編輯、建立、調試、分析和項目管理。這個價值為1995美圓的開發環境包括ANSI C編譯器、匯編器、連接器、軟仿真器、實時分析器,數據是可視化的。TI的仿真器支持JTAG非插入式的邊界掃描仿真。該公司也分別提供C編譯器、匯編器、連接器、軟仿真器、實時分析器和應用程序庫。第三方可以提供評估模塊、仿真器、以及應用算法。
TMS320C5000
結構特點
16-bit定點DSP
C55x有雙MAC單元;C54x有單MAC單元
C55的指令長度可變,且沒有排隊的限制
C55x有12組總線;C54x有8組總線
工作于0.9V和300MHz
綜合介紹
C5000是16-bit定點DSP系列,包括舊有的C5x、當前主流的C54x和最新的C55x。
C55x和C54x源代碼兼容,而C5x和C2x源代碼兼容。C54x關注于低功耗,而C55x則將低功耗提到一個新水平:300MHz的C55x和120MHz的C54x相比,性能提高5倍,而功耗則降到六分之一。盡管C5x還在全線生產,但公司已經將新設計轉向C54x 和C55x。C54x 和C55x采用改進的哈佛結構。
C55x 具有12組獨立的總線,而C54x則有8組。它們都有一組程序總線和相應的程序地址總線。C54x總線的寬度為16-bit,而C55x總線的寬度為32-bit。C55x有三組數據讀總線和兩組數據寫總線,而C54x有兩組數據讀總線和一組數據寫總線。每組數據總線都有其相應的地址總線。C55x的數據地址總線的寬度為24-bit,而C54x的數據地址總線的寬度為16-bit。
C54x使用兩個輔助寄存器算術單元,在每個周期內產生一個或兩個數據存儲器地址。這四組內部總線和兩個地址發生器使其可以進行多操作數運算。
C55x的地址-數據流單元(ADFU)包含了專門的硬件來管理五組數據總線。該ADFU也可以作為通用的16-bit ALU,用于簡單的算術運算。該ALU從指令緩沖單元(IU)接收立即數,和存儲器、ADFU寄存器、數據計算單元(DCU)寄存器、程序流單元(PFU)寄存器作雙向通信。無論是ALU,還是三個地址寄存器ALU(ARAU)中的一個,都可以修改作間接尋址的九個地址寄存器。這三個ARAU為C55x的三組數據讀總線提供獨立的地址。這種并行性保證了在每個CPU周期內DCU去讀兩個16-bit的操作數和一個16-bit的系數。
C55x的DCU包含了兩個MAC單元,在單周期內作兩個17217-bit的MAC運算。它還包含了一個40-bit的ALU和四個40-bit的累加器寄存器、一個桶型移位器、以及專門的Viterbi算法硬件。每個MAC單元包含一個乘法器和帶32-或40-bit飽和邏輯的加法器。三個數據讀總線將兩個數據流和一個公共系數流送給兩個MAC單元。用戶可以用ALU作32-bit的運算,或分開作兩個16-bit的運算。除開接受從DCU的40-bit Acc寄存器來的輸入外,ALU還從IU接受立即數,并和存儲器、ADFU寄存器、PFU寄存器作雙向通信。
C54x是單17217-bit MAC機器,有一個40-bit的加法器、兩個40-bit的Acc和一個分開的40-bit的ALU。與C55x相類似,C54x的ALU也可以作成兩個16-bit的配置,完成兩個單周期運算。乘法器輸出處的40-bit的加法器允許作非流水的MAC運算,以及并行的兩個加法和乘法。單周期歸一化和指數編碼支持浮點數運算。
兩個系列的結構都支持一個桶型移位器,將40-bit的Acc的值左移或右移最多達31bit。該桶型移位器將移位后的值送給DCU的ALU,以便作進一步的運算。指令集中關于二操作數、三操作數和32-bit操作數的指令,支持結構的并行性。八個可以獨立尋址的輔助寄存器和軟件堆棧提高了C編譯器的效率。
C55x可以執行可變長度的指令,這和C54x有顯著的不同。C54x的指令長度為固定的16-bit,而C55x的指令長度則從8到48 bit。C55x的IU緩存64 byte的代碼,且有一個解碼邏輯來確認可變長度指令中各指令的區別。局部循環指令使用指令緩沖隊列來循環執行代碼塊。指令緩沖隊列還可以在執行條件程序流控制指令的條件測試時,推測性地提取指令。指令解碼器按排列順序對指令解碼,而不是執行動態時序,從而可以在預定的時間得到結果。
C55x的PFU跟蹤程序的執行點,并為多達16Mbyte的程序存儲器產生24-bit的地址。該單元的硬件,可用于循環、靈活性轉移、條件執行、以及流水保護。單獨的程序計數器可以保證從子程序或中斷服務子程序快速返回。該PFU還包括管理指令流水和四個CPU狀態寄存器的邏輯。它以硬件方式可以提供四層塊循環嵌套。其硬件還支持條件循環。PFU處理流水控制冒險,并對讀后寫及寫后讀提供保護。當在指令流中這種冒險發生時,流水保護邏輯就插入一些周期,保證程序的正確執行。集成的軟件等待狀態發生器使用戶可以使用較慢的外部存儲器。
該系列的所有DSP都支持片內雙訪問RAM(DARAM),用戶可以將其配置為程序存儲器或數據存儲器。C55x還有擴展的同步突發性RAM、同步DRAM和異步SRAM及DRAM。片內的鎖相環(PLL)允許用戶抑制時鐘,但C55x核還可以激活與自動管理片內外設和存儲器的功耗。當程序不再訪問片內存儲器時,它們就會被切換到低功率模式。處理器對片內外設也提供類似的控制。
C55x還設置了用戶可控的低功率IDLE域,包括CPU、DMA、外設、外部存儲器接口、指令隊列、以及時鐘發生電路。
尋址模式
C54x支持單數據存儲器操作數尋址和32-bit操作數尋址,還使用并行指令支持雙數據存儲器操作數尋址。它也提供立即數尋址、存儲器映射尋址、循環尋址和位倒序尋址。
在C54x的基礎上,C55x還支持絕對值尋址、寄存器間接尋址、直接尋址,即位移模式。C55x的ADFU包括專門的寄存器,支持使用間接尋址指令的循環尋址。可以同時使用五個獨立的循環緩沖器和三個獨立的緩沖器長度。這些循環緩沖器沒有地址排隊的限制。C54x支持兩個任意長度的循環緩沖器。
特殊指令
C54x有專門功能指令,如FIR濾波器、單指令或塊指令循環、八個并行指令(如并行存儲或乘加)、乘法累加和減(十個乘法指令)、八個雙操作數存儲器搬移。C55x還有專門的指令,充分利用增加的功能單元和并行能力的優點。用戶定義的并行機制,允許將執行兩個操作的指令加以組合。
開發支持
eXpressDSP軟件技術包括DSP集成開發工具:可升級的實時軟件基礎、可重復使用的應用軟件接口標準、以及不斷增加的第三方的軟件模塊。Code Composer Studio是一個集成的DSP開發工具套件,包括C5000的C編譯器、DSP/BIOS、實時數據交換技術等。
引言
現在,由于復雜的硬件功能已經集成到標準集成電路中,系統開發人員首先應該知道如何選擇合適的芯片,然后基于此硬件結構設計軟件。系統設計者有兩種選擇:使用專用集成電路或可編程DSP實現信號處理。相比之下,可編程DSP有兩個優點:
可擴充性:設計者可以根據要求的處理效率,和需要的資源來量體選用DSP及所需的片數。
可升級性:將硬件的升級轉化成比較容易升級的軟件改動。
使用可編程DSP時,必須對芯片的各種資源(例如CPU,存儲區,外設等)加以管理規劃,通過DSP/BIOS可以輕松的完成這些工作。
TI公司TMS320C5000系列都帶有嵌入式DSP/BIOS,它有很強的實時分析和任務實時管理能力,可以有效的提高項目的開發效率,尤其表現在需要實時多任務的大型系統中。圖1為DSP/BIOS的部件結構。
DSP/BIOS II簡述
TI公司的DSP/BIOS II 是在DSP/BIOS I 基礎上的擴展。它支持更多的軟件模塊,通過修改內核提供搶先式多任務服務;它把傳統并行處理系統的內核服務集成為可測試內核;它增加了設備獨立的I/O數據流模型,繼續保留已有的數據管道;它增加了動態內存分配與內存管理。
TI的開發平臺CCS IDE 2.0中集成了DSP/BIOS II,可以對程序進行實時跟蹤與分析,提高應用程序開發的可靠性。可以在CCS插件中實時觀察DSP/BIOS內核中各線程的執行狀態與對象的當前屬性。通過設置工具,開發者可以對各個模塊實行配置。
DSP/BIOS II 核心API技術
目標應用程序通過調用DSP/BIOS II的API來獲得運行時的服務。一個單個DSP/BIOS II 模塊可以管理多種類的內核對象,并且依據全局參量的設定來控制整個行為。DSP/BIOS II 可以歸納為六大種類:
內核執行線程 
圖1 DSP/BIOS 部件結構圖
圖2 線程優先級示意圖
圖3 數據流示意圖
圖4 數據管道示意圖
DSP/BIOS II提供四類不同的執行線程。每一類線程又具有不同的執行、搶先和懸掛特性。DSP/BIOS II 支持兩個高優先級的中斷線程和事先備好的后臺空閑過程循環。內核執行線程通過HWI, SWI和IDL模塊進行管理。另外,DSP/BIOS II新提供了多任務線程類,能較好的完成任務間的同步,它由TSK模塊管理,在任何執行時刻為懸掛和恢復執行同步,包括調整自身或其他任務的優先級。這種同步化的任務給并發系統設計提供了良好的基礎。
硬件抽象
DSP/BIOS II 提供硬件的邏輯接口。它獨立于硬件實現。它對硬件部分的訪問、配置,內存映射、片內定時器和硬件中斷等進行抽象,簡化了應用的移植。它通過可視化的設置工具定義內存映射、中斷向量表,對定時器編程,和完成動態的內存分配與釋放。
設備獨立I/O
設備獨立I/O模塊執行數據傳輸服務,傳輸可以在DSP與外設之間和多線程之間進行。DSP/BIOS II 支持數據管道(pipe)和數據流(stream)兩種傳送方式。數據管道是在讀寫線程之間快速傳送數據的小型統一部件。數據流為緩沖方案增加了靈活性使之適應更廣的需求。數據流依靠多個潛在的設備驅動器,這種設備驅動器封裝了設備獨立的屬性與方法。在數據通過堆疊(stacking)機制傳送時,設備驅動器能夠執行數據處理操作,驅動器在數據通道中實行流水線處理。PIP和SIO模塊分別管理目標應用中的數據管道和流的傳送服務。SIO同DEV模塊結合,使DEV通過SIO發送和接收數據。
線程間的通信和同步
DSP/BIOS II 中的線程間通信和同步模塊支持多任務。信號量(semaphores)是最主要的同步方式。任務運用信號量保持同步資源訪問的同步。訪問外設的數據緩沖區,以及訪問共享存儲區都是資源同步的典型事例。信號量還控制著多任務執行的同步。信號量由SEM模塊管理,而LCK模塊提供共享資源的判優和互斥。數據隊列可用于線程間通信。郵箱(mailbox)類似于數據隊列,能夠理想的完成任務通信。數據隊列由QUE模塊管理,郵箱模塊由MBX管理。
實時分析
實時分析(TRA)模塊在應用程序執行期間與DSP項目實時交互和診斷。LOG,STS和TRC模塊對這些功能進行管理。主機與目標板之間的數據傳輸能力對實施分析是非常關鍵的。DSP/BIOS提供HST和RTDX模塊來管理這些功能。CCS IDE中提供了以下六種實時分析工具:
—CPU負載圖
負載圖提供的是目標CPU的負載曲線。CPU負載的定義是除去執行最低優先級任務以外的時間量。最低優先級任務是只在其他線程都不運行時才執行的任務。因此,CPU負載包括從目標向主機傳送數據和執行附加后臺任務所需的時間。
——執行圖示
在執行圖示窗口中,我們可以看到各個線程的活動方式。執行圖的刷新速率可以通過RTA控制版設定。圖形中還包括了信號量的活動,周期性函數標記(tick),和時鐘模塊標記。執行圖示能從整體上看到項目所有線程的活動狀態。
——主機通道控制
利用信道控制窗口可以把文件綁定在定義的主機通道上,啟動信道上的數據傳輸以及監測數據傳輸流量。
——信息記錄
選定某一記錄名,從此窗口可看到程序運行的信息記錄。主機從目標板獲取DSP/BIOS數據期間的記錄信息將顯示在此窗口中。開發者定義的記錄信息也顯示在窗口中。
——統計觀察
統計觀察窗可以計算出事件、變量出現的次數,給出其最大值,最小值和平均值,監測定時時間和變量的增值的實際值和期望值差。
——實時控制面板
它對運行時間中不同類型進行追蹤控制,在默認情況下,所有類型的跟蹤都是允許的。為跟蹤任意一種類型,必須使能全局主機(GLOBAL HOST)。通過實時改變控制版的屬性,還可以設定實時分析工具的刷新頻率。
- 3種型號可供選擇:4300、4000PL以及4000
- 使用世界上最堅固耐用的電纜測試儀,可以對電纜和光纜進行測試、認證以及文檔備案。利用高速數字處理技術進行快速的測試。
- 出眾的診斷功能使故障排除更加快速簡便
- 全新 PM06!測試頭是第一個可以測試 Cat 6 是否符合標準以及互用性的中性、屏蔽插頭
- 新的永久鏈路適配器可獲得更多的“通過”結果,消除錯誤的“失敗”結果
- 功能強大的光纜測試適配器可執行雙光纜、雙波長的光纜認證
- 使用 LinkWare? 電纜管理軟件可以方便地對電纜和光纜進行管理和文檔備案
- 支持中國國家標
對于高速的銅纜和光纜,DSP-4300數字式電纜分析儀是最全面的電纜測試和驗證工具。擁有了它,您將獲得精確的測試結果。
- 超過5類、超5類及6類線測試所要求的三級精度,延展了DSP-4000的測試能力,并同時獲得 UL 和 ETL SEMKO的認證
- 使用新的突破性的永久鏈路適配器可得到更多更準確的“通過”結果,DSP-4300中包含該適配器
- 隨機提供6類通道適配器及一個通道/流量適配器,從而精確測試6類通道
- 自動診斷電纜故障,以米或英尺準確顯示故障位置
- 擴展的16MB主板集成存儲卡可存儲一整天的測試結果(300個)
- 可將符合TIA-606A標準的電纜ID號下載到DSP-4300數字式電纜分析儀中,節省時間同時確保了數據的準確性
- 隨機提供外置存儲卡以及更高級的電纜測試管理軟件包
|
DSP-4000系列數字式電纜分析儀選購指南 | ||||
|
|
DSP-4300 |
DSP-4100 |
DSP-4000PL |
DSP-4000 |
|
標準DSP-4300系列包裝 |
● |
● |
● |
● |
|
Cat6/5e 永久鏈路適配器 |
● |
|
● |
|
|
Cat6/5e 通道適配器 |
● |
● |
● |
● |
|
Cat6/5e 通道/流量適配器 |
● |
|
|
|
|
主板集成存儲卡 可存儲多達300個測試結果 |
● |
|
(僅限于概要測試) | |
|
多媒體卡及讀卡器 |
● |
● |
|
|
- 全新的六類測試系統解決方案,提高最高的性能,獲得更多“通過”結果
- 消除由于不良鏈路接口適配器造成的"失敗"結果,節省測試時間和成本。
- 高于建議TIA/EIA-568-B標準的精度和可重復操作性。
- 堅固耐用,專有的設計保證在現場對回波損耗測試所要求的精度和穩定性。
- 符合TIA/EIA-568-B標準。
滿足標準要求,贏得更多合同
安裝用于網絡運行的電纜,依賴于精確地測試及認證測試。福祿克網絡增強的6類通道適配器具備更強大的測試能力,提高了測試精度。
現在您可以利用DSP的精度來測試6類的通道,DSP-4300數字式電纜分析儀所帶的6類通道適配器由于使用了遠端連接補償技術,性能進一步增強,可以得到比其它任何一種測試儀更精確的通道測試結果,讓您更真實的看到電纜系統的性能。
數字測試技術可得到更好的診斷性能,更快的速度以及更高的測試精度
DSP-4300系列數字式電纜分析儀是市場上第一臺基于可擴展數字化平臺的測試儀器,確保滿足新標準的要求。這意味著您在DSP-4000系列數字式電纜分析儀上所付出的投資,即使到將來也是受到保護的。
- 同時在兩個波長測試兩條光纜并自動存貯測試結果。
- 雙向測試被測光纜并將結果存貯在一個記錄中。
- 使用電纜管理軟件進行全面的數據管理和報告生成。
- 自動測試損耗、長度和傳輸時延。
- 驗證光纜連通性,測定配線架上光纜連接的接頭。
- 通過光纜和遠端進行通話。
- 跟蹤測試過程中最大和最小的功率輸出。
- 可承受測試中的跌落和其他意外事件
福祿克網絡的DSP-4300系列數字式電纜分析儀包含功能強大的LinkWare(電纜管理)軟件(DSP-CMS),使用它可根據工作地點、客戶、建筑等快速組織、編輯、查看、打印、存儲或對測試結果進行存檔。可以將測試結果合并到一個已經存在的數據庫中,并根據任一字段或參數對這些數據進行排序、搜索以及重組。
- 圖形測試報告,用彩色圖形描述當DSP-4300測試頻率從1HZ至350MHZ的所有被測量參數。
- 文本格式的數字式匯總測試報告(最壞的情況及最差的數據點)
- 提供所有被測電纜鏈路的列表匯總報告,包含一些關鍵信息
到目前為止,電纜的識別、認證和管理還沒有集成在一起。通過聯合電纜管理軟件(CMS)和標簽公司,福祿克網絡公司已經開發出了集成式文檔解決方案。
最高性能:TMS320C6000? DSP 平臺C6000? DSP 平臺提高了性能和成本效益的水準,提供業界最快的 DSP,運行速度高達 1GHz。該平臺由 TMS320C64x? 和 TMS320C62x? 定點系列以及 TMS320C67x? 浮點系列組成。應用領域包括寬帶基礎設施、高性能音頻以及視頻/成像。性能范圍從 1200 到 8000MIPS(定點器件)和 600 到 1800MFLOPS(浮點器件)。
最低功耗:TMS320C5000? DSP 平臺待機功耗低至 0.12mW,性能高達 900MIPS,C5000? DSP 是眾多應用的理想選擇,包括:數字音樂播放器、GPS 接收器、便攜式醫療設備、MIPS 密集型語音和數據處理等個人和便攜式產品,以及極其經濟高效的單通道和多通道應用。TMS320C55x? 系列提供業界最低的待機功耗和先進的自動電源管理。TMS320C54x? 系列提供廣泛的性能、低功耗操作以及外設和封裝的選擇。OMAP59xx DSP 將 C55x DSP 內核與 TI 增強型 ARM925 相集成,從而提供具有低功耗實時信號處理能力的 DSP 和具有命令和控制功能的 ARM。
優化控制:TMS320C2000? DSP 平臺TMS320C2000? DSP 平臺向數字控制行業提供了一系列優秀的芯片。該平臺集成了微控制器的控制外設,簡便易用并且繼承了 TI 一流 DSP 技術的處理能力和效率。TMS320C28x? DSP 系列包括具有片上閃存和高達 150MIPS 性能的 32 位控制器及引腳兼容版本的 ROM。TMS320C24x? DSP 系列提供 20-40MIPS,具有高度集成的外設(價格為 2.00 美元以下,批量)。
工具和軟件TI 有著各種可用的開發工具和軟件,它們支持快速完成基于 DSP 的應用設計過程 - 從概念到編碼/編譯,經過調試分析、調優,再到測試。許多工具都是 TI 的實時 eXpressDSP? 軟件和開發工具策略的一部分,旨在幫您快速開始。
輔助模擬產品TI 提供各種輔助數據轉換器、電源管理、放大器、接口和邏輯產品來完成您的設計。在許多組合中,這些器件旨在專門與 TI DSP 進行連接。要在
]]>
與現行廣播相比,數字音頻廣播(digital audio broadcasting,簡稱dab)這種新的傳輸系統憑借其諸多優點而引起了國際通信行業的矚目,并獲得了迅速的發展。我國廣播電影電視行業標準《30~3000mhz地面數字音頻廣播系統技術規范》自2006年6月1日起實施。 該標準是dab標準,適用于移動和固定接收機傳送高質量數字音頻節目和數據業務。
由于手機電視將為2008北京奧運提供服務,國內多家單位已積極致力于dab的研制開發。本文將介紹dab接收機的樣機設計。
系統的性能要求
歐洲dab系統規定了4種模式,本設計采用的是第1種模式,具體參數如表1所示。其中,l表示一幀的符號數,k表示每個符號的子載波個數,tf表示一幀的持續時間,tnull表示空符號持續時間,ts表示每個符號的持續時間,tu表示有效符號的持續時間,δ表示保護間隔的持續時間。

表1 第1種dab傳輸模式的具體參數
采用這一模式的設計要求為:帶寬1.536mhz,載波頻率174~240mhz,誤碼率不超過10-4。
方案原理及設計思路
1 方案原理框圖
dab接收機原理框圖如圖1所示。dab接收機將從天線接收到的信號經過高頻頭轉為中頻模擬信號,放大后進行a/d變換,得到數字信號。其中a/d采樣時鐘受晶振vcxo的控制,采樣時鐘偏移由采樣時鐘同步部分估計得到。a/d轉換后的數據一路做agc檢測去控制高頻頭的輸出,另一路經過r/c變換成fft所需要的兩路實虛部數據信號。時間同步部分估計得到一個時域符號的同步頭,并粗略地估計由于收發頻率不一致而引起的頻偏。經過fft變換后,頻率同步單元定出fft的窗口位置,校正帶有頻偏的數據。校正后的數據經過信道估計,得到當前實時的信道響應,經過信道均衡處理以消除信道多徑衰落的影響,然后再經過解映射軟判決譯碼和解擾,然后將音頻信號送入信道解碼器解碼,接著進行信源解碼和音頻綜合,最后經d/a還原成模擬音頻?

圖1 接收機原理框圖
2 方案的設計思路
dab接收機主要由數字下變頻、同步、ofdm解調和viterbi譯碼四大部分構成。
數字下變頻就是把adc輸出的中頻數字信號變為數字基帶信號,也就是在數字上實現頻譜的下搬移,主要包括希爾伯特變換、頻譜下搬移及降采樣等。
同步部分按功能包括符號定時同步、載波頻率同步和采樣時鐘頻率同步,以fft為界可以分為時域同步和頻域同步兩部分。
ofdm解調包括fft和差分解調等,經fft和差分解調后的數據再經過頻域解交織后進行qpsk解映射及量化,送給后續viterbi譯碼器進行軟判決譯碼。
對ofdm解調送來的數據提取快速信息信道(fic)數據進行解收縮、viterbi譯碼、解擾,得到復合結構信息(mci),再利用mci對主業務信道(msc)數據進行譯碼。
dab接收機硬件電路設計
1 方案結構框圖
根據對dab接收機組成部分的分析,本次設計采用fpga+dsp的設計方案,dab接收機完整的結構框圖如圖2所示。dab信號從天線接收后進入高頻頭部分,選出所需的頻率塊,然后將選出的高頻信號送入混頻器,變為中心頻率為38.912mhz、帶寬為1.536 mhz的中頻信號,中頻信號濾掉無用的頻譜部分后再經頻率變換和濾波,變為中心頻率為2.048 mhz、帶寬為1.536mhz的基帶信號。然后進入adc,采樣速率為8.192mhz,轉換成數字信號后進入fpga。fpga完成并串轉換,同步和解調, 以及vcxo所需的控制電路等。處理后的數據進入dsp,dsp外部時鐘為24.5mhz,所以dsp可進行4倍頻,工作于100mhz。dsp中完成解交織、viterbi譯碼、解擾以及音頻解碼,最后數據被送入dac,恢復出原始模擬信號,送入喇叭即可收聽。

圖2 接收機的結構框圖
2 器件的選型
器件的選型要求在滿足系統需求的情況下力爭使成本最低,功耗最小,設計方便且易于調試,所以要全面兼顧芯片的運算速度、價格、硬件資源、運算精度、功耗以及芯片的封裝形式、質量標準、供貨情況和生命周期等。綜合考慮以上幾方面因素,本次設計中adc選用tlv5535,dac選用akm4352,fpga選用ep1s40,dsp選用tms320vc5510。
tlv5535是一款性能優良的8位adc,具有35msps的采樣速率,3.3v單電源供電,典型功耗只有90mw,模擬輸入帶寬達600mhz,很適合本設計。akm4352是非常適合便攜式音頻設備的dac,帶寬20khz,采樣速率8~50khz,工作電壓為1.8~3.6v,通帶波動只有±0.06db,阻帶衰減達43db,性能非常優良。tms320vc5510是ti公司的一款高性能、低功耗dsp。它具有很高的代碼執行效率,其最高指令執行速度可達800mips,雙mac結構,可設置的指令高速緩沖存儲器容量為24kb,片上ram共160k×16b,此外還有3組多通道緩沖串行口和可編程的數字鎖相環發生器等,i/o電壓 3.3v,內核電壓1.6v。ep1s40是altera公司stratix系列fpga,具有非常高的內核性能、存儲能力、架構效率,提供了專用的功能用于時鐘管理和數字信號處理應用及差分和單端i/o標準,此外還具有片內匹配和遠程系統升級能力,功能豐富且功耗較小。ep1s40的片內資源也足以滿足本設計所需。
3 主要模塊的電路設計
adc與fpga相連,并在fpga內完成并串變換,譯碼電路也由fpga來完成。fpga與adc間的連接包括數據線和時鐘線,adc的時鐘由fpga來提供,數據線和時鐘線均與fpga的i/o引腳直接相連即可,如圖3所示。

圖3 adc與fpga連接原理圖
dsp通過異步串行口與dac連接,如圖4所示,dac輸出的模擬信號經濾波后可直接輸出語音信號。

圖4 dsp與dac連接原理圖
現今的高速dsp內存不再基于flash,而是采用存取速度更快的ram。dsp掉電后其內部ram中的程序和數據將全部丟失,所以在脫離仿真器的環境中,dsp芯片每次上電后必須自舉,將外部存儲區的執行代碼通過某種方式搬移到內部存儲區,并自動執行。常用的自舉方式有并行自舉、串行自舉、主機接口(hpi)自舉和i/o自舉。hpi自舉需要有一個主機進行干預,雖然可以通過這個主機對dsp內部工作情況進行監控,但電路復雜、成本高;串行自舉代碼加載速度慢;i/o自舉僅占用一個端口地址,代碼加載速度快,但電路復雜,成本高;并行自舉加載速度快,雖然需要占用dsp數據區的部分地址,但無須增加其他接口芯片,電路簡單。因此在ti公司的5000系列dsp中得到了廣泛應用,本次設計也是采用并行自舉。與傳統的eeprom相比,flash具有支持在線擦寫且擦寫次數多、速度快、功耗低、容量大和價格低廉等優點。目前在很多flash芯片采用3.3v單電源供電,與dsp連接時無須采用電平轉換芯片,因此電路連接簡單。在系統編程時,利用系統本身的dsp直接對外掛的flash編程,節省了編程器的費用和開發時間,使得dsp執行代碼可以在線更新。圖5為外部程序數據存儲器flash的電路連接。

圖5 外部程序數據存儲器flash的電路連接
fpga與dsp通過mcbsp、gpio、emif和ehpi口相連,接口種類多,便于根據需要靈活使用。fpga內的程序和數據掉電后也會全部丟失,所以為其配備了專用配置芯片epc16,上電后自動將程序下載到fpga中,簡單易用。
總結
為了方便調試,本次設計十分靈活,留的系統資源也比較多,不僅可以實現模式1,其他三種模式也可以在此硬件平臺上實現。用來存儲程序和數據的flash既可以用fpga來讀寫,也可以用dsp來讀寫。dsp和fpga分別配了jtag下載口用于下載程序和檢測芯片。dsp還連接rs232,用于發出控制指令以及監控dsp內部情況。fic解碼完成后可進行dab/dmb的業務選擇,依據選擇業務的不同進行不同的處理后分別產生聲音和圖像信號,并分別從喇叭或液晶顯示器輸出。
圖14.3.3給出了C54X系列DSP的內部結構。
現結合表14.2.5、圖14.3.3以及C5000系列的用戶手冊來說明該系列DSP的
特點

C54X的時鐘頻率為40/50/66/80MHz,相應的,時鐘周期為25/20/15/12.5ns,運算
能力為40/50/66/80MIPS;片上RAM在5~256千字之問,片上ROM在2~48千字之
間,隨系列內的型號不同而不同,RAM又分雙訪問RAM(DARAM)和單訪問RAM
(SARAM)。
C54X是16bit定點DSP,內部集成有以下部件:
(1)一個40bit的ALU;
(2)兩個40bit的累加器A和B;
(3)一個17×17bit的乘法器,它和一個40bit的加法器(adder)一起在一個單指令周
期內完成二進制補碼的乘法運算;
(4)桶形(barrel)移位器,其輸入連接到40bit的累加器或數據存儲器(CB,DB),
40bit的輸出連接到ALU或數據存儲器(EB),它可將輸入數據作0~31bit的左移,或作
O~16bit的右移;
(5)由COMP、TRN和TC組成的比較、選擇和存儲單元(compare,select,and store
unit,CSSU);
(6)指數編碼器(EXP),用于支持指數EXP的快速運算;
(7)8個16bit通用寄存器。
C54X采用多總線結構。內部共有8組總線,4組為程序/數據總線,4組為地址總
線。圖14.3.3中PB為程序總線,傳送從程序存儲器來的指令代碼和立即數;PAB為程
序地址總線;CB、DB、EB為三組數據總線,連接到各種器件,如CPU、數據存儲器等。
CAB、DAB、EAB是這三組數據總線對應的地址總線。CB和DB傳送從數據存儲器讀出
的數,EB傳送寫入到數據存儲器的數。Sign ctr為符號控制器。C54X利用兩個輔助寄
存器單元(ARAU0,ARAUl)在單個周期內產生兩個數據存儲器的地址。
C54X的大部分產品的I/O口的供電為3.3V,CPU核的供電也為3.3V。新近推出
的C5402、C5409、C5401的核采用1.8V供電,I/O口一般用3..3V供電。低電壓供電可
大大降低功耗。
有關C54X結構與性能的詳細內容請參看文獻[6]和E17]。
2.TMS320C55X的性能與結構特點
C55X系列是和C64X系列在2000年初同時推出的最新DSP產品。C55是建立在
C54硬件結構的基礎上的,因此也是16bit的定點DSP,同時在軟件上也和C54兼容。
C55的最大特點是在提高DSP能力的同時進一步降低了功耗。C55的功耗可低至
0.05mW/MIPS,該系列第一個產品C5510的時鐘為160MHz,運算能力為320MIPS,功
指標見表14.2.5,盡管其內核的供電也和C5402那樣為1.8V,I/O口為3.3V,但C55在
設計上(包括硬件、軟件)采取了一系列措施,其中最主要的是先進的自動電源管理技術。
該芯片的CPU對所有的外圍設備、存儲器陣列、CPU的各個單元進行連續的監視,暫時
不工作的部分則停止對其供電。
TI公司將其C5000系列DSP定位于通信領域的應用,特別是便攜式通信工具的應
用。C5402,特別是C55X的推出,對于手機、數字相機、個人數字助理(PDA)是非常適用
的。隨著生物醫學工程的發展,DSP也正在大步跨入醫療儀器行業,高性能、便攜式醫療
儀器將是C5000系列的用武之地
DMR-CP01寬帶網絡電話機
VOIP寬帶網絡電話機CP01鍵盤區設置.DOCVOIP寬帶網絡電話機宣傳彩頁1.JPG
VOIP寬帶網絡電話機宣傳彩頁2.JPG
- VOIP寬帶網絡電話機合作
- 市場保障:所在地區的唯一的OEM合作伙伴 。
- 技術支持:提供長期的技術咨詢、技術服務、軟硬件改進等。
- 提供技術資料:VOIP網絡電話機原理圖、VOIP網絡電話機PCB電路板圖、焊接VOIP網絡電話機電路板的元器件報目表。
- 提供必要的VOIP網絡電話機主控制芯片揚智CM5000的采購渠道,VOIP網絡電話機外觀紙包裝、VOIP網絡電話機說明書、VOIP網絡電話機模定制具采購渠道。
- VOIP寬帶網絡電話機中文版使用說明書.DOC
- VOIP寬帶網絡電話機英文版使用說明書.DOC
- VOIP寬帶網絡電話機中文版使用說明書.PDF
- VOIP寬帶網絡電話機英文版使用說明書.PDF
- VOIP寬帶網絡電話機合作代理協議.PDF
![]()

DMR-CN02寬帶網絡電話機
VOIP寬帶網絡電話機宣傳彩頁1.JPG
VOIP寬帶網絡電話機宣傳彩頁2.JPG
VOIP網絡電話機簡介:
VOIP網絡電話是指利用Internet打電話的接入設備。裝有終端設備的機構間通話通過Internet完成,只有上網費,沒有電話費,可為用戶節約大量的長途通訊費用,電話音質高清晰,功能豐富完備,不需與計算機連接,使通話可以在任何時候都能進行,非常適合企業辦公和家庭使用。
- VOIP網絡電話機功能特點:
- 支持SIP2.0,TCP/UDP/IP,RTP/RTCP,HTTP,ICMP,ARP/RARP,DNS,DHCP,NTP,PPPoE,TFTP等協議。
- 與國際市場上多家廠商的同類產品兼容。
- 支持各種語音編碼國際標準:G.723.1 、G.729A/B、G.728、G.726、G.711(A-law/U-law), iLBC, G.722寬頻編碼。
- 支持通話檢測(VAD),背景噪聲模擬(CNG),自動增益(AGC),和回聲抑制(G.168),支持各種加密及認證標準(BASIC, DIGEST, MD5及MD5-sess算法)。
- 支持ISO網絡結構第二層和第三層QoS (802.1Q VLAN, 802.1p, DiffServ, MPLS), 支持IETF STUN (防火墻/NAT安全穿透) 標準及市場上各種現有防火墻/NAT產品,用戶無須改動防火墻設置。
- 支持遠程全自動設備管理,有效實現用戶端“零”設置、即插即用、私網透明穿透以及軟件自動升級。可通過電話鍵盤、Web界面或相關智能網管系統方便地更改配置及升級。
- 多線同時通話,占用帶寬資源極少,只需占用一條普通寬帶便可支持16條線同時工作;如果是以路由共享器共享的形式上網,則只需占用集線器/交換機的一個端口。
- 撥打使用方便。
- 即插即用,安裝簡便,無需改變現有系統。
- 長途電話話費超低。
- 市話音質,高清晰。
- 支持PBX(程控交換機)。
- 多臺終端可疊加使用,方便擴展。
- 分機構之間可多方轉接,相互通話。
- VOIP網絡電話機系統功能:
- 電 話 簿:在電話簿中可以查找、增加或刪除電話號碼,最多可存儲 100條記錄。
- 通話記錄:顯示所有來電,顯示所有已撥號碼,刪除通話記錄、來電記錄、撥號記錄。
- 快速撥號:可設置、刪除快速撥號,使用快速撥號功能只需撥快速撥號數字 (0~9)后加“#”鍵即可,最多可設置10個速撥號碼。
- 自動撥號:在鍵區輸入電話號碼時不需輸“#”鍵,設定時間到后系統自動撥號。可將自動撥號時間設置為3~9秒鐘。
- 預 撥 號:撥號后提起話筒或按免提鍵,IP電話開始撥號。
- 切換:按“切換”鍵可由IP通話狀態切換到撥號狀態。
- 自動接聽:設定自動接聽功能,用戶可以從IP電話到PSTN電話重撥或從PSTN電話到IP電話重撥。這項功能可以在有FXO接口的IP電話上使用。
- 來電轉接:設置要轉接的電話號碼。有三種方式供選擇:所有來電轉接,占線時來電轉接,無人接聽時來電轉接。
- 反極應答:鈴聲響后啟用自動接聽功能。這項功能可以在有FXO接口的IP電話上使用。
- 拒接來電:將電話設置為拒接狀態,有拒接所有來電和一段時間內拒接所有來電可選。
- 呼叫等待:用戶不想獲知有來電時可設置呼叫等待。若通話時有新電話打入可以按“切換”鍵接入新電話,按此鍵可實現兩電話間切換。
- 日期時間:設定日期時間。
- 時間設定:可以通過設定第一或第二網絡時間服務器的IP地址來獲取日期時間信息,同樣可以根據您所在的位置設定時區和再次調整所需時間。
- 音量調整:話筒音量調整,聽筒音量調整,免提話筒音量調整。
- 鈴聲設置:鈴聲音量調整,鈴聲旋律選擇。
- 通話保留:可以按“保留”鍵使當前電話保持一段時間不掛斷,再次按“保留”鍵后繼續通話。
- 三方通話:若要進行三方通話,可先打電話給第一方,電話接通后按“切換”鍵,聽到撥號音后打電話給第二方,接通后再按“切換”鍵。
- 呼叫轉接:支持三種呼叫轉接
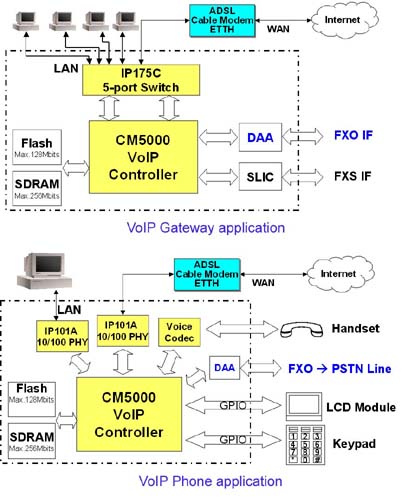
VOIP網絡電話機備注一:CM5000芯片方案
CM5000是一個高度集成的VoIP解決方案。它集成了32位RISC CPU、DSP及2個快速以太網地址。CM5000有效的起到控制VoIP網關和IP電話成本的作用。
CM5000集成的32位RISC CPU,頻率為125MHz,內建了4K字節的指示緩存及4K字節的數據緩存。它支持系統管理、網絡管理、協議棧管理及應用程序。
CM5000集成的16位Fix-Point DSP,頻率為125MHz,支持32K×24的可編程存儲器,16K×16的系數存儲器,15K×16的數據存儲器。它提供2個串行端口支持2個聲音通道。DSP支持多個聲音壓縮模式(G.711,G.723.1,G.729A,G.729B),回音消除及多種普通電話技術。
CM5000提供2個10/100M快速以太網地址支持全/半雙工模式,端口基于VLAN,MII接口和2K字節的FIFO封包緩存器。用戶能通過MII接口與外部PHY或以太網交換芯片構建VoIP網關和IP電話。
當CM5000作為IP電話芯片應用時,也提供對LCD控制、鍵區、UART串行接口和多個普通I/O接口的支持
產品介紹:
VoIP解決方案。CM5000集成了32位RISC CPU、DSP及2個快速以太網地址。CM5000能有效的起到控制VoIP網關和IP電話成本的作用。
![]()
CM5000芯片方案VOIP網絡電話機工作原理
RISC CPU
* 4Kbytes of direct mapped instruction cache
* 4Kbytes of direct mapped data cache with write-through policy
* Memory Controller:Flash/SDRAM
* 125MHz internal system clock
* JTAG support
16-bit fixed-point DSP
* Program SRAM 32K*24
* Coefficient SRAM 16K*16
* Data SRAM 15K*16
* Two Serial Port Interfaces
* DSP clock speed runs at 125MHz
Two 10/100 MACs
* IEEE802.3/802.3u compliant
* Half/Full duplex operation
* VLAN support
* MII interface to external PHY
* Scatter and gather transmit/receive DMA
* 4KB transmit/receive FIFO
隨著數字信號處理器 (DSP) 的應用范圍不斷擴大,對面向組件的軟件模塊的需求不斷增長。第三方提供的現成算法在基本層面上能夠響應上述需求。第三方算法使系統開放商不必再費力重新設計主要的軟件功能,從而能夠更快、更廉價地將系統與更多功能集成。因此,第三方算法在 DSP 系統開發中發揮著非常重要的作用。
為了使組件軟件方法順利工作,必須具備保證組件代碼互用性、一致性和便攜性的標準。DSP廠商認識到了上述需求,建立了管理不同算法與應用之間接口的算法標準。上述標準不是為了保證高效實施。針對代碼大小、特性及性能而選擇最佳算法的工作是由系統集成商進行的。而標準所作的,則是提供確保算法之間相互協作的一套規則,使他們更輕松地進行評估,然后在系統環境中進行集成。
算法標準的起源
20世紀90年代中期,算法標準的需求逐漸顯現出來,此時更為強大的 DSP 出現了,其可支持一個算法的多通道,或者同一 DSP 上的多個算法。盡管早期的 DSP 可能僅用作語音編碼器等,但像來自 TI TMS320C5000 平臺中 DSP 則能夠處理蜂窩電話所需的整個數字處理鏈,包括聲碼、音頻校正、回波消除等。諸如來自 TMS320C6000平臺的其他 DSP,則能夠開發 DSL 線卡、視頻服務器及其他在單個設備上要求具有極高多通道性能的系統。
利用現有更高層次的性能,許多新興信號處理標準不斷涌現,包括 JPEG、MPEG、電視會議、無線電話以及調制解調器與傳真改進等。開發商開始創建交互改變任務的動態系統,而不是一般基于 DSP 的具有固定功能的靜態系統。而且系統代碼規模也開始劇增,常常為了適應新型多功能系統的復雜性而大幅度增加。
DSP 系統開發商始終缺少經驗豐富且掌握深入信號處理知識的 DSP 程序員。目前,這些開發商們開始集成更為復雜的系統,一些剛剛進入 DSP 領域的其他開發商則已開始進行最初的 DSP 設計。不斷增長的業界系統集成商尋找各種方法來將日益復雜化的設備整合起來,而不必從頭設計所有軟件。幸運的是,一些具備業經驗證軟件技術的開發商認識到新的市場商機,并開始作為第三方出售其知識產權,包括算法。系統集成商將從第三方購買"黑盒子"目標代碼,并將其加載至系統中,以節省寶貴的開發時間。至少這就是假設的工作流程了。
然而,在實踐中事情并非如此直接。第三方開發商常常假定DSP用法,以便使其算法盡可能精簡,并獲得最佳性能效果。因此,一個算法可能需要占用所有內存,在很長的時間中禁用出現中斷,并完全控制核心。此外,系統集成商可能無法了解開發商的事先假定是什么,因為不存在統一的方法指定算法的資源要求與性能效果。
顯然,如果有了上述假定的話,那么兩種或多種算法就不能在多功能系統中和平共處。這樣的問題在利用源代碼進行再設計時可能相當困難,但力圖集成目標代碼的系統開發商對改變算法無能為力。而且,如果算法來自不同的第三方(事實常常如此),集成商將面臨不兼容性難題以及不可避免的相互指摘。
到20世紀90年代末為止,很明顯如果不就算法建立行為規則,那么 DSP 開發將停滯不前。因此,DSP 廠商開始發布這種規則,將其編寫為第三方軟件開發商必須遵循的標準代碼,以便保證算法的兼容性。盡管這些標準是具有所有權的,但它們都具有相同的目標,并且許多規則都是一樣的。由于某些規則反映了硬件實施,并且僅針對某些個體廠商,因此對所有權而不是業界標準進行保留。此外,當標準出現時,廠商為了跟上 DSP 的開發步伐被迫響應當時的需求,而不是將問題交給漫長的業界標準化進程來解決。
示范標準
最初建立的標準之一是 TI 的 TMS320 DSP Algorithm Standard?,也稱作XDAIS。TI 推出了該標準作為其 eXpressDSP? 軟件戰略的基本元素,并同時推出了實施內核、集成開發環境 (IDE) 及第三方網絡,這表明算法標準化將在 DSP 軟件開發中發揮關鍵性作用。TMS320 Algorithm Standard 是各種 DSP 算法標準的一個示范,事實上它成了隨后推出的某些標準的一個模型。
XDAIS 是在 TMS320 DSP 底層軟件架構基礎之上建立起來的。圖1顯示了 DSP 系統的組織方式,這樣簡單數據傳感器算法從 I/O 功能以及底層核心運行時環境中分離出來。圖2顯示了 XpressDSP 環境中算法正常運行的必備系列事件。 <!-- 圖1. XDAIS 與 DSP 系統 圖2. XDAIS 算法事件 -->
XDAIS 算法規則
XDAIS 規則分外四組,具備基本的校驗機制以保證符合標準。
常識性編程規則。本組規則的作用在于加強算法的便攜性、可預測性及易用性。由于大多數 DSP 系統運行于 C 環境中,因此頂層的算法必須能在C中調用。算法不得干擾應用程序的運行時狀態,并且代碼必須在搶占式環境中進行重入以支持多個通道。必須對多實例共享的存儲器與全局變量進行保護。所有代碼引用必須完全可再定位,不得采用硬編碼存儲器尋址,否則將干擾其他代碼。由于資源可能因系統而異,因此算法不得直接訪問外設。
取消任意選擇。如果需要以單一強制方法進行某項工作的話,該標準指定了應在各種不同方法中采用何種方法(就好像交通法規指定了在路上應左行還是右行)。為避免命名沖突,信號命名必須遵循 DSP/BIOS? 規則,這是 TMS320 DSP 采用的實時內核。為避免將代碼移植到不同操作系統環境中時發生沖突,算法必須封裝到遵循統一命名規則的檔案文件中。必須使外部引用符合來源,如C運行支持庫函數或其他符合 eXpressDSP 的模塊。算法實例必須根據指定的程序調用并刪除,并且它們必須能夠獨立地進行再定位。對 C6000? 平臺而言,算法必須至少支持由小到大的字節順序,或最好兩個都支持,以便為系統開發商提供選擇。
資源管理。由于算法一般比較貪婪,并且必須使其可以共享,因此本組位于該標準的核心。現在每個算法都有了強制的存儲器管理界面,而且所有算法都必須在設計時一次協調或在運行時交互協調使用存儲器。本規則適用于外部及內部存儲器,以及 DMA 通道等外設。本應用同控制框架一樣收集所有存儲器請求,隨后向算法分配存儲器。算法可能不能獲得其全部請求,但應用框架能夠在競爭請求間進行很好的判斷,并優化地劃分系統資源。
統一規范。本組規則有助于系統集成商衡量算法并評估其在系統中的兼容性。所有的兼容性算法必須表現最壞情況的中斷傳輸時間、典型與最壞情況的執行,以及程序、堆陣、靜態和堆棧存儲器要求等方面的特點。例如,算法供應商可能不再隱瞞會讓算法獨占內核幾秒鐘的中斷傳輸時間。現在,必須根據已確定的方式在算法技術描述中指定并包含傳輸時間要求。
校驗與 eXpressDSP 一致性。算法開發商不能簡單地說它滿足了 TMS320 Algorithm Standard 的要求。開發商必須通過 TI 的 XDAIS 一致性測試工具加以證明,該工具可校驗代碼是否符合規則。此外,第三方必須書面同意在開發算法時遵循了標準規定。當滿足了這些要求時,第三方可以聲明其算法符合 eXpressDSP,并在廣告宣傳中使用圖3所示的標志。一致性工具可適用于第三方及 DSP 客戶,以便使他們在開發自身軟件時對這些軟件進行檢查。系統集成商還可以利用該工具保證他們購買的代碼在獲得eXpressDSP一致性稱號后沒有經過修改。 <!-- 圖3. eXpressDSP 一致性標志 -->
XDAIS 的發展
XDAIS 在5年前推出時,其規則還不到30條。現在它已有了46條規則,這反映出對標準的需求不斷發展,但其發展是以認真、受控的方式進行的。新規則的添加(以及一些改動)出于以下幾點原因:
新硬件功能。添加某些規則是為了涵蓋硅技術的開發。例如,隨著將高級 DMA 功能集成到芯片中,XDAIS 也添加了新的規則以涵蓋 DMA 通道的分配。未來,XDAIS還可能包括有關硬件加速器作為共享資源使用的規則。
性能優化。為優化性能,DMA規則已進行了修訂,在此,這些規則也展示了XDAIS 標準中的另一個變化領域。由于早期規則解決了重大沖突,因此一些較新的指導方針傾向于幫助開發商更好地發揮系統優勢。
新應用領域。XDAIS的最初指導方針主要是為了處理帶有數據流應用的單功能DSP,如語音及音視頻等。但今天的多功能系統常常必須處理突發數據,如 IP 數據包或更復雜的調制解調器標準中類似框架的編碼。這些應用的核心和系統要求有時與流應用的不同,而XDAIS 規則必須包括兩種類型的數據吞吐量。
有一個沒有改變的特性,即需要將開銷保持在較低水平。經驗顯示,DSP 客戶與第三方將接受不超過一至兩個百分點的性能及存儲器干擾。這對于通用微處理器而言是一個較小的開銷百分比,該微處理器可通過中斷來驅動控制任務,并不十分受限于內存的高效利用。但是,通常每個性能MIP對DSP都是非常關鍵的,因此 TI 已努力將 XDAIS 開銷保持在限定范圍內。
算法標準的接受
盡管一直就軟件規則向第三方進行咨詢,但有些第三方最初對他們能否從算法標準中獲益是抱有懷疑態度的。許多第三方將算法的開發看作完全是其自身的業務,不歡迎 DSP 廠商參與,認為這是一種干擾。此外,為了使算法符合新的標準,一些重復工作是不可避免的,而第三方則反對承擔他們認為是不必要負擔的工作。而且,對與標準相關的開銷懲罰也有反對的聲音。
與第三方形成對比的是,DSP 系統集成商幾乎立即對標準表示歡迎。一些較大型DSP 開發商已經在努力建立其自身規則,而 DSP 標準的到來節省了他們的工作。系統集成商還認識到,與算法標準相關的少量開銷能幫助他們避免大量時間耗費與麻煩,這種節約的價值大大超過了他們所必須接受的存儲器與性能權衡。
一旦他們熟悉了這些標準,DSP 系統集成商就開始要求算法一致性,這樣即便是最不情愿的第三方也不得不遵照行事。為了應付對額外開發工作的反對意見,出現了幫助第三方開發一致性算法的工具,圖4所示的 Hyperception Component Wizard 便是其中一個實例,它可幫助創建 XDAIS 算法。 <!-- 圖4. Hyperception Component Wizard -->
今天,標準已得到普遍接受,即便最不情愿的算法開發商也認同標準化使得出售軟件的商機大大增加。根據標準進行設計還意味著能夠最小化支持需求,從而節省第三方的開支。TMS320 Algorithm Standard 就是體現標準有多么成功的一個代表:目前,符合 eXpressDSP 算法的第三方開發商達110個,且數量還在不斷增加。其他 DSP 廠商也認識到算法標準的需求,并為其各自的平臺和第三方算法提供了相似的產品。由于標準涵蓋了可互操作性編程的基本問題,因此其規則在許多方面都與最初推出的標準 TMS320 Algorithm Standard 相似。
新興產業
事實上,DSP 算法標準帶來了一種前所未有的國際產業。今天,某個地區的系統集成商可以通過網站從另一個地區的第三方處購買 DSP 算法,只要該算法通過認證,符合算法標準,那么該系統開發商就知道此代碼在應用框架中可正常發揮作用。對 DSP 系統集成商而言,一致性算法已簡化了對第三方目標代碼進行評估并集成的工作,從而簡化了開發進程并縮短了產品上市時間 。
由于我們最終控制了算法,現在業界中存在的問題就在于對其他軟件組件(如庫、驅動程序、內核以及通訊棧等)進行標準化會帶來什么優勢。DSP 廠商甚至在改進現有算法標準的同時,就已經在考慮有關對上述組件的標準化工作進行擴展的問題了。
隨著 DSP 產業繼續圍繞著組件軟件模型進行開發,算法標準的價值正變得越來越明顯。標準提供了一系列規則,根據設計,實際上這些規則能夠保證組件在任何應用中與來自不同廠商的算法實現進行互操作。因此,代碼的便攜性與可重復使用性得到加強,而算法的衡量與評估更為直接,并且算法也更易于集成到系統之中。總體系統開發變得更快、更靈活,從而為市場中的最終用戶帶來了更健碩、更廉價的產品。
關鍵詞:Bluetooth
嵌入式系統
DSP
協議藍牙(Bluetooth)協議標準是由藍牙特別興趣小組(Bluetooth
SIG)發布的,1999年發布了Bluetooth
1.0版,2001年2月發布了Bluetooth1.1版。目前SIG成員已經發展到3000家左右。藍牙協議規定的無線通信標準,基于免申請的2.4GHz的ISM頻段,采用GFSK跳頻技術和時分雙工(TDD)技術,通信距離為10米左右,Blue
tooth
1.0版標準規定的數據傳輸速率為1Mbps。主要適用于各種短距離的無線設備互連應用場合。可以提供點到點或點到多點的無線連接。1
基于電纜替代的藍牙協議簡析1.1
藍牙協議體系藍牙協議規范所措述的協議棧模式如圖1所示。藍牙體系結構中的協議可分為四層:核心協議:基帶控制協議(Baseband)、鏈路管理協議(LMP)、邏輯鏈路控制應用協議(L2CAP)、服務發現協議(SDP);
電纜替代協議:RFCOMM;電話傳送控制協議:TCS二進制、AT命令集;可選協議:PPP、UDP/TCP/IP、OBEX、WAP、vCard、vCal、IrMC、WAE。在協議中,規定了為基帶控制器、LMP、硬件狀態及控制寄存器提供命令接口的主機控制器接口(HCI)。在不同的應用模式下,HCI所處的位置不同。它可以位于L2CAP的下面,也可以在L2CAP之上。1.2
電纜替代協議應用模式基于ETSI標準的TS07.10信令的RFCOMM協議,提供了一個基于L2CAP協議之上的串口仿真應用模式。藍牙協議1.0版中,RFCOMM提供的上層服務模式主要有三種:對9針RS-232接口仿真模式、空Modem仿真模式和多串口仿真模式。典型的RFCOMM應用模式框圖如圖2所示。
1.3
藍牙嵌入式應用模式僅僅以RFCOMM協議為基礎,作為串口的電纜替代應用,無形中限制了藍牙設備的應用范圍,降低了藍牙設備的應用價值。目前計算機與外部設備的接口種類繁多,比較常見的有RS-232、RS-485、Parallel
Port、CAN總線、SPI總線、I2C總線等。如果要使藍牙設備在各種場合發揮作用,必須使藍牙設備具備適合這些應用場合的多種接口功能。使用DSP數字信號處理器作為嵌入式控制器,不僅實現藍牙物理設備的初始化、藍牙高層協議,而且利用其接口靈活的特點,可以方便地對藍牙電纜替代協議進行有效擴展。具體應用模式如圖3所示。2
系統硬件結構本系統的構成在硬件上分為兩個部分,藍牙基帶和射頻部分采用愛立信(ERICSSON)公司提供的藍牙模塊ROK101007;嵌入式控制器采用美國TI公司的TMS320VC54X系列的DSP數字信號處理器。
2.1
ERICSSON藍牙模塊ROK101007是根據藍牙規范1.0版(Bluetooth
1.0B
Version)而設計的短距離藍牙通信模塊,它包括三個主上部分:基帶控制芯片、Flash存儲器和Radio芯片。它工作在2.4GHz~2.5GHz的ISM頻段,支持聲音和數據的傳輸,其主上功能參數有:Bluetooth
1.0B預認證;2級RF射頻功率輸出;提供FCC和ETSI糾錯處理;最大460
KB/s
UART數據傳輸速率;提供UART、USB、PCM、I2C等多種HCI接口;提供內部晶振;內部預制HCI框架;點到點、點到多點操作;嵌入式屏蔽保護。
ROK101007特別適合計算機及外圍設備、手持設備、端口設備使用。其內含的藍牙協議構架及內部系統框圖如圖4、圖5所示。2.2
DSP處理器TMS320C54X是16-bit定點DSP,適合無線通信等實時嵌入式應用的需要。C54x使用了改進的哈佛結構。CPU具有專用硬件算術運算邏輯,大量的片內存儲器、增強的片內外設以及高度專業化的指令集,使其具有高度的操作靈活性和運行速度。主要特點如下:運算速度快:指令周期為25/20/15/12.5/10ns,運算能力為40/50/66/80/100MIPS;優化的CPU結構:內含1個40位的算術運算邏輯單元,2個40位的累加器,2個40位的加法器,1個17×17的硬件乘法器和1個40位的桶形移位器。有4條內部總線和2個地址產生器等。先進的CPU優化結構可以使DSP高效地實現無線通信系統中的各種功能。
低功耗方式:54x系列DSP可以在3.3V或2.7V電壓下工作,而有些DSP內核采用1.8V電壓工作以減小功耗。智能外設:除了標準的串行口和分時復用(TDM)串口外,54x還提供了多路緩沖串口(McBSP)和外部處理器通信的HPI并行接口。2.3
系統構成本系統中,采用單5V電源供電,嵌入式系統控制器與藍牙模塊之間的HCI接口采用UART方式。硬件構成框圖如圖6所示。整個系統分為四個部分:發射機、嵌入式控制器、電源管理、接口邏輯。(1)發射機由藍牙模塊ROK101007和阻抗為50Ω的天線構成。初始化階段,模塊接收控制器通過UART發送的HCI命令,實現藍牙設備的復位、啟動、地址查詢、跳頻算法、自動尋呼等初始化操作,與附近的藍牙設備建立可靠的物理鏈路,并對物理鏈路進行相應的加密。在數據傳送階段,接收控制器(HCI驅動模塊)送來的HCI數據包,經過模塊中HCI固件(HCI
Firmwire)轉化為基帶數據包并送給基帶協議層(Baseband)處理,基帶對上層送來的數據進行解碼,將其變為可以發送的位數據流,按照設定的跳頻算法,采用高斯頻移鍵控(GFSK)編碼方式通過天線送出去。接收數據時,以相反的過程將接收到的數據進行編碼,組合成HCI數據包格式并通過UART口送給控制器。具體的收發執行過程可以參考ROK101007數據及應用手冊以及藍牙協議相關部分。(2)嵌入式控制器由TI的定點數字信號處理器TMS320C54x、Flash
Memory、SRAM組成,完成對藍牙模塊的初始化、數據傳送、協議實現等功能。
(3)接口控制邏輯包括應用接口和控制接口。控制接口為控制器的HPI接口,主要實現系統的在線特殊控制和Flash在線編程數據傳送口。HPI控制接口通過DSP的HPI主機接口實現。應用接口包括RS-232/RS-485串行接口邏輯、并行接口邏輯(如IEEE488總線)、SI同步串口邏輯,在不同的嵌入式應用中,分別通過不同的接口形式實現本嵌入式系統與主設備控制器的接口。應用接口通過DSP的片內外設(enhanced
peripherals)或者通用I/O端口模擬實現。(4)電源管理。系統通過單5V電源供電,可以簡單地從主設備接口中獲取電源,無須另加電源器件。電源管理模塊采用TI專用電路,提供兩路電壓輸出,+3.3V工作電壓和+1.8V控制器內核工作電壓。3
系統軟件設計系統采用TI提供的DSP5000系列專用集成開發工具CCS1.2開發。系統軟件構成包括應用端口通信及協議模塊、L2CAP協議模塊、HCI接口驅動模塊、HPI通信模塊和Flash編程模塊。主要任務可分為:系統初始化、Flash編程、建立物理鏈路、數據傳送和接收等。整個軟件流程如圖7。由于藍牙模塊本身具有線路加密功能,因此在本系統設計中沒有考慮軟件加密功能。在實際的設計和應用過程中,可以視其實際應用環境和系統處理速度而添加軟件加密模塊。由于跳頻通信本身具有高抗干擾性的特點,本嵌入式藍牙應用系統不僅可以應用于各種終端設備和手持設備間的中低速無線數據交換,而且可廣泛地應用于各種工業設備、軍事裝備的檢測和控制領域。]]>
幾年對DSP的開發寫一寫自己的感受,一家之言,歡迎指教。我上研究生的第一天起根據
老板的安排就開始接觸DSP,那時DSP開發在國內高校剛剛開始,一臺DSP開發器接近一萬
還是ISA總線的,我從206開始240、2407A都作過產品,對5402、2812、5471在產品方案
規劃制定和論證時也研究過。由于方向所限對6X、8X系列沒有接觸。
我發現在國內無論在公司或高校許多地方為了加快開發周期往往把一個產品開發分為硬
件和軟件兩個相對獨立部分,由不同的人完成。這在具有一定技術和管理基礎的公司,
由總設計師統一規劃協調,分任務并行完成的情況下是可行的,也是符合現代產品開發
規律的。但是在高校人員的流動很大,研究生的有效科研時間很短、基礎差(許多研究
生起步時對電熔、電阻、三極管的分類和選型都很困難,我也是這樣過來的)更不用說
系統規劃設計了,況且許多老板自己也不太懂,師兄有自己的任務,他們搞明白時也畢
業了。在許多高校做DSP就是找一個算法加到自己的主程序里,在板子上跑一下,基本達
到效果就可以了,至于可靠性是次要的,產業化無從談起,這已經算不錯的了。
其實我覺得一個系統的完成,系統的規劃是最重要的,在規劃時對硬件設計的知識和認
識是決定性的,它可以讓你知道什么是可行的,什么是不可行的,當你同時具有軟件設
計能力時,就可以合理的分配系統功能,完成使用VHDL進行系統行為描述-—系統功能
劃分—— 系統子結構設計這樣的自頂向下的設計規劃流程,成為系統設計專家、項目經
理,否則只是硬件工程師、軟件工程師。無論作51、196、還是DSP都是這樣。
下面分別談談我對硬件和軟件設計的感受
硬件設計是系統設計的關鍵,國內和國外產品的差距往往是硬件設計水平高低決定的,
任何軟件設計思想沒有可靠的物理載體都是空中樓閣,紙上談兵。學校的研究生很多都
想避開硬件設計,對于一個全新的設計與其說不屑不如說不敢。試想一下燒幾個片子的
壓力要比跑飛幾段程序的壓力大的多,尤其是功率器件,一旦燒掉,弄不好火光沖天,
人的自信都沒了。況且改一次板周期長,經費高,還不知行不行。其實在國外實力一般
的公司也是盡量避免硬件的更新設計,產品一旦定型往往通過軟件升級,這是公司的發
展策略,對個人而言物以希為貴,培養一個硬件設計師往往要比軟件設計師時間長花費
多。在設計dsp硬件時,開始設計最小系統板,系統按功能分板設計調試,注意分板電路
的穩定性可能不如整板電路,要多加入抗干擾環節,分板間的引線包括電源線地線要短
,盡量在10公分以內,實在不行加入光耦隔離、采用隔離電源。切記電源線、地線的干
擾遠比信號干擾對系統的危害大得多,又常常被人忽視。電路板工作正常的先決條件就
是電源正常!當分板電路正常后再更居情況設計整板電路。在調試時發現的問題一定要
找到原因解決,即使是飛線,割線,不要寄希望于下一板改了再看,除非原理性錯誤。
每一個功能環節多準備幾套方案。DSP的選型要根據系統功能而定,2000是一個功能比較
全的控制器,但運算性能相對低,但目前大部分控制類、家電類包括中低層次的工業總
線通信產品足夠了,281X不錯但太貴,而且開發技術不成熟。54XX更像一個協處理器,
其實高端產品5471就很好,功能完*,但BGA封裝對產品的開發有一定難度。如果沒有從
事過嵌入式系統開發的朋友其實可以從51看起,許多思想是共通的,51很經典沒有哪一
款微處理器像51那樣使用持久和普遍。在硬件設計時更多的精力放在外圍電路設計上,
外圍電路設計的靈活性要比DSP本身高得多,難度大得多。建議多考慮CPLD。
軟件設計上,著眼點不要僅局限于某種算法和控制策略,而是軟件系統框架的制定,即
操作系統的選擇和實現,算法和控制策略只是其中技巧性很強的子程序和子程序間參數
相互關系,建議設計軟件時能具有操作系統、數據結構和編譯原理方面的知識,特別是
使用C。對DSP的內部硬件結構一定要掌握,特別是中斷結構和流程、流水線操作,不然
飛都不知道怎么飛的。在語言選擇上我當時是這么給自己規定的先編20個左右的匯編程
序,每個代碼量超過4K,使用語句范圍覆蓋全部語句的60%-70%,在此基礎上使用C。
現在發現用C構建程序的主體框架(操作系統)比較快而其不容易出錯,(我現在正在用
ASM根據UCOSII的思想重寫自己的操作系統)但對系統實時性影響比較大的運算算法一般
采用MATLAB——C——ASM的辦法仿真調試優化,這里的優化不單單是利用優化器優化,
而是根據數據的特點改變運算方法,以除法為例C里的/號其實掩蓋了許多技巧,當除數
為常數時就可以放大倒數移位相乘移位的辦法進行,精度高速度快。這些辦法只有掌握
了ASM語言并用ASM語言思考才會熟練應用。另外我想告訴一些作算法特別是控制算法的
朋友,千萬不要隨意評判一個算法的優劣,在程序中程序和代碼優化的程度往往影響了
控制效果好壞,而不是算法本身的思想。其實在實際中往往PID甚至PI、PD就夠了,神經
元、模糊、小波適用于研究和寫論文,模糊在實際中用的多一點,主要是小日本用的比
較成熟,我再恨日本人,這點也服氣,小日本就是滑,許多物理現象搞不透,就用這法
,還管用,題外話。
最后我想說的是,當我們面對市場要求時,產品往往考慮的是可靠性、性能、價格而不
是你用的什么芯片,在滿足性能的基礎上結構越簡單就越可靠,芯片越通用價格就越低
,能用51就不用196,能用2407就不用2812,除非把芯片本身作買點利用高成本贏取高利
潤。無論2000還是5000、6000系列都有市場前景,關鍵是要做深做透
獲取知識的方法、處理項目的能力是相通的,具體的說就是不要把目光盯在做硬件還是
做軟件上,用ASM還是C,要勤動手打好基礎,提高自己對系統總體設計的能力,從系統
的眼光看問題。為什么都是做DSP的有的畢業拿3000,有的5000、8000,除了運氣和關系
外,重要的是你對事物的認識深度和高度。我一直都記住這句話:有前途的人做什么都
有前途,沒前途的人做什么都沒前途。
二. 與其說是鉆在里面,畢業設計是搞240,在老師的壓力做出了一點東西,這期間主要
是對DSP的各種基礎知識的熟悉與理解,對DSP的真正深入是在公司工作以后。當初進公
司,因為正有一個項目需要用5410要我接手。說實話,在學校期間我5000的書都沒有看
過一眼,可沒辦法,只能靠自己了。不過好的是我2000DSP的基礎很好。接過項目后,我
第一個星期就全部看的是5000的指令,DSP的結構倒沒怎么看,因為項目硬件已成型,主
要是算法。這樣,花了一個星期熟悉指令與項目相關的程序,第二個星期也就開始編程
了。半個月以后我對5410也就用很熟了的,當然主要還是講在算法方面。這個項目太概
做了四個月吧,系統程序是我編寫的,主要有如64位加減乘除乘方開方、及時域方面的
一些算法。現在又做一個控制系統,用2407開發的,硬件主要有直交變頻,并把2407的
所有外設資源全部用到了。現在我可以這樣自夸一句吧:TI的2000系列與5000系列的我
都熟悉,要我去以此做個系統,沒問題。上面是把我搞DSP的經歷簡單說了一下的吧,在
這里我想對正在學及想學DSP的難兄們說一句的是,DSP并不是很難。當然,這個前提是
你的基礎要好,我單片機,接口都還行,當初就是從單片機改成DSP的。有了單片機的基
礎再去學2000第列的DSP(下面的DSP單指2000系列,另有說明為止),你就可以把DSP看
成一個super microcontroller了。相比之下,DSP除了比單片機多了更豐的外設接口(
SPI,SCI、CAN、PWM、CAP、QEP等等),他就是一塊單片機,只不過在單片機來說你要另
加芯片的工作,DSP全部把它做在一塊芯片去了,我現在看DSP也真就這么簡單。前面有
人提到DSP主要是做算法,這句話有一定的片面性: TI有很多系列的DSP,現在主流的D
SP主要為2000系列、3000系列、4000系列、5000系列、6000系列。除了2000與5000系列
是定點DSP外,其余的均為浮點系列。 TI的2000系列主要長處是在用于控制系統,因為
它的資源非常豐富,前面提到,在控制系統中用到的一些外設2000系列均在片內集成了
。 TI的5000系列主要長處是用于數字信號的算法處理,這里所講算法處理主要是指在數
字信號處理時的一些算法,如FIR、IIR、FFT等等。5000系列的DSP的速度比2000快,24
07最快只能到40M,2800系列除外,5410的DSP可以達到160M,如現在我們主要用來做數
字信號方面的處理以及簡單的靜態圖像處理等這樣一些在資源需要處于中等的一些算法
。 TI的6000系列主要是用在實時圖像處理,這個就更則重于算法處理。一般的硬件很少
自制,我們是用TI的DSK板再加上自主板相結合。
三. 使用C/C++語言編寫基于DSP程序的注意事項 1、 不影響執行速度的情況下,可以使
用c或c/c++語言提供的函數庫,也可以自己設計函數,這樣更易于使用“裁縫師”優化
處理,例如:進行絕對值運算,可以調用fabs()或abs()函數,也可以使用if...else..
.判斷語句來替代。 2、 要非常謹慎地使用局部變量,根據自己項目開發的需要,應盡
可能多地使用全局變量和靜態變量。 3、 一定要非常重視中斷向量表的問題,很多朋友
對中斷向量表的調用方式不清楚。其實中斷向量表中的中斷名是任意取定的,dsp是不認
名字的,它只認地址!!中斷向量表要重新定位。這一點很重要。 4、 要明確dsp軟件
開發的第一步是對可用存儲空間的分析,存儲空間分配好壞關系到一個dsp程序員的水平
。對于dsp,我們有兩種名稱的存儲空間,一種是物理空間,另一種是映射空間。物理空
間是dsp上可以存放數據和程序的實際空間(包括外部存儲器),我們的數據和程序最終
放到物理空間上,但我們并不能直接訪問它們。我們要訪問物理空間,必須借助于映射
空間才行!!但是映射空間本身是個“虛”空間,是個不存在的空間。所以,往往是映
射空間遠遠大于實際的物理空間,有些映射空間,如io映射空間,它本身還代表了一種
接口。只有那些物理空間映射到的映射空間才是我們真正可訪問(讀或寫)的存儲空間
。 5、 盡可能地減少除法運算,而盡可能多地使用乘法和加法運算代替。 6、 如果ti
公司或第三方軟件合作商提供了dsplib或其他的合法子程序庫供調用,應盡可能地調用
使用。這些子程序均使用用匯編寫成,更為重要之處是通過了tms320算法標準測試。而
且,常用的數字信號處理算法均有包括!! 7、 盡可能地采用內聯函數!!而不用一般
的函數!!可以提高代碼的集成度。 8、 編程風格力求簡煉!!盡可能用c語言而不用
c++語言。我個人感到雖然c++終代碼長了一些,好象對執行速度沒有影響。 9、 因為在
c5000中double型和float型均占有2個字,所以都可以使用,而且,可以直接將int型賦
給float型或double型,但,盡可能地多使用int數據類型代替!這一點需要注意!! 1
0、 程序最后至少要加上一個空行,編譯器當這個空行為結尾提示符。 11、 大膽使用
位運算符,非常好用!! 12、 2003年6月份從ti的網站上下到了關于tms320c67x系列d
sp的快速算法庫,于是,tms320c5000和c6000全系列的快速算法庫都問世了,這些算法
庫均可供c/c++語言直接調用,優化程度100%,實際編程時盡可能地使用(下載時可以同
時下載到說明文檔和ascii源程序,可以根據自己需要作出修改,修改前最好做個備份)
1 DSP的發展歷程
在數字信號處理技術發展的初期(上世紀50~60年代),人們只能在微處理器上完成數字信號的處理。一般認為,世界上第一個單片DSP芯片是1978年AMI公司發布的S2811。1980年,日本NEC公司推出的D7720是第一個具有硬件乘法器的商用DSP芯片,從而被認為是第一塊單片DSP器件。
隨著大規模集成電路技術的發展,1982年美國德州儀器公司柜櫥世界上第一代DSP芯片TMS32010及其系列產品,標志著實時數字信號處理領域的重大突破。TI公司隨后推出了第二代DSP芯片TMS32020及其系列,至今,TI公司已經推出了其第六代DSP芯片TMS320C62X/C67X、TMS320C64X等芯片。
美國Analog Device公司在DSP芯片市場也有一定的份額,推出了一系列具有自己特色的DSP芯片,如其定點的DSP芯片ADSP2101/2103/2105,ADSP2111/2115,ADSP2161/62/64,浮點DSP有ADSP21000/020、ADSP21060/21062等。
20世紀80年代以來,DSP芯片得到了突飛猛進的發展,從運算速度來看,MAC(一次乘加運算)時間已經從80年代初期的400 ns降到了10 ns以下(如TI公司的TMS32054X、TMS320C62X/67X等),處理能力提高了幾十倍。DSP芯片的引腳數量從1980年的64個增加到現在的200個以上,引腳數量的增加也加強了結構的靈活性[1>。
2 DSP系統和芯片的基本結構
2.1 DSP系統的基本結構
系統所需要處理的信號一般為自然條件下的模擬信號,這就需要首先將輸入的信號轉換為數字的電信號。這就需要A/D(模數轉換)模塊,A/D模塊將模擬信號轉換為數字的比特流,輸入給DSP系統,DSP系統對數字信號進行某種處理之后,一般還需要輸出為模擬信號來供人們使用,所以又用到了D/A(數模轉換)模塊,將處理后的數字信號轉換為模擬值。整個系統的構成如圖1所示。

數字信號處理結構穩定性好,可重復性好,可以大規模集成,使得信號處理功能更復雜,手段更靈活,精度更高。
2.2 DSP芯片的結構特點[2>
DSP處理芯片,為了適應信號處理運算的需要,結構與通用的其他計算機或控制處理器相比,有較大的不同,主要的幾點為:
(1)具有專用的算術單元,如硬件乘法器,DSP內部設有硬件乘法器來完成乘法操作,以提高乘法速度。
(2)具有特殊的總線結構——哈佛結構。這種結構使DSP具有獨立的地址總線和數據總線,可以同時取地址和操作數。
(3)流水處理。流水技術使多個不同的操作可以同時執行,處理器內將每條指令的執行分為取址、解碼、執行等階段,不同的階段并行執行,提高了程序執行的效率和速度。
(4)高速的片內存儲器。DSP芯片一般內部集成有程序和數據存儲器,訪問速度快,緩解總線接口的壓力,提高程序執行的速度。
一些其他特殊功能的DSP芯片還具有一些專用的設計結構,這里不一一列出。總之,DSP功能上的特點很大程度上是針對數字信號處理算法的特點,針對性地組成專用的結構,以滿足處理的需要。
3 DSP芯片的產品和市場
3.1 應用領域和市場
在近20多年的時間里,DSP芯片的應用已經從軍事、航空航天領域擴大到信號處理、通信、雷達、消費等許多領域。主要應用有:信號處理、通信、語音、圖像、軍事、儀器儀表、自動控制、醫療、家用電器等。
DSP主要應用市場為3C(communication、computer、consumer——通信、計算機、消費類)領域,所占市場比例超過90%,并且總體市場規模在不斷擴大。在數字化、個人化和網絡化的推動下,預計未來的年均增長率高達40%。在全球的DSP市場中,TI公司獨占鰲頭,占世界市場的45%份額,其次是朗訊(28%)、ADI(12%)、摩托羅拉(12%)、其他公司(3%) [3> 。
3.2 世界主要的DSP芯片制造公司及其產品
(1)TI公司。
TI(Texas Instruments)公司在業界一直處于領先的地位。近年,TI在原來的TMS320C1X、TMS320C25、TMS320C3X/4X、TMS320C5X、TMS320C8X的基礎上又推出了3種高性價比的DSP系列:TMS320C2000、TMS320C5000和TMS320C6000系列。這3種芯片,在我國的信號處理硬件領域應用也是非常廣泛,下面作些簡要介紹:
TMS320C2000系列主要用于工業控制領域,提供了全系列的高性能控制芯片,代碼運行效率高。除了較強的控制功能之外,還提供了方便的接口與高性能外圍器件相連。主要型號有TMS320C24X和28X系列。
TMS320C5000系列為高性能的低功耗定點DSP芯片。處理速度最高可以達到900 MIPS,功耗很低,可以達到0.33 mA/MHz。非常適合移動和手持系統的應用。主要有TMS320C54X和55X系列。
TMS320C6000系列為新一代高性價比DSP芯片,是高端DSP處理器的代表。C6000系列的DSP定點運算可以達到1200到8 000 MIPS(百萬條指令/秒),浮點運算可以達到600到 1 800 MFLOPS(百萬次浮點操作/秒)的運算速度。主要有定點系列的TMS320C62X和浮點系列的TMS320C67X。TMS320C64X為TI最新推出的高性能定點DSP處理器,時鐘速度提高到1 GHz,單片處理能力可達到8 000 MIPS。
(2)Analog Device公司。
ADI公司的DSP目前主要分為3個系列:SHARC、Blackfin、TigerSHARC。
SHARC系列一直在雷達、聲納信號處理等領域享有很高的聲譽,很多商用、軍用的信號處理機中都可以看到SHARC的身影。單片處理能力有限的SHARC之所以能夠在通信信號處理領域有這么高的聲譽,完全是由于ADI優秀的片間互連技術(LINK口),利用這個LINK口可以很方便地將幾片、幾十片SHARC連接起來組成DSP陣列,從而在單片處理能力達不到要求的場所利用DSP陣列就很容易達到了。
Blackfin是近幾年推出的針對性能要求比較高,同時功耗要求又比較低的場所。它所具備的優點很適合在便攜式通信產品中應用。
TigerSHARC是從SHARC改進的高端DSP,它的出現是ADI公司的DSP在高端領域應用開創了歷史性的局面。新推出的第二代TigerSHARC ADSP-TS201S主頻高達600 MHz,處理能力高達14.4 GOPS,還有超大容量的RAM,使它一出世就在高端領域脫穎而出。尤其適合軟件無線電的應用。
DSP已經發展成為了一種成熟的技術,也是一種成熟的產品,它在數字信息時代占據越來越重要的位置,所以其市場的擴展還存在著巨大的空間。DSP的性能、價格和功耗是決定其市場的三個重要因素。挑戰更高的性能,盡可能降低價格和功耗,一直是DSP追求的目標。
4 DSP處理系統的發展現狀
4.1 國際發展現狀
簡略國際DSP處理發展的現狀,國外的商業化信號處理設備一直保持著快速的發展勢頭。歐美等科技大國保持著國際領先的地位。例如美國DSP research公司,Pentek公司,Motorola公司,加拿大Dy4公司等,他們很多已經發展到相當大的規模,競爭也愈發激烈。我們從國際知名DSP技術公司發布的產品中就可以了解一些當今世界先進的數字信號處理系統的情況。
以Pentek公司一款處理板4293為例,使用8片TI公司 300 MHz的TMS320C6203芯片,具有19 200 MIPS的處理能力,同時集成了8片32 MB的SDRAM,數據吞吐600 MB/s。該公司另一款處理板4294集成了4片Motorola MPC7410 G4 PowerPC處理器,工作頻率400/500 MHz,兩級緩存256K×64 bit,最高具有16MB的SDRAM。
ADI公司的TigerSHARC芯片也由于其出色的協同工作能力,可以組成強大的處理器陣列,在諸多領域(特別是軍事領域)獲得了廣泛的應用。以英國Transtech DSP公司的TP-P36N為例,它由4~8片TS101b(TigerSharc)芯片構成,時鐘 250 MHz,具有6~12 GFLOPS的處理能力。
DSP應用產品獲得成功的一個標志就是進入產業化。在以往的20年中,這一進程在不斷重復進行,而且周期在不斷縮小。在數字信息時代,更多的新技術和新產品需要快速地推上市場,因此,DSP的產業化進程還是需要加速進行。隨著競爭的加劇,DSP生產商隨時調整發展規劃,以全面的市場規劃和完善的解決方案,加上新的開發歷年,不斷深化產業化進程。
4.2 我國發展現狀
隨著我國信息產業的發展,近年來我國的數字信號處理學科發展較快。DSP處理器已經在我國的數字通信、信號處理、雷達、電子對抗、圖像處理等方面得到了廣泛的應用,為科學技術和國民經濟建設創造了很大價值。全國有很多高校、科研機構的信號處理實驗室都在大力研究性能更高的數字信號處理設備,取得了很多研究成果。我國的科研人員通過對先進的DSP芯片的研究,已經研制出一些高性能處理設備的解決方案,并且在板級PCB設計方面,也取得了寶貴的設計經驗。
以我國某電子技術研究所研制的DSP雷達數字信號處理通用模塊為例,它使用了6片ADSP21060和大規模可編程器件構成通用處理模塊。通過信號處理算法并行設計、系統多數據流設計、處理任務分配調度程序設計,實現高速實時雷達數字信號處理 [4> 。以FFT算法為例,將任務分為3個流水處理過程:FFT、復數乘法、IFFT,實現多片DSP組成并行處理。在33 MHz時鐘下,1 024點處理通過時間為0.7 ms,可以實現單通道數據率為1 MHz,雙通道并行工作為2 MHz。
國內的某大學所研制的基于TMS320C6201的高速實時數字信號處理平臺,實現基-2的復數FFT,允許輸入數據的動態范圍16-bit,可以實現59 μs內完成512點的FFT,130 μs內可以完成1 024點的FFT。
但是,應該看到,我國在信號處理理論、高速高性能處理器設計和制造方面與國際先進水平還有較大差距。而且,主要的核心處理器件基本完全依賴進口,這也是我國半導體研究領域需要大力加強的工作之一。復雜的大型處理機PCB板級設計和制造也存在一定困難,也是需要我國科研人員發揚勇于拼搏的精神,繼續的刻苦努力。
5 DSP技術展望
5.1 向著集成DSP方向發展
目前的DSP多數基于RISC(精簡指令集)結構,這種結構的優點是尺寸小、功耗低、性能高。現在各DSP廠紛紛采用新工藝,將幾個DSP核、MPU核、專用處理單元、外圍電路單元和存儲單元集成在一個芯片上,成為DSP系統級集成電路。
5.2 內核結構進一步改善
多通道結構和單指令多重數據(SIMD)、超長指令字結構(VLIM)、超標量結構、超流水結構、多處理、多線程及可并行擴展的超級哈佛結構在高性能處理器將占據主導地位。
5.3 進一步降低功耗和幾何尺寸
DSP的應用范圍已經擴大到人們工作生活的各個領域,特別是便攜式手持產品對于低功耗和尺寸的要求很高,所以DSP有待于進一步降低功耗。隨著CMOS的發展,提高DSP的運算速度和降低功耗尺寸是完全可能的。
5.4 與可編程器件結合
DSP在許多新的領域的應用要求它借助PLD或FPGA來滿足日益增長的處理要求。與常規DSP器件相比,FPGA器件配合傳統DSP器件可以處理更多的信道,來滿足無線通信、多媒體等領域的多功能和高性能的需要。
1 TI DSP Library簡介
1.1 TI DSP Library的特點
DSP Lib的核心實際上是一系列經過手工優化的匯編程序代碼,這些代碼封裝在后綴名為.lib的文件中,可用于完成各種運算。它們對外是不可見的。這些程序(庫函數,routines)可被C程序調用。由于經過了手工優化,它們的效率都非常高。由于不同系列DSP芯片的指令集不同,因此,不同系列DSP芯片的DSP Lib也是不同的,如TMS320C5000的DSP LIb就不能用于TMS320C6000。但是,各個系列DSP Lib的基本組成是相同的,一個完整的DSP Lib通常由Lib文件夾、include文件夾和其它輔助文件組成。其中lib文件夾用于存放*.lib文件,其內部封裝著手工優化的匯編程序代碼,是一個DSP Lib的核心部分。有的DSP Lib還有*.src文件,這些*.src文件主要是用C語言和匯編語言編寫的程序源代碼。使用歸檔器可從中提取出這些源代碼;而include文件夾用于存放各個庫函數的頭文件,通常這些文件分為C程序頭文件和匯編程序頭文件兩部分。
1.2 TI DSP Library的下載和安裝
由于DSP Lib種類繁多,且屬可選模塊,通常的DSP開發環境(CCS,Code Composer Studio)并沒有配備DSP Lib。因此,使用一個DSP Lib之前,必須進行DSP Lib的下載和安裝。
所謂下載,就是在TI公司網站WWW.ti.com上免費下載各種DSP Lib;而所謂安裝,就是在DSP Lib下載完畢后,雙擊安裝文件,以將它安裝在計算機中選定的位置(默認位置為C:\ti)。安裝之后,即可在程序開發中使用DSP Lib的庫函數。
1.3 TI DSP Library的使用
按處理數據類型的不同,TI DSP分為定點(fixed-point)DSP和浮點(floating-point)DSP。由于浮點DSP既有定點指令集,又有浮點指令集,因此,本文選取浮點DSP系列TMS320C67x的DSP Lib,并且選取了TMS320C67x DSP Library和TMS320C67x FastRTS Library兩個DSP Lib,前者主要針對數字信號處理的常用操作,后者則針對一般數學運算的通用操作。
2 TMS320C67x DSP Library的應用
當DSP進行數據處理時,卷積、FFT、FIR濾波等操作頻繁出現,故在程序開發中,使用DSP Lib來完成這些操作將大大提高整個程序的效率并簡化編程。TMS320C67x DSP Library就是這樣的一個DSP Lib,它的lib文件夾內含庫文件dsp67x.lib和源文件dsp67x.sr、dsp67x_C.sr-c、dsp67x_sa.src。TMS320C67x DSP Library主要用于TMS320C67x系列DSP芯片的程序開發,使用它可完成FFT運算。
2.1 TMS320C67x DSP Library的使用
使用TMS320C67x DSP Library的第一步是將其核心文件“dsp67x.lib”加入到當前工程中,相關編譯鏈接參數為“-ldsp67x.lib”;接著,將存儲頭文件的include目錄所在路徑添加到工程搜索路徑中,其相關編譯鏈接參數為“-i pathname”,具體操作可參考TI公司的有關文獻。選取該DSP Lib中的庫函數“DSPF_sp_cfftr2_dit()”可完成FFT運算,它使用的是基2的時間抽取算法,具體形式如下:

同時,該庫函數還有一個對應的頭文件“dspf_sp_cfftr2_dit.h”,使用時可將其包含到調用該庫函數的程序中。此時,該庫函數就可以像一般子程序一樣被其他程序調用,具體使用代碼如下:

為了便于比較,可使用歸檔器指令“ar6x”從該DSP Lib的源文件“dsp67x_c.src”中提取出庫函數的源代碼,以得到文件“sp_cfftr2_ dit.c”。所有歸檔器指令的命令文件都存儲在CCS的安裝目錄下,這里,“ar6x”的使用格式為:
ar6x-x dsp67x_c.src sp_cfftr2_dit.c
從“sp_cfftr2_dit.c”中可得到庫函數“DSPF_sp_cfftr2_dit()”的C語言源代碼,相應的C程序為“void sp_cfftr2_dit(float*x,float*w,short n)”,該程序可以像一般子程序一樣被主程序調用。源函數和庫函數的形式完全相同。實際上,庫函數就是對源函數的程序代碼進行手工優化的結果。
2.2 性能分析
分別使用庫函數和源函數可完成FFT運算。并可用CCS自帶的剖析工具“Profiler”來分析兩個函數由于編程方式的不同所帶來的運行時間上的差異。改變輸入數組的長度,可得到如表1所列的一組數據。由表1可以看出,庫函數的效率遠遠高于源函數,其效率的提高量隨著輸入數據長度的變化而變化,最高的效率可提高40倍(40.98-1=39.98),最低仍在25倍左右,而且該DSP Lib的其他庫函數也有相近的測試結果。雖然用該DSP Lib的庫函數后,程序效率可以提高一個數量級,對于時間限制較為嚴格的系統,特別是實時系統,這仍然是非常有用的。
庫函數和源函數相比,其效率有了很大提高,但這種提高是有代價的。它主要表現為通用性降低。其原因是為了最大限度的提高效率,在對代碼進行手工優化的過程中,引入了一些強假設,同時,使用了大量的操作合并、并行處理等簡化手段,這必然導致庫函數的通用性降低。例如,庫函數“DSPF_sp_cfftr2_dit()”使用時就會受到以下條件的限制:
(1)輸入數組的長度必須是2的冪級數,且不得小于32;
(2)輸入數組x和旋轉因子數組w必須按雙字對齊方式存儲,即數組起始地址的末3位必須是零;
(3)數據的存儲格式必須是小端模式(Little Endian);
(4)執行期間可接收中斷,但不予響應,這可能導致一些實時事件得不到及時響應。

如果使用“DSPF_sp_cfftr2_dit()”時不考慮到這些限制,就有可能導致程序運行異常。因此,庫函數的效率雖然高,但不能盲目的濫用,在程序開發時,必須根據實際情況在通用性和效率之間進行折衷,以合理的使用庫函數。
3 TMS320C67x Fast RTS Library的應用
在DSP進行數據處理時,除了一些典型的操作外,還存在大量常規的操作,如除法操作、對數運算、三角函數等,這些操作也是很費時的,提高這些操作的代碼效率,也能顯著提高整個軟件的效率。TMS320C67x FastRTS Library就是這樣的一個DSP Lib,它通常由Lib文件夾、include文件夾和doc文件夾組成。其中lib文件夾內含庫文件fastrts67x.lib(Little Endian)、fastrts67xe.lib(Big Endian)和源文件fastrts67x.src;include文件夾內含頭文件fastrts67x.h和recip.h;而doc文件夾內含幫助文件。
3.1 TMS320C67x FastRTS Library的使用
TMS320C67x FastRTS Library(以下簡稱FastRTS Library)主要用于處理一些常規的操作。由于在通常情況下,CCS已經有一個RTSLib-rary來完成這些操作(例如,“rts6700.lib”就是一個適用于TMS320C67x的RTS Library文件),因此,如果要使用FastRTS Library,就必須在編譯鏈接過程中先于“rts6700.lib”來編譯鏈接“fastrts67x.lib(或fastrts67xe.lib)”,相應的編譯鏈接命令選項為:
-l fastrts67x.lib - rts6700.lib或 -l fastrts67xe.lib - rts6700.lib
FastRTS Library同樣需要注意頭文件的使用,它有兩個頭文件: “fastrts67x.h”和“recip.h”。如果使用FastRTS Library中的特殊函數(三角函數,對數函數等),則必須包含“fastrts67x.h”;而如果使用求倒數操作,則必須包含“recip.h”。FastRTS Library的使用方式如下:
3.2 性能分析
分別使用FastRTS Library和RTS Library可完成一些常用操作,使用剖析工具可得到各個操作所需的時鐘周期個數,具體如表2所列(所有的操作均處理單精度浮點數)。對比表2中的數據可以發現,和RTS Library相比,FastRTS Library大大提高了程序的效率。

4 DSP Lib的編寫
事實上,程序員并非只能被動的使用DSP Lib。只要遵循相應的規則,程序員也可以自己編寫一個DSP Lib。編寫一個最簡單的DSP Lib的步驟如下:
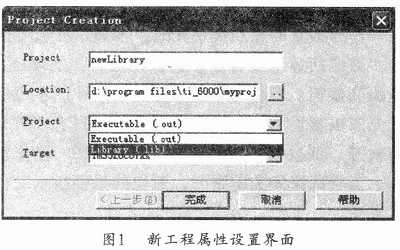
(1)新建一個工程newLibrary,將其屬性設為“Library(.lib)”,圖l所示是新工程設置示意圖;
(2)編寫高效率代碼文件myLibl.asm、myLib2.asm、myLib3.asm,……
(3)將myLibl.asm、myLib2.asm、myLib3.asm,……等文件添加到工程new Library中;
(4)編譯鏈接工程new Library;
完成上面4步后,工程中就會出現庫文件newLibrary.lib,這樣,一個DSP Lib就制作成功了。為了使DSP Lib具有保密性,通常情況下,只需保留工程中的newLibrary.lib文件,而將其他文件,特別是源代碼文件*.asm刪除或保密存放。這樣,用戶就只能使用庫文件,而無法從中得到源代碼的信息。
5 結束語
本文以TMS320C67x DSP Library和TMS320C67x FastRTS Library為例,詳細介紹了如何在程序開發中使用TI DSP Library,并分析了使用TI DSP Library所帶來的程序效率的提高。最后,還給出了編寫TI DSP Library的一個應用實例。
1 TMS320C542結構及應用
TMS320C542是TI公司C5000系列DSP中的一種,C5000系列共有的特點如下:
·改進的哈佛結構,包含一條程序總線,三條數據總線和四條地址總線
·高度并行的CPU和針對應用優化的硬件
·針對算法和高級語言優化的指令集
·先進的IC技術使其既高性能又低功耗
C5000系列內部硬件功能塊如圖1所示。其中,有:40bit算數邏輯單元(ALU);兩個40bit累加器A和B;17×17bit乘加單元(40bitMAC,可作64級FIR運算而不必考慮溢出;計算、選擇、存儲單元(CCSU),特別適合Viterbi等算法;40bit桶型移位寄存器;片上雙存取RAM,每機器周期可存取兩次;片上單存取RAM,可同時訪問兩塊片上存儲區;片上外圍接口,包括串口、定時器、PLL、HPI接口等。
TMS320C542自身特點如下:
·25ns單周期定點指令執行時間,5V供電
·10K Words16bit片上雙存取RAM
·64K Words程序,64K Words數據,64K Words I/O存儲空間
·2K Words HPI接口,可通過此接口方便地與主設備進行信息交換,主設備也可通過此接口下載DSP程序
·一個自動緩沖的串口和一個TDM串口,且都可用作標準同步串口
此外,C5000系列DSP可使用JTAG接口進行調試,可完全控制DSP上的所有資源,使用方便可靠。
2 系統結構
由TMS320C542構成的數據采集處理系統的結構如圖2所示,以DSP為中心,帶有64K程序RAM,64K數據RAM,并通過16K×16的FIFO將數據送到DA,16K×16的FIFO將AD采集的數據送到DSP。與主機通過HPI接口進行數據交換。對SRAM、FIFO、AD、DA的控制,DSP所需各種狀態信息的獲取,以及與主機的其它一些聯系,都通過CPLDA和CPLDB來實現。
C5000系列DSP關鍵的外部接口信號如下:
·A0~A15,地址總線
·D0~D15,數據總線
·/MSTRB,外部存儲器存取閘
·/IOSTRB,I/O存取閘
·R/W,讀寫信號
·/PS,程序空間選擇
·/DS,數據空間選擇
·/IS,I/O空間選擇
·READY,數據準備好
此外,還有/HOLD、/HOLDA等,本系統未用。
2.1 存儲器控制
程序存儲器和數據存儲器各使用一片64K×16的SRAM,為了使DSP對外存的操作盡量快,其速度等級為12ns。使用/PS作程序存儲器的片選,/DS作數據存儲器的片選,而兩片存儲器的讀寫信號如下:
/OE=not(not(/MSTRB) and not(R/W))
/WR=notnot(/MSTRB) and (R/W)
出于高速的需要,采用了Xilinx公司的XC9536生成邏輯(CPLDA)。XC9536管腳至管腳的延遲為5ns,內部有36個宏單元,可用管腳34個,可在線編程,使用起來有很多優點。通過這些措施,系統可零等待地存取程序和數據RAM,也就是說,存儲器讀可達40M×16bit,寫可達20M×16bit。
2.2 FIFO控制
用于DAFIFO的寫和ADFIFO的讀都由CPLDA產生,其邏輯方程為:
/ADFIFOR=not(not(/IOSTRB) and not(R/W) and ADDR0x0)
/DAFIFOW=not(not/IOSTRB) and R/W and ADDR0x0)
其中,ADDR0X0指DSP的A15~A13為零。
DIFIFO由兩片容量16K×9bit、速度10ns的FIFO構成,ADFIFO亦如此。由于控制信號的低延遲和FIFO的高速,對FIFO的存取也達到了零等待,即:使用RPT或RPTZ指令時,可達20M×16bit/s。
2.3 A/D和D/A控制
A/D轉換器負責將外部模擬信號變換成DSP可處理的數字量,是DSP進行處理的基礎,在系統中具有十分重要的地位,采用的是10M采樣率、12bit分辨率的AD9220,如果需要,可在不改板的情況下換成20M或40M采樣率的A/D。而D/A則將DSP生成的數字信號變成模擬量,完成信號的輸出或對系統其他部分的控制,采用了100M速度的AD9762。A/D和D/A的控制信號如下:
·ADCLK和DACLK,分別是A/D轉換器和D/A轉換器的時鐘
·ADFIFOW,將A/D轉換的數據寫入ADFIFO
·DAFIFOR,從DAFIFO讀出數據以供D/A轉換
·DAFIFOMR和DAFIFORT,用于DAFIFO的清零和重傳
·ADFIFOMR和ADFIFORT,用于ADFIFO的清零和重傳
此六個信號都由CPLDB產生,CPLDB采用的是Xilinx公司的XC95108,速度為10ns,有108個宏單元,可在線編程,因而有較高的靈活性。使用24MHz的晶振為CPLDB提供時鐘,由DSP通過I/O口向CPLDB寫入數據以控制ADCLK和DACLK的開關和頻率,并以I/O寫的方式產生FIFO的清零和重傳信號。
2.4 CPLDA和CPLDB的應用
由以上介紹可以看出,整個系統的邏輯都由CPLDA和CPLDB產生。此外,它還有以下功能:
·FIFO的所有狀態信號,系統外部送入的各種控制和狀態信號,都送入了CPLDB,可由DSP通過I/O方式讀取
·DSP的四個外部中斷、NMI中斷都連至CPLDB,可通過I/O口實時控制哪個信號接入哪個中斷,具有較大的靈活性
·DSP的通用I/O管腳BIO和XF連至CPLDA,可以查詢方式快速響應外部信號
·主機對DSP的復位和其它一些特征的控制,對DSP的某些信息的讀取
·DSP對其它一些外圍電路的控制
由于在硬件設計時,對實際應用的要求并不能完全了解,因此需要使系統有足夠的冗余和靈活性,使用CPLD可以達到這一要求。通過將可能需要的各種控制和狀態信號引入CPLD,并利用CPLD的大容量和現場可編程性,可根據不同的要求進行現場修改,從而使系統設計的成功率更大,并且有很大的靈活性。
系統中使用了兩片CPLD,而沒有用一片大容量的CPLD代替,是出于系統性能的考慮。因為存儲器和FIFO的讀寫信號需要較低的延遲才可滿足零等待的要求,而大容量的CPLD延遲大且價格高,因而用XC9536滿足系統對速度的要求,而用XC95108滿足系統復雜邏輯對容量的要求。
2.5 HPI接口
DSP可使用HPI(Host Port Interface接口方便地與主設備或主處理器交換數據,而幾乎不需增加額外的器件。對40MHz主頻的320C542而言,通信速度最快可達64Mbps。而且C5000系列DSP通過某種連線方式,可利用HPI接口下載程序,從而使系統具有更大的靈活性。HPI接口的框圖如圖3所示,有HPIA(HPI地址寄存器)、HPID(數據寄存器)、HPIC(控制寄存器)三個16bit寄存器,主設備就是通過這些專用寄存器與HPI通信。在C542的10K內部RAM中,有2K字屬于HPI存儲塊。系統框圖如圖4所示,HD0~HD7是8位數據線,直接連到主設備的數據線上;HCS為片選信號;HDS1和HDS2為數據鎖存信號,在主設備的存取周期控制數據的傳輸,一般連至主設備的數據選通;HR/W決定當前操作是讀還是寫,可根據主設備的具體情況決定與何種信號相連;HCNTL0/1用于主設備選擇存取HPI的哪一個寄存器和對寄存器的存取類型,連至主設備的地址線;由于HPI寄存器是16位,而HPI與主設備僅以8位數據線相連,因而用HBIL決定當前存取的是一個字的第一還是第二字節,連至主設備的地址線。
對HPI進行操作,首先要將控制字寫入HPIC,然后將要存取的地址寫入HPIA,最后存取HPID,就可從HPI存儲塊讀數或將數據寫入HPI存儲塊。此外,還可選擇HPIA自動增加方式,將初始地址寫入HPIA后,可不再操作HPIA,每存取一次數據,地址都會自動加一,因而大大加快了存取速度。
在本系統中,主設備是AMD186構成的嵌入式系統,AMD與HPI的連接如圖5所示。由以上介紹可以看出,使用HPI也可與PC機的ISA總線方便地連接,用PC機作為主設備,通過PC機向DSP下載程序完成各種功能。
要使用HPI下載程序,只需在DSP復位時將程序通過HPI接口寫入HPI存儲塊從0X1000開始的存儲區,并在上電復位后的一段時間將HINT管腳的信號引至INT2管腳,DSP在Boot程序中檢測到后,就會自動跳轉至0X1000處開始執行。
3 系統工作流程及設計注意事項
系統通過實際測試,運行速度為40MIPS,程序和數據存儲器、所有I/O口都能全速運行,工作穩定可靠。其工作流程如下:
(1)根據要求編寫DSP程序并調試通過。
(2)復位DSP,并由主設備通過HPI接口向DSP下載程序。
(3)復位信號失效,DSP在主設備的控制下開始工作。
由于系統工作于較高的頻率下(CPU為40MHz,外圍設備一般為20MHz,最高為40MHz),因而在系統設計中,必須注意高頻影響。
首先,系統要盡量簡單,要選擇大容量、表面封裝的元器件,以使元件數量少、體積小,降低信號反射并有利于布線。
其次,在設計PCB板時,要采用四層板,中間兩層作電源和地,并多加一些去耦電容。布線時不可用90度的拐彎,過孔要盡量少。數據和地址最好成組布線,以降低對其它信號的影響。一些關鍵的控制線,如存儲器讀寫信號和FIFO讀寫信號,最好在其兩邊加地線保護。特別是FIFO的讀寫信號,由于其對干擾特別敏感,要特別注意。對一些較長的引線,可串接一個30Ω的小電阻或加終端匹配以減小反射。
4 C5000系列DSP的軟件編程和調試
C5000系列DSP的編程工具,有C語言和匯編語言兩種,而匯編語言又有兩種指令集,一種叫記憶指令集(Mnemonic Instruction Set,類似8086的匯編語言;一種叫代數指令集(Algebraic Instruction Set,類似于C語言,使用起來比記憶指令集方便很多。
實際應用中,一般都是C和匯編混合編程,混合編程的方法,可查閱C5000系列DSP的手冊得到。TI公司還提供了一個運行庫(Runtime Lib,用TI公司的JTAG調試器進行調試時,在DSP程序中調用運行庫的函數,可以打開PC機上的文件獲取數據,或將DSP的數據傳入PC機并存入文件,或通過PC機鍵盤向DSP傳遞信息和發送命令,總之,可以為調試帶來極大的方便。
在本系統中,由于既有A/D,又有D/A,構成了一個閉環,自發自收。可以由D/A生成模擬波形,由A/D實時采集,由DSP處理,對算法的設計和調試可帶來很大的幫助。
]]>聲音信號無處不在,同時也包含著大量的信息。在日常的生產生活中,我們分析聲音信號,便可以簡化過程,得到我們想要的結果。隨著 DSP芯片的性價比不斷攀升,使 DSP得以從軍用領域拓展到民用領域,由于 TI公司 DSP5000系列強大的音頻壓縮能力,語音應用得到了較大的發展。因此,基于 DSP的聲音采集系統的設計與開發具有重要的現實意義。
1系統總體介紹
該系統主要應用于工業生產中,通過采集的聲音信號與數據庫中的數據相比較,來檢測生產設備的運行狀態等。本系統主要分為以下幾個部分:電平轉換電路、 AD轉換電路、靜態存儲與動態存儲、USB接口以及 JTAG部分。
該系統通過采集聲音信號來檢測器械的裂紋、密合度等。將 DSP高速處理數字信號的能力與 USB高速傳輸數據的能力結合起來,使其服務于工業生產,是該系統的主要設計目的。系統選用了 TI公司的TMS320VC5402作為該塊 PCB的 CPU,并將 PHILIPS公司的 PDIUSBD12作為接口芯片,使用 USB1.1協議進行 DSP與電腦的通信。 2硬件設計思想人類可以聽到的聲音信號是范圍在 20-20kHz的模擬信號,所以首先需要傳感器接收該聲音信號,接著需要進行轉換,使聲音信號由模擬信號變為數字信號。之后通過分析噪聲產生的原因和規律,利用被測信號的特點和相干性,檢測被覆蓋的聲音信號。在檢測方法上有頻域信號的相干檢測、時域信號的積累平均、離散信號的計數技術、并行檢測等方法。
由于 5402片內的 ROM和 DRAM資源有限,所以該系統需要外部存儲設備,本設計選擇一片 SRAM作為靜態存儲器,一片 FLASH作為動態存儲設備。5402的 CPU電壓為 3.3伏,外設電壓為 1.8伏,所以該系統還需要一個供電的電源模塊,可以將一般的輸入電壓 5伏轉化為 3.3與 1.8伏的電壓為 DSP供電,該 5V電壓還可為除 DSP以外的其他設備供電。
DSP與計算機的通信,通常采用 USB、RS232、PCI或 ISA卡等方式。RS232的主要缺點是:速度慢,不支持熱插拔; PCI與 ISA卡的主要缺點是:受計算機卡槽數量、地址等資源的限制,可擴展性差。而利用 USB通訊的主要優點,便是傳輸速度快,支持熱插拔,占用資源少,可擴展性強。該設計利用 USB接口芯片直接與 DSP相連,通過 DSP的程序實現 USB的協議,最大的優點就是可以保障數據交換的速度。綜上,在本系統中,幾個基本環節就是:電平轉換電路:將 5V電源轉換為 3.3V與 1.8V,分別為 DSP芯片的片上外設以及 CPU供電; AD信號轉換電路:將傳感器接收到的模擬信號轉換為數字信號,供 DSP進行處理;信號的存儲電路:儲存 DSP處理的信號;信號傳輸電路:將經過處理的信號上傳至電腦;仿真電路:用于測試 DSP芯片。整體架構如圖 1所示。
3模塊介紹
3.1 DSP
1、 DSP技術簡介
數字信號處理器,簡稱 DSP,是專業進行信號處理的芯片,目前在通信、自控領域具有廣泛的應用。在信息資源大大豐富的今天,數字化程度已經越來越高。而 DSP作為這一技術的重要組成部分,對我們的生活已經產生了越來越深刻的影響。自從 1978年 AMI公司發布了“單處理設備”開始,從基于 Harvard結構但使用不同數據與程序總線的第一代通用DSP,到進行了改進的第二代增強型通用DSP,再到包含了 GPP結構的第三代DSP,今天的DSP的發展趨勢已經趨向于混合結構,DSP產品與計算機之間的差別已經越來越模糊。在數字化時代背景下,DSP已成為各種電子產品等領域的基礎器件,而其在電機控制、聲音識別與圖像識別領域中的應用則是更為廣泛。
2、聲音采集系統中采用的 DSP
本系統中 DSP采用的是 TI公司的 TMS320VC5402(以下簡稱 5402),其操作速率達 100 MIPS,由于其具有改進的哈佛結構,所以它可以在一個指令周期內完成 32x32bit的乘法,亦可以迅速完成數學運算最常用的乘加運算。它有 4條地址總線、3條 16位數據存儲器總線和 1條程序存儲器總線, 40位算術邏輯單元 (AIU),一個 17×17乘法器和一個 40位專用加法器。8個輔助寄存器及一個軟件棧,允許使用最先進的定點 DSP的 C語言編譯器,內置可編程等待狀態發生器、鎖相環(PLL)時鐘產生器、兩個多通道緩沖串行口、一個 8位并行與外部處理器通信的 HPI口、2個 16位定時器以及 6通道 DMA控制器,特別適合電池供電設備.
]]>CCS(Code Composer Studio)代碼調試器是一種集成開發環境(IDE,Integrated Development Environment)。 CCS是一種針對標準TMS320調試器接口的交互式方法。CCS目前有CCS1.1 CCS1.2 CCS2.0等三個不同的版本,每個版本應有CC2000(針對C2XX)
CCS5000(針對C54XX)CCS6000(針對C6X)等三個不同的型號。我們所使用的是CC2000、1.2的版本。這里所說明的CCS的一切問題都是基于CC2000所討論,對其他版本的使用其差別不是很大,請參考其他有關資料。
1.CC2000的特點
CC2000具有以下特性:
lTI編譯器的完全集成的環境
CC2000目標管理系統,內建編輯器,所有的調試和分析能力集成在一個Windows環境中。
l對C和DSP匯編文件的目標管理
目標編輯器保持對所有文件及相關內容的跟蹤。它只對最近一次編譯中改變過的文件重新編譯,以節省編譯時間。
l高集成的編輯器調整C和DSP匯編代碼
CC2000的內建編輯器支持C和匯編文件的動態語法加亮顯示,使用戶能很容易地閱讀代碼和當場發現語法錯誤。
l編輯和調試時的后臺編輯
用戶在使用編譯器和匯編器時沒有必要退出系統到DOS環境中,因為CC2000會自動將這些工具裝載在它的環境中。在其窗口中,錯誤會加亮顯示,只要雙擊錯誤就可以直接到達出錯處。
l在含有浮點并行調試管理器(PDM)的原有的MS窗口下支持多處理器,CC2000在 Windows95和Windows-me中支持多處理器。PDM允許將命令傳播給所有的或所選擇的處理器。
l在任何算法點觀察信號的圖形窗口探針
圖形顯示窗口使用戶能夠觀察時域或者頻域的信號。對于頻域圖,FFT在主機內執行,這樣就可以觀察所感興趣的部分而無須改變它的DSP代碼。圖形顯示也可以同探針連接,當前顯示窗口被更新時,探針被指定,這樣當代碼執行到達該點時,就可以迅速地觀察到信號。
l文件探針在算法處通過文件提取或加入信號或數據
CC2000允許用戶從PC機讀或寫信號流。而不是實時的讀信號,這就可以用已知的例子來仿真算法。
l圖形分析
CC2000的圖形分析能力在其環境中是集成的。
l在后臺(系統命令)執行用戶的DOS程序
用戶可以執行CC2000中的DOS程序,并將其輸出以流水方式送到CC2000的輸出窗口。且允許用戶將應用集成到CC2000。
l技術狀態觀察窗口
CC2000的可視窗口允許用戶鍵入C表達式及相關變量。結構、數組、指針都能很簡單地遞歸擴展和減少,以便進入復雜結構。
l代數分解窗口
允許用戶選擇查看寫成代數表達式的C格式,從而容易讀懂操作碼。
l目標DSP上的幫助
DSP結構和寄存器上的在線幫助可以使用戶不必查看技術手冊。
l用戶擴展
擴展語言(GEL)使得用戶可以將自己的菜單項加到CC2000的菜單欄中。
l完全的開發環境
CC2000將TI的編譯器、匯編器、連接工具都集成到它的開發環境中。用戶可以從菜單欄中選用TI的工具,并可以看到直接流水輸出到窗口的編譯結果。同時,出錯信息加亮顯示,雙擊出錯信息可以打開源文件,光標停在出錯處。基于DOS的TI的工具是多任務的。而在Windows環境中,用戶可以很方便的同時編輯、調試、編譯源程序。代碼編譯器可以跟蹤一個項目中所有的文件及相關內容。用戶可以選擇編譯單個的文件、或將所有文件建到一個項目中,或是逐步建項目。在編譯器、匯編器、和連接器選項中有容易使用的對話框。
CC2000的可視化窗口使用戶能夠容易理解復雜的結構。只要將光標放在相關變量處并按ENTER鍵,諸如數組、結構、指針的變量就可以遞歸的增加或減少。另外,添加到可視窗口的變量也可以通過雙擊該變量來編輯。C表達式和GEL函數也可以添加到可視窗口。將GEL函數添加到可視窗口,就可以在每個斷點處執行。由GEL函數,可以執行更復雜的任務,將結果輸出到窗口。
探針允許用戶觀察信號或在算法上加入或提取數據。它可以連接到結構點或存儲空間。到達算法里的指定點時,已連接的信號探針就會從目標DSP中提取出數據并顯示。如果將文件同指定點相連,數據就會在指定的存儲空間與文件間傳輸。操作一結束,執行就開始。這種特性使得開發者能夠很快地觀察到目標內存并通過文件在特定的算法點增加或提取數據。利用動畫特性,開發者可以通過使用PC機磁盤中的實信號細致地觀察和執行信號,而不用改變源代碼。]]>
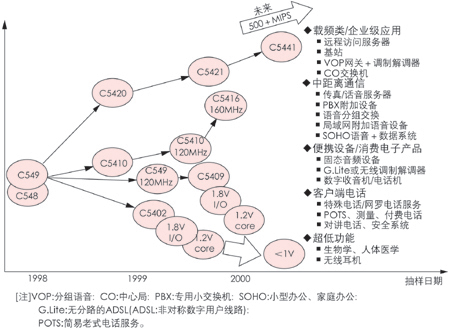
圖1 TMS320C5000性能發展狀況及應用領域
TMS320系列的同一代芯片具有相同的CPU結構,但根據市場的不同需要,形成新的存儲器與外設的不同組合,產生了多種派生器件。
TMS320C54x關鍵特性
圖2是C54x功能結構圖,它的主要性能如下:
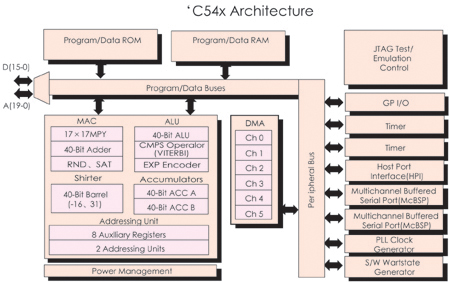
圖2 TMS320C54x功能結構框圖
⒈ CPU
先進的多總線結構:一組程序總線(PAB、PB),三組數據總線(CAB、CB,DAB、DB,EAB、EB)
40位的數學邏輯單元(ALU):包括40位的桶形移位寄存器和兩個獨立的40位累加器
17 17位并行乘法器和40位專用加法器,單周期完成乘法/累加(MAC)
適于Viterbi運算的比較、選擇、存儲單元(CSSU)
指數編碼器,可在單周期內計算(40位)累加器中數值的指數
兩個地址產生器,包括八個輔助寄存器和兩個的算術單元
⒉ 存儲器
可尋址存儲空間達192K字(程序、數據及I/O各64 64bit),C548還可擴展程序存儲器(8兆字)
典型C5400芯片存儲器
⒊ 片內外設
軟件可編程等待狀態產生器
可編程的塊交換
片內鎖相環時鐘產生器
禁止外部總線的控制機制
⒋ 指令集
重復單條指令與重復指令塊
&nbs
p; 存儲器塊移動指令32位數運算指令
可同時讀取2或3個操作數的指令
具有并行保存和并行加載的算術指令
條件保存指令
⒌ 功耗控制
IDLE1、IDLE2和IDLE3指令可控制其進入降功耗模式
可控制是否輸出CLKOUT信號
⒍ IEEE標準的1149.1邊界掃描邏輯接口
TMS320C54x結構概述
''C54x由中央處理器CPU、存儲器和片內外設組成,采用哈佛結構,有獨立的程序空間、數據空間和I/O空間。圖3是''C54x的內部硬件框圖。
對所有的''C54x器件來說,圖中下半部所示的中央處理單元(CPU)是通用的。
總線結構
一組程序總線(PAB、PB)和三組數據總線CAB、CB,DAB、DB,EAB、EB)將內部各部件聯系起來。
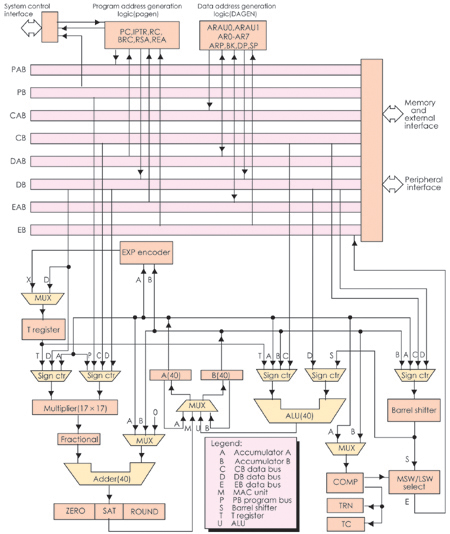
圖3 TMS320C54x內部硬件框圖
PB- 程序總線,傳送程序代碼或存在程序空間的數據;
CB、DB、EB- 數據總線,連接CPU、數據地址產生邏輯、程序地址產生邏輯、片內外設及存儲器等各部件;
CB和DB- 傳送從存儲器讀出的數據,即“讀”操作使用的數據總線;
EB-傳送向存儲器寫入的數據,即"寫"操作使用的數據總線;
PAB、CAB、DAB、EAB- 各對應的地址總線;
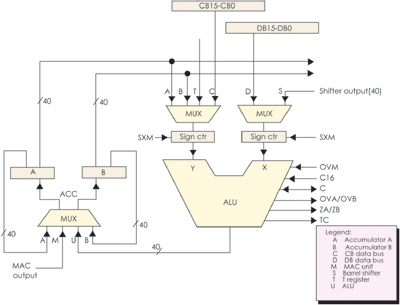
圖4 ALU功能框圖
中央處理單元(CPU)
ALU:算術邏輯運算單元
主要由40位ALU和兩個40位累加器(ACCA和ACCB)組成,如圖4所示。
&
nbsp; ALU和兩個累加器用來完成40位二進制補碼的算術運算,也能完成布爾運算。當狀態寄存儲器ST1的C16位置1時,可做兩個16位ALU,同時完成兩個16位運算。輸入:
16位立即數;
來自數據存儲器的16位數;
來自暫存器T的16位數;
來自數據存儲器讀出的兩個16位數;
來自數據存儲器讀出的一個32位數;
來自累加器(A和B)的40位數;
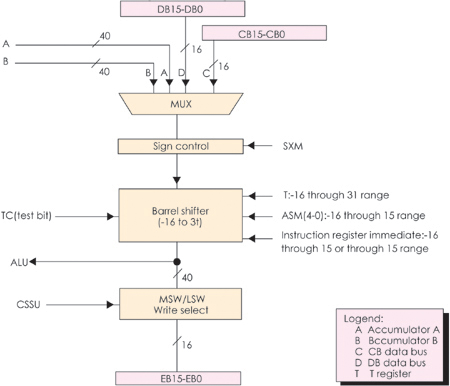
圖5 桶形移位器功能框圖
輸出:ALU的40位輸出被送往累加器A或B。
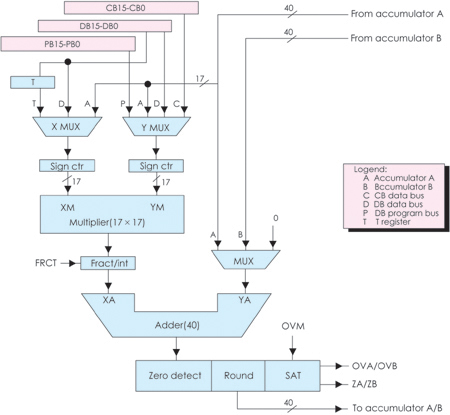
圖6 乘/加模塊功能方框圖
桶形移位器:將輸入數據左移0~31位或右移0~16位,經常用作數字定標、位提取、擴展算術和溢出保護等操作。 輸入40位:來自累加器或經DB、CB的 數據存儲器;
輸出40位:連到ALU或經EB連到數據存儲器;
所移位數由指令中移位字段、ST1的ASM字段或T寄存器指定移位位數決定。
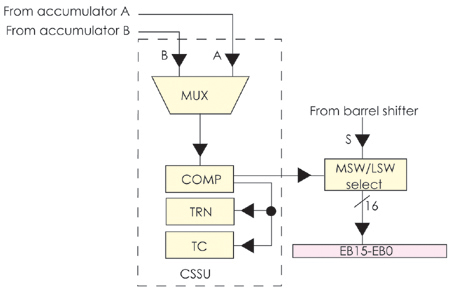
圖7 比較、選擇與保存單元(CSSU)功能框圖
乘/加模塊:由乘法器、加法器、輸入數據的符號控制邏輯、小數控制邏輯、零檢測、舍入、溢出/飽和邏輯和16位暫存寄存器T等組成。乘法器和ALU在一個指令周期內共同完成(17 17補碼)乘/加(40位)運算,且可并行地作ALU運算,這些功能可用來做Euclidean距離及LMS濾波等復雜運算。乘/加模塊功能方框圖如圖6所示。
比較、選擇與保存單元(CSSU):可以完成累加器的高位字和低位字之間的最大值比較(CMPS指令)。另一功能是利用優化的片內硬件資源完成數據通信、模式識別等領域中經常用到的Viterbi蝶形運算。
&
nbsp;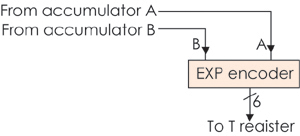
圖8 指數編碼器
指數編碼器:用于支持單周期指令EXP的專用硬件,如圖8所示。
累加器中數值的指數值,以二進制補碼形式(-8~31)存放于暫存器T中;
CPU狀態和控制寄存器:
''C54x共有3個16位狀態和控制寄存器(PMST、ST0、ST1)它們都是存儲器映象寄存器,可以方便地寫入數據、或由數據存儲器對它們加載。
內部存儲器
·''C54x的存儲器分為三個可獨立選擇的空間:程序空間、數據空間和I/O空間;
·''C54x的片內存儲器包括ROM和RAM,其中RAM又可分為SARAM和DARAM:SARAM為單尋址寄存儲器,DARAM為雙尋址寄存儲器(一周期內可以訪問兩次)。
ROM一般配置成程序存儲空間,用于存放要執行的指令、系數表等固定操作數。也可以部分地安排到數據存儲空間,由PMST的狀態位 和DROM決定;RAM 一般安排到數據存儲空間,存放執行指令所要用的數據。但也可以安排到程序空間,由PMST的狀態位OVLY決定。不同''C54x系列內部存儲器配置各不相同。
''C54x的尋址方式
TMS320C54x的指令可能含有1個存儲器操作數(指令說明中用Smem表示),也可能有2個存儲器操作數(指令說明中用Xmem、Ymem表示),分別稱為單存儲器操作數和雙存儲器操作數。單存儲器操作數有7種尋址方式,它們是:
立即尋址: 操作數(常數)含在指令中;
絕對尋址: 指令中含有操作數的16位地址;
累加器尋址: 操作數地址在累加器中(A);
直接尋址: 指令中含有操作數地址的低7 位;
間接尋址: 操作數的地址在輔助寄存器中,支持倒位序尋址、循環尋址等功能;
存儲器映像的寄存器尋址:
訪問存儲器映像寄存器,
又不影響DP或SP;
堆棧尋址: 訪問堆棧;
雙存儲器操作數支持一些特殊指令:
如MAC、FIR等復雜指令。
''C54x的六級指令流水線
&nb
sp; ''C54x CPU的指令流水線有六級,每個周期有六條指令在工作,它們處于整個執行過程的不同階段,如圖9所示。 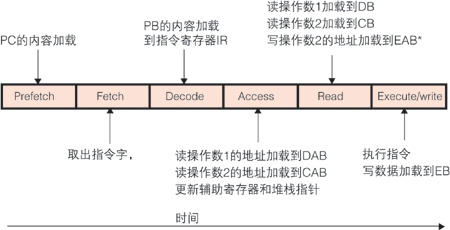
圖9 流水線不同工作階段操作內容
流水線的工作全部為單字指令連續執行時(理想情況)如圖10 所示。
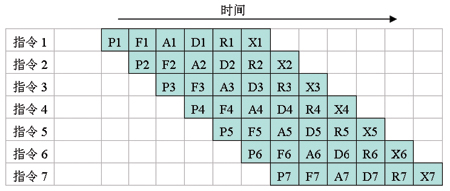
圖10 流水線正常工作時做業情況
]]>我發現在國內無論在公司或高校許多地方為了加快開發周期往往把一個產品開發分為硬件和軟件兩個相對獨立部分,由不同的人完成。這在具有一定技術和管理基礎的公司,由總設計師統一規劃協調,分任務并行完成的情況下是可行的,也是符合現代產品開發規律的。但是在高校人員的流動很大,研究生的有效科研時間很短、基礎差(許多研究生起步時對電熔、電阻、三極管的分類和選型都很困難,我也是這樣過來的)更不用說系統規劃設計了,況且許多老板自己也不太懂,師兄有自己的任務,他們搞明白時也畢業了。在許多高校做DSP就是找一個算法加到自己的主程序里,在板子上跑一下,基本達到效果就可以了,至于可靠性是次要的,產業化無從談起,這已經算不錯的了。
其實我覺得一個系統的完成,系統的規劃是最重要的,在規劃時對硬件設計的知識和認識是決定性的,它可以讓你知道什么是可行的,什么是不可行的,當你同時具有軟件設計能力時,就可以合理的分配系統功能,完成使用VHDL進行系統行為描述-—系統功能劃分—— 系統子結構設計這樣的自頂向下的設計規劃流程,成為系統設計專家、項目經理,否則只是硬件工程師、軟件工程師。無論作51、196、還是DSP都是這樣。
下面分別談談我對硬件和軟件設計的感受
硬件設計是系統設計的關鍵,國內和國外產品的差距往往是硬件設計水平高低決定的,任何軟件設計思想沒有可靠的物理載體都是空中樓閣,紙上談兵。學校的研究生很多都想避開硬件設計,對于一個全新的設計與其說不屑不如說不敢。試想一下燒幾個片子的壓力要比跑飛幾段程序的壓力大的多,尤其是功率器件,一旦燒掉,弄不好火光沖天,人的自信都沒了。況且改一次板周期長,經費高,還不知行不行。其實在國外實力一般的公司也是盡量避免硬件的更新設計,產品一旦定型往往通過軟件升級,這是公司的發展策略,對個人而言物以希為貴,培養一個硬件設計師往往要比軟件設計師時間長花費多。在設計dsp硬件時,開始設計最小系統板,系統按功能分板設計調試,注意分板電路的穩定性可能不如整板電路,要多加入抗干擾環節,分板間的引線包括電源線地線要短,盡量在10公分以內,實在不行加入光耦隔離、采用隔離電源。切記電源線、地線的干擾遠比信號干擾對系統的危害大得多,又常常被人忽視。電路板工作正常的先決條件就是電源正常!當分板電路正常后再更居情況設計整板電路。在調試時發現的問題一定要找到原因解決,即使是飛線,割線,不要寄希望于下一板改了再看,除非原理性錯誤。每一個功能環節多準備幾套方案。DSP的選型要根據系統功能而定,2000是一個功能比較全的控制器,但運算性能相對低,但目前大部分控制類、家電類包括中低層次的工業總線通信產品足夠了,281X不錯但太貴,而且開發技術不成熟。54XX更像一個協處理器,其實高端產品5471就很好,功能完*,但BGA封裝對產品的開發有一定難度。如果沒有從事過嵌入式系統開發的朋友其實可以從51看起,許多思想是共通的,51很經典沒有哪一款微處理器像51那樣使用持久和普遍。在硬件設計時更多的精力放在外圍電路設計上,外圍電路設計的靈活性要比DSP本身高得多,難度大得多。建議多考慮CPLD。
軟件設計上,著眼點不要僅局限于某種算法和控制策略,而是軟件系統框架的制定,即操作系統的選擇和實現,算法和控制策略只是其中技巧性很強的子程序和子程序間參數相互關系,建議設計軟件時能具有操作系統、數據結構和編譯原理方面的知識,特別是使用C。對DSP的內部硬件結構一定要掌握,特別是中斷結構和流程、流水線操作,不然飛都不知道怎么飛的。
在語言選擇上我當時是這么給自己規定的先編20個左右的匯編程序,每個代碼量超過4K,使用語句范圍覆蓋全部語句的60%-70%,在此基礎上使用C。現在發現用C構建程序的主體框架(操作系統)比較快而其不容易出錯,(我現在正在用ASM根據UCOSII的思想重寫自己的操作系統)但對系統實時性影響比較大的運算算法一般采用MATLAB——C——ASM的辦法仿真調試優化,這里的優化不單單是利用優化器優化,而是根據數據的特點改變運算方法,以除法為例C里的/號其實掩蓋了許多技巧,當除數為常數時就可以放大倒數移位相乘移位的辦法進行,精度高速度快。這些辦法只有掌握了ASM語言并用ASM語言思考才會熟練應用。另外我想告訴一些作算法特別是控制算法的朋友,千萬不要隨意評判一個算法的優劣,在程序中程序和代碼優化的程度往往影響了控制效果好壞,而不是算法本身的思想。其實在實際中往往PID甚至PI、PD就夠了,神經元、模糊、小波適用于研究和寫論文,模糊在實際中用的多一點,主要是小日本用的比較成熟,我再恨日本人,這點也服氣,小日本就是滑,許多物理現象搞不透,就用這法,還管用,題外話。
最后我想說的是,當我們面對市場要求時,產品往往考慮的是可靠性、性能、價格而不是你用的什么芯片,在滿足性能的基礎上結構越簡單就越可靠,芯片越通用價格就越低,能用51就不用196,能用2407就不用2812,除非把芯片本身作買點利用高成本贏取高利潤。無論2000還是5000、6000系列都有市場前景,關鍵是要做深做透
獲取知識的方法、處理項目的能力是相通的,具體的說就是不要把目光盯在做硬件還是做軟件上,用ASM還是C,要勤動手打好基礎,提高自己對系統總體設計的能力,從系統的眼光看問題。為什么都是做DSP的有的畢業拿3000,有的5000、8000,除了運氣和關系外,重要的是你對事物的認識深度和高度。我一直都記住這句話:有前途的人做什么都有前途,沒前途的人做什么都沒前途。
二. 與其說是鉆在里面,畢業設計是搞240,在老師的壓力做出了一點東西,這期間主要是對DSP的各種基礎知識的熟悉與理解,對DSP的真正深入是在公司工作以后。當初進公司,因為正有一個項目需要用5410要我接手。說實話,在學校期間我5000的書都沒有看過一眼,可沒辦法,只能靠自己了。不過好的是我2000DSP的基礎很好。接過項目后,我第一個星期就全部看的是5000的指令,DSP的結構倒沒怎么看,因為項目硬件已成型,主要是算法。這樣,花了一個星期熟悉指令與項目相關的程序,第二個星期也就開始編程了。半個月以后我對5410也就用很熟了的,當然主要還是講在算法方面。這個項目太概做了四個月吧,系統程序是我編寫的,主要有如64位加減乘除乘方開方、及時域方面的一些算法。現在又做一個控制系統,用2407開發的,硬件主要有直交變頻,并把2407的所有外設資源全部用到了。現在我可以這樣自夸一句吧:TI的2000系列與5000系列的我都熟悉,要我去以此做個系統,沒問題。上面是把我搞DSP的經歷簡單說了一下的吧,在這里我想對正在學及想學DSP的難兄們說一句的是,DSP并不是很難。當然,這個前提是你的基礎要好,我單片機,接口都還行,當初就是從單片機改成DSP的。有了單片機的基礎再去學2000第列的DSP(下面的DSP單指2000系列,另有說明為止),你就可以把DSP看成一個super microcontroller了。相比之下,DSP除了比單片機多了更豐的外設接口(SPI,SCI、CAN、PWM、CAP、QEP等等),他就是一塊單片機,只不過在單片機來說你要另加芯片的工作,DSP全部把它做在一塊芯片去了,我現在看DSP也真就這么簡單。前面有人提到DSP主要是做算法,這句話有一定的片面性: TI有很多系列的DSP,現在主流的DSP主要為2000系列、3000系列、4000系列、5000系列、6000系列。除了2000與5000系列是定點DSP外,其余的均為浮點系列。 TI的2000系列主要長處是在用于控制系統,因為它的資源非常豐富,前面提到,在控制系統中用到的一些外設2000系列均在片內集成了。 TI的5000系列主要長處是用于數字信號的算法處理,這里所講算法處理主要是指在數字信號處理時的一些算法,如FIR、IIR、FFT等等。5000系列的DSP的速度比2000快,2407最快只能到40M,2800系列除外,5410的DSP可以達到160M,如現在我們主要用來做數字信號方面的處理以及簡單的靜態圖像處理等這樣一些在資源需要處于中等的一些算法。 TI的6000系列主要是用在實時圖像處理,這個就更則重于算法處理。一般的硬件很少自制,我們是用TI的DSK板再加上自主板相結合。
三. 使用C/C++語言編寫基于DSP程序的注意事項 1、不影響執行速度的情況下,可以使用c或c/c++語言提供的函數庫,也可以自己設計函數,這樣更易于使用“裁縫師”優化處理,例如:進行絕對值運算,可以調用fabs()或abs()函數,也可以使用if...else...判斷語句來替代。 2、 要非常謹慎地使用局部變量,根據自己項目開發的需要,應盡可能多地使用全局變量和靜態變量。 3、一定要非常重視中斷向量表的問題,很多朋友對中斷向量表的調用方式不清楚。其實中斷向量表中的中斷名是任意取定的,dsp是不認名字的,它只認地址!!中斷向量表要重新定位。這一點很重要。 4、要明確dsp軟件開發的第一步是對可用存儲空間的分析,存儲空間分配好壞關系到一個dsp程序員的水平。對于dsp,我們有兩種名稱的存儲空間,一種是物理空間,另一種是映射空間。物理空間是dsp上可以存放數據和程序的實際空間(包括外部存儲器),我們的數據和程序最終放到物理空間上,但我們并不能直接訪問它們。我們要訪問物理空間,必須借助于映射空間才行!!但是映射空間本身是個“虛”空間,是個不存在的空間。所以,往往是映射空間遠遠大于實際的物理空間,有些映射空間,如io映射空間,它本身還代表了一種接口。只有那些物理空間映射到的映射空間才是我們真正可訪問(讀或寫)的存儲空間。 5、 盡可能地減少除法運算,而盡可能多地使用乘法和加法運算代替。 6、如果ti公司或第三方軟件合作商提供了dsplib或其他的合法子程序庫供調用,應盡可能地調用使用。這些子程序均使用用匯編寫成,更為重要之處是通過了tms320算法標準測試。而且,常用的數字信號處理算法均有包括!! 7、 盡可能地采用內聯函數!!而不用一般的函數!!可以提高代碼的集成度。 8、編程風格力求簡煉!!盡可能用c語言而不用c++語言。我個人感到雖然c++終代碼長了一些,好象對執行速度沒有影響。 9、因為在c5000中double型和float型均占有2個字,所以都可以使用,而且,可以直接將int型賦給float型或double型,但,盡可能地多使用int數據類型代替!這一點需要注意!! 10、 程序最后至少要加上一個空行,編譯器當這個空行為結尾提示符。 11、 大膽使用位運算符,非常好用!! 12、 2003年6月份從ti的網站上下到了關于tms320c67x系列dsp的快速算法庫,于是,tms320c5000和c6000全系列的快速算法庫都問世了,這些算法庫均可供c/c++語言直接調用,優化程度100%,實際編程時盡可能地使用(下載時可以同時下載到說明文檔和ascii源程序,可以根據自己需要作出修改,修改前最好做個備份)。]]>
關鍵詞:DSP;混合編程;函數調用規則;寄存器規則
1引言
TI 公司的5000系列低功耗16 b定點DSP,因其良好的性價比,在國內獲得了很大的普及。如何對5000系列DSP進行軟件開發也一直是業界關注的熱點。5000系列DSP的軟件設計通常有3種方法。
1.1用C/C++語言開發
TI公司提供了用于C/C++語言開發的CCS平臺。該平臺包括優化ANSI C/C++ 編譯器,從而可以在源程序級進行開發調試。這種方法大大提高了軟件的開發速度和可讀性,方便了軟件的修改和移植。但是,C/C++代碼的效率還是無法與手工編寫的匯編代碼效率相比,如FFT程序。因為即使是最佳的C/C++編譯器,也無法在所有的情況下都能合理的利用DSP芯片提供的各種資源。此外,用C/C++語言實現DSP芯片某些硬件控制也不如匯編方便,有些甚至無法用C/C++語言實現。
1.2全匯編語言開發
TI公司提供了用于匯編語言開發的針對5000系列DSP的匯編語言。用戶可以用他進行軟件開發。這種方式可以更為合理的利用芯片提供的硬件資源,其代碼效率高,程序執行速度快。但是用匯編語言編寫程序是比較復雜的,一般來說,不同公司的芯片匯編語言是不同的,即使是同一公司的芯片,由于芯片的類型不同(如定點和浮點)、芯片的升級換代,其匯編語言也不同。因此,用匯編語言開發基于某種芯片的產品周期較長,并且軟件的修改和升級較困難。而且匯編語言的可讀性和可移植性較差。
1.3C/C++語言和匯編語言混合編程開發
為了充分利用DSP芯片的硬件資源,更好發揮C/C++語言和匯編語言進行軟件開發的各自優點,可以將兩者有機的結合起來,兼顧兩者優點,避免其弊端。因此,在很多情況下,采用混合編程方法能更好地達到設計要求,完成設計任務。
2 C/C++語言和匯編語言混合編程方法討論
C/C++語言和匯編語言混合編程的具體方法有以下幾種:
(1)獨立編寫C/C++程序和匯編程序,分開編譯或匯編形成各自的目標模塊,再用鏈接器將C/C++模塊和匯編模塊鏈接起來,這是一種靈活性較大的方法。但用戶必須自己維護各匯編模塊的入口和出口代碼,自己計算傳遞參數在堆棧中的偏移量,工作量稍大,但能做到對程序的絕對控制,也能滿足軟件設計結構化的要求。這是本文主要講述的方法。
(2)在C/C++程序中使用匯編程序中定義的變量和常量。
(3)在C/C++程序中直接內嵌匯編語句。這種方法可以在C/C++程序中實現C/C++語言無法實現的硬件控制功能,如修改中斷控制寄存器、中斷標志寄存器等。
(4)在C/C++源程序中使用內部函數直接調用匯編語言語句。
后3種方法由于在C/C++語言中直接嵌入了匯編語言的成分,容易造成程序混亂,C/C++環境被破壞,甚至導致程序崩潰,而編程者又很難對不良結果進行預期和有效控制。而如果采用第一種方法,只要遵循有關C/C++語言函數調用規則和寄存器規則,就能預見到程序運行的結果,保證程序正確。下面分別講述函數調用規則和寄存器規則,最后給出編程實例。
3函數調用規則
C/C++編譯器對函數調用強加了一組嚴格的原則。除了特殊的運行時間支持庫函數外,任何調用函數和被C/C++函數調用的函數都必須遵守這些原則。不遵守這些原則可能破壞C/C++環境并導致程序失敗。
圖1說明了典型的函數調用。在這個例子中,參數被傳遞到堆棧中調用者的參數塊,函數再使用這些參數調用被調用函數。注意,第一個參數是在A累加器中傳遞的。這個例子還說明了匯編器對被調用函數的局部幀的分配。局部幀包括局部變量塊和局部參數塊兩部分,其中局部參數塊是局部幀中用來傳遞參數到其他函數的部分。如果被調用函數沒有局部變量并且不再調用其他函數或需要調用的函數沒有參數,則不分配局部幀。對于混合編程而言,由于被調用函數是手工編寫的匯編程序,則局部幀由編程者自己完成分配,也不需要在堆棧中進行,而編譯器分配局部幀。

(1)函數如何調用
函數(調用者)在調用被調用函數時執行以下任務。
①調用者將第一個(最左邊)的參數值放進累加器A。調用者將剩下的參數按相反的順序傳進參數塊,剩下的最左邊的參數在最低的地址。
②若函數返回一個結構,則調用者為該結構分配空間,然后用累加器A傳遞返回空間的地址給調用的函數。
③調用者調用函數。
(2)被調用函數如何響應。
被調用函數執行以下任務:
注意:如果被調用函數是C/C++函數,則下面步驟都是由匯編器自動完成。如果是混合編程,則如下步驟都是由編程者在被調用的匯編函數中完成的。
①若被調用函數修改AR1,AR2或AR7,則將他們壓入堆棧。
②被調用函數通過從SP減去一個常數,為局部變量塊和局部參數塊分配存儲器。該常數按以下公式計算,即:
局部變量塊的大小+局部參數塊的大小+padding
padding值是為了保證SP對準偶數邊界而可能要求補充的一個字。之所以SP要對準偶數邊界,是因為5000系列DSP指令可一次讀寫存儲器的32 b,例如DLD,DADD等。這樣,編譯器必須保證所有32 b的目標都駐留在偶數邊界。
對于混合編程而言可以在匯編函數中,按本步驟的方法在堆棧中分配局部幀,但本方法相對比較麻煩,尤其該匯編函數還要調用其他函數時,所以,一般而言編程者通常用其他方法分配局部幀,比如用bss偽指令定義局部變量供函數使用。
③被調用函數為調用函數執行代碼。
④若函數返回一個值,則被調用函數將該值放在累加器A中;若函數返回一個結構,則被 調用函數將該結構復制到累加器A指到的存儲器塊;若調用者不返回函數值,則A被置0。
⑤被調用函數給SP上加上第二步計算的常數,釋放為局部變量和局部參數分配的存儲空間。對混合編程而言,如果編程者沒有在堆棧中分配局部幀,則本步驟省略。
⑥被調用函數恢復所有保存的寄存器。
⑦被調用函數執行返回。
4寄存器規則
(1)必須保存任何被函數修正的專用寄存器。專用寄存器包括:
①AR1,AR6,AR7
②堆棧指針(SP)
若對SP正常使用,不需要明顯的保存。換句話說,只要任何壓入堆棧的東西在函數返回之 前被彈回(因而保存了SP),匯編函數就可以自由的使用堆棧。任何非專用的寄存器都可以自由地使用而無需將他們保存。
(2)中斷函數必須保存他使用的所有寄存器。
(3)ARP在函數進入和返回時,必須為0,即當前輔助寄存器為AR0。函數執行時可以為其 他值。
(4)在默認的情況下,編譯器總是認為OVM為0。因此,若在匯編程序中將OVM置為1,則返回C/C++環境時,必須將其恢復為0。
(5)在默認的情況下,編譯器總是認為CPL為1。因此,若在匯編程序中將CPL清0,則在返回C/C++環境時,必須將其恢復為1。
(6)長整數和浮點數存儲在存儲器中的方法是最高有效字在低位地址。
(7)函數必須按前面有關被調用函數響應中所述的方法返回值。
(8)除了全局變量的初始化外,匯編語言模塊不能以任何目的使用cinit段。在boot asm中的C/C++啟動程序假定cinit段完全由初始化表組成。將其他的信息放入cin it中將使初始化表產生混亂,并將產生不可預期的結果。
(9)在匯編語言模塊中,對可以從C/C++中訪問的變量和函數名需加上前綴“_”。對于僅用于匯編語言模塊中的標識符,應不得用下劃線開始。
(10)任何在匯編語言模塊中聲明的將要從C/C++訪問或調用的對象或函數,都必須在匯編語言中用global偽指令聲明為全局變量。
5編程實例
以32 b乘法運算為例。雖然用C/C++語言表達32 b乘法運算較為方便和明了,但由于C/C++語言無法很好利用DSP匯編語言為實現各種乘法運算而提供的指令,而使得C/C++程序效率低下。所以這里用匯編語言完成32 b乘法運算,再用C/C++程序調用他。
5.1算法簡介
由于16 b定點DSP中沒有32 b乘法指令,所以一定要用幾種16 b乘法指令結合一定算法來進行32 b乘法運算。一個32 b數在存儲器中是分開存儲的。高16位存放在低地址,他在進行乘法運算是可以看作一個16 b有符號數;低16位存放在相鄰的低地址,他進行乘法運算時可以看作一個16 b無符號數。于是算式如下:
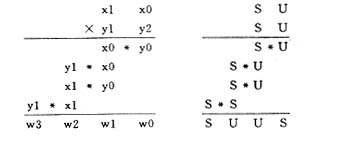
其中:S代表符號數;U代表無符號數。
由上算式可見,在32 b乘法運算中,實際上包含了3種乘法運算:U*U,S*U和S*S 。一般的乘法運算指令都是兩個帶符號數相乘,即S*S。所以在編程時,還要用到以下兩條乘法指令:

5.2C語言主程序
在主程序中進行MPY32函數調用時,函數傳遞情形如圖2所示。
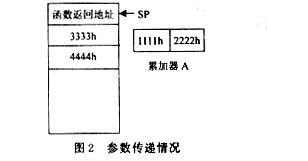
從圖2可以看出,函數MPY32的第一參數存放在A累加器中,第二個參數在堆棧中,高16位在堆棧中的低地址,低16位在堆棧中的高地址。由于MPY32是匯編語言函數,所以編譯器不為其分配局部幀,局部幀的分配在匯編程序中進行。
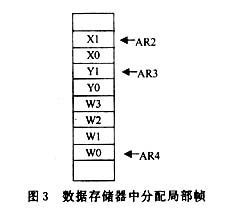
5.3匯編程序
可以看出,在匯編程序中至少要為局部幀分配8個單元,其中4個單元用來存放參數值,4個單元用來存放運算結果,如圖3所示。
匯編函數:




6結語
本文介紹的混合編程方法不但適用于TI 5000系列DSP,同樣也適用于TI其他系列的DSP,如2000系列、6000系列,甚至對其他芯片,如51系列單片機,實現混合編程也有很大參考價值。值得注意的是,為了使混合編程不破壞C語言的結構性,在匯編語言中不要設置除函數名之外的任何全局變量。
16-bit定點DSP
C55x有雙MAC單元;C54x有單MAC單元
C55的指令長度可變,且沒有排隊的限制
C55x有12組總線;C54x有8組總線
二、綜合介紹
C5000是16-bit定點DSP系列,包括舊有的C5x、當前主流的C54x和最新的C55x。
C55x和C54x源代碼兼容,而C5x和C2x源代碼兼容。C54x關注于低功耗,而C55x則將低功耗提到一個新水平:300MHz的C55x和120MHz的C54x相比,性能提高5倍,而功耗則降到六分之一。盡管C5x還在全線生產,但公司已經將新設計轉向C54x 和C55x。C54x 和C55x采用改進的哈佛結構。
C55x 具有12組獨立的總線,而C54x則有8組。它們都有一組程序總線和相應的程序地址總線。C54x總線的寬度為16-bit,而C55x總線的寬度為32-bit。C55x有三組數據讀總線和兩組數據寫總線,而C54x有兩組數據讀總線和一組數據寫總線。每組數據總線都有其相應的地址總線。C55x的數據地址總線的寬度為24-bit,而C54x的數據地址總線的寬度為16-bit。
C54x使用兩個輔助寄存器算術單元,在每個周期內產生一個或兩個數據存儲器地址。這四組內部總線和兩個地址發生器使其可以進行多操作數運算。
C55x的地址-數據流單元(ADFU)包含了專門的硬件來管理五組數據總線。該ADFU也可以作為通用的16-bit ALU,用于簡單的算術運算。該ALU從指令緩沖單元(IU)接收立即數,和存儲器、ADFU寄存器、數據計算單元(DCU)寄存器、程序流單元(PFU)寄存器作雙向通信。無論是ALU,還是三個地址寄存器ALU(ARAU)中的一個,都可以修改作間接尋址的九個地址寄存器。這三個ARAU為C55x的三組數據讀總線提供獨立的地址。這種并行性保證了在每個CPU周期內DCU去讀兩個16-bit的操作數和一個16-bit的系數。
C55x的DCU包含了兩個MAC單元,在單周期內作兩個17217-bit的MAC運算。它還包含了一個40-bit的ALU和四個40-bit的累加器寄存器、一個桶型移位器、以及專門的Viterbi算法硬件。每個MAC單元包含一個乘法器和帶32-或40-bit飽和邏輯的加法器。三個數據讀總線將兩個數據流和一個公共系數流送給兩個MAC單元。用戶可以用ALU作32-bit的運算,或分開作兩個16-bit的運算。除開接受從DCU的40-bit Acc寄存器來的輸入外,ALU還從IU接受立即數,并和存儲器、ADFU寄存器、PFU寄存器作雙向通信。
C54x是單17217-bit MAC機器,有一個40-bit的加法器、兩個40-bit的Acc和一個分開的40-bit的ALU。與C55x相類似,C54x的ALU也可以作成兩個16-bit的配置,完成兩個單周期運算。乘法器輸出處的40-bit的加法器允許作非流水的MAC運算,以及并行的兩個加法和乘法。單周期歸一化和指數編碼支持浮點數運算。
兩個系列的結構都支持一個桶型移位器,將40-bit的Acc的值左移或右移最多達31bit。該桶型移位器將移位后的值送給DCU的ALU,以便作進一步的運算。指令集中關于二操作數、三操作數和32-bit操作數的指令,支持結構的并行性。八個可以獨立尋址的輔助寄存器和軟件堆棧提高了C編譯器的效率。
C55x可以執行可變長度的指令,這和C54x有顯著的不同。C54x的指令長度為固定的16-bit,而C55x的指令長度則從8到48 bit。C55x的IU緩存64 byte的代碼,且有一個解碼邏輯來確認可變長度指令中各指令的區別。局部循環指令使用指令緩沖隊列來循環執行代碼塊。指令緩沖隊列還可以在執行條件程序流控制指令的條件測試時,推測性地提取指令。指令解碼器按排列順序對指令解碼,而不是執行動態時序,從而可以在預定的時間得到結果。
C55x的PFU跟蹤程序的執行點,并為多達16Mbyte的程序存儲器產生24-bit的地址。該單元的硬件,可用于循環、靈活性轉移、條件執行、以及流水保護。單獨的程序計數器可以保證從子程序或中斷服務子程序快速返回。該PFU還包括管理指令流水和四個CPU狀態寄存器的邏輯。它以硬件方式可以提供四層塊循環嵌套。其硬件還支持條件循環。PFU處理流水控制冒險,并對讀后寫及寫后讀提供保護。當在指令流中這種冒險發生時,流水保護邏輯就插入一些周期,保證程序的正確執行。集成的軟件等待狀態發生器使用戶可以使用較慢的外部存儲器。
該系列的所有DSP都支持片內雙訪問RAM(DARAM),用戶可以將其配置為程序存儲器或數據存儲器。C55x還有擴展的同步突發性RAM、同步DRAM和異步SRAM及DRAM。片內的鎖相環(PLL)允許用戶抑制時鐘,但C55x核還可以激活與自動管理片內外設和存儲器的功耗。當程序不再訪問片內存儲器時,它們就會被切換到低功率模式。處理器對片內外設也提供類似的控制。
C55x還設置了用戶可控的低功率IDLE域,包括CPU、DMA、外設、外部存儲器接口、指令隊列、以及時鐘發生電路。
三、尋址模式
C54x支持單數據存儲器操作數尋址和32-bit操作數尋址,還使用并行指令支持雙數據存儲器操作數尋址。它也提供立即數尋址、存儲器映射尋址、循環尋址和位倒序尋址。
在C54x的基礎上,C55x還支持絕對值尋址、寄存器間接尋址、直接尋址,即位移模式。C55x的ADFU包括專門的寄存器,支持使用間接尋址指令的循環尋址。可以同時使用五個獨立的循環緩沖器和三個獨立的緩沖器長度。這些循環緩沖器沒有地址排隊的限制。C54x支持兩個任意長度的循環緩沖器。
四、特殊指令
C54x有專門功能指令,如FIR濾波器、單指令或塊指令循環、八個并行指令(如并行存儲或乘加)、乘法累加和減(十個乘法指令)、八個雙操作數存儲器搬移。C55x還有專門的指令,充分利用增加的功能單元和并行能力的優點。用戶定義的并行機制,允許將執行兩個操作的指令加以組合。
五、開發支持
eXpressDSP軟件技術包括DSP集成開發工具:可升級的實時軟件基礎、可重復使用的應用軟件接口標準、以及不斷增加的第三方的軟件模塊。Code Composer Studio是一個集成的DSP開發工具套件,包括C5000的C編譯器、DSP/BIOS、實時數據交換技術等]]>