電力工業的迅速發展、電力系統的復雜化以及保護要求的提高,促進了微機繼電保護的迅速發展,尤其是高度智能化、數字化的微機保護裝置在電力系統的應用不斷擴大。微機繼電保護裝置除了擁有傳統的繼電保護裝置基本的測試功能外,還具有強大的數據處理能力和通信能力,其優越性在電力系統實際應用中得以體現。電力系統對于繼電保護的可靠性、選擇性、靈敏性和快速性都有很高的要求,而采用單CPU結構的繼電保護裝置,其缺點是容易造成任務之間的沖突并且會引入等待周期。在微機繼電保護方面,數字信號處理器(Digital Signal Processor,即DSP)由于其突出的處理能力而受到青睞。此外DSP還具有內存大、兼容性好等特點。隨著性能的提高和價格的下降,DSP在自動控制、信息處理、通信以及儀器儀表等領域中得到廣泛應用。本文以DSP為核心,提出了采用雙CPU模塊化設計的微機型繼電保護裝置。設計方案中使用型號為TMS320C6203B的DSP芯片,它是TMS320C6000系列DSP芯片的一種,片內程序存儲器不僅在容量上進行了擴展,而去片內程序RAM分為2個存儲塊。此外該芯片還具有處理性能更好、外設集成度更高、A/D轉換速度更快等優點,在控制方面得到廣泛應用。
1裝置硬件結構設計
1.1保護CPU與監控CPU
保護裝置硬件部分以保護CPU和監控CPU為核心模塊,來完成相關的功能。DSP是一種具有特殊結構的微處理器。與單片機比,哈佛結構、流水線操作、獨有的硬件乘法累加操作、特殊的指令和特殊尋址模式、零消耗循環控制以執行時間的可預測性是DSP突出的特點。此外,DSP片內有多總線,片外的地址、數據總線分開,高速的同步串口或通信口等優點,因此數據輸入/輸出能力很強,吞吐量大,在進行數字信號處理時不僅速度快,精度也高。
保護CPU的主要任務包括:(1)控制A/D采樣系統及開關量輸入;(2)對采集的數據進行數字濾波,并對濾波后的數據進行各種保護算法操作;(3)與監控CPU進行通信,完成處理結果的傳送。
監控CPU在執行動作則承擔整個系統的控制、通信、存貯的功能,借助操作系統處理各種復雜任務,管理各種外設,監控整個系統的運行狀況,為整個微機保護裝置提供高效率的處理平臺。硬件基本模塊如圖1所示。
1.2雙CPU之間的通信
裝置中保護CPU與監控CPU之間的通信是主要解決的問題。在本裝置中采用的是利用高性能雙口RAM來構成高速數據傳送接口的方案。雙口RAM 是一個共享式多端口存儲器,具有兩套完全獨立的數據線、地址線和讀寫控制線,并允許兩個獨立的系統同時對該存儲器進行隨機性的訪問。保護CPU與監控CPU雙方之間按照一定的通信協議,同時通過雙口RAM完成數據的讀取或存儲,對數據進行分析后完成彼此命令的交互并執行相應保護處理子程序。保護裝置中的雙口RAM采用美國IDT公司開發研制的IDT70V24來構成。IDT70V24是3.3V高速4K×16bits的雙口靜態RAM,最快存取時間可達15ns,可與大多數高速處理器配合使用,在讀、存數據時不用插入等待狀態。雙CPU通信電路如圖2所示。
1.3其他模塊的設計
除了核心控制模塊外,裝置中還必須帶有模擬量采集模塊、開關輸入輸出模塊、通信及總線模塊以及人機接口模塊。模擬量采集模塊的組成部分為濾波電路、采樣保持電路、A/D轉換模塊、過零檢測等單元回路組成。對于分布式的變電站自動化系統,聯系各智能裝置的計算機通信網絡是整個系統的關鍵。因此,除了一般的保護硬件模塊以外,本裝置還設計了RS232和RS485以及CAN通信接口。這些通信接口的引入,可以滿足新的通信技術和網絡技術在電力系統及微機保護應用中的要求,便于實行變電站綜合自動化管理。其中RS232接口和上位機相連,主要用于調試和下載程序,而RS485接口可用作GPS對時接口和聯網通信接口。DSP與RS485的通信接口電路如圖3所示。
2相關軟件設計
2.1程序結構
整個保護程序包括主程序和定時中斷程序兩部分。主程序完成整個保護裝置的基本功能,包括保護裝置的初始化、自檢、數值處理、故障判斷、出口動作等模塊;中斷服務子程序包括定時采樣A/D轉換、電氣量計算、相關數據記錄、鍵盤中斷及串行通信中斷等模塊。主程序和中斷程序結構如下:
2.2開發環境
由于裝置采用雙CPU結構,根據兩塊CPU各自完成的功能,可將軟件設計成兩大部分,分別用來完成保護CPU的保護工作和監控CPU的監控與通信工作。為了方便程序的維護,及其在硬件平臺的相互移植,因此本裝置中對保護CPU的程序采用匯編語言編寫,而監控CPU的相關程序則使用C語言編寫。
TMS320C6203B系列DSP的開發環境與一般微處理器的開發環境類似,其特點是包括C優化編譯器、編程接口界面友好、具有產生代碼能力的C/匯編語言源調試器、軟件仿真器、實時硬件仿真器、擁有實時操作系統以及大量的應用軟件。整個DSP程序可以選擇在CCS2.0(即Code Composer Studio(代碼調試器)2.0)集成環境下設計。CCS2.0提供了強大的仿真功能,可支持多種控制模式,同時支持匯編和C語言的調試。
3結語
在電力系統中,微機繼電保護的設計逐漸順應著計算機化、網絡化,集保護、控制、測量、數據通訊與一體和人工智能化的發展趨勢。本保護裝置軟硬件均采用模塊化設計,結構清晰,并且具有靈活的通信功能,可直接與PC機進行RS232串行通信。可以看出采用DSP的雙CPU模式的微機繼電保護裝置,能充分利用DSP高速處理數據的能力,同時也能突顯出處理外部中斷及對外設部件的控制能力。裝置配置了高速RS485總線和CAN現場總線,在規定一定的通信協議后,便于實行變電站綜合自動化管理。
]]>
關鍵詞 視頻設備驅動程序 TMS320F2812 DSP/BI0S GIO/FVID模型
引言
隨著時代的發展,DSP技術在遠程監控、可視電話、工業檢測等視頻處理領域得到了廣泛的應用,對于不同的視頻處理系統,會使用不同的視頻設備,所以有必要為視頻沒備設計驅動程序,為高層應用程序提供統一的接口來操作底層硬件。只要是遵循此驅動程序接口標準開發的高層應用程序,都可以在具有相同接口的不同硬件平臺上運行,具有很好的通用性和可移植性。同時高層應用程序設計人員只要會使用設備驅動程序提供的API接口,就不必了解底層硬件的具體實現,可以大大提高整個視頻系統的開發效率。
對于視頻設備,TI公司也提出了對應的視頻設備驅動程序模型,但這些模型主要是針對6000系列高端DSP,甚至是DM64X這樣的視頻處理專用DSP設計的。而TMS320F2812(簡稱F2812)DSP這樣的低端處理器,內部存儲空間較小,且沒有DM64X那樣專用的視頻接口。本文針對這類問題,提出了對TI視頻驅動模型進行簡化和改造的方法,使視頻設備驅動程序占用盡量少的系統資源,來完成對視頻硬件設備的操作。這種視頻驅動模型的裁減方法,對于使用低端處理器的視頻處理系統具有借可鑒性。
1、基于DSP/BIOS的外設驅動開發模型
TI公司為開發DsP的外設驅動程序,推出了DSP/BIOS Device Driver kit,定義了標準的設備驅動模型,并提供了一系列的API接口。如圖1所示,外設驅動程序分為兩層:
①類驅動(class driver)。類驅動程序用來為應用程序提供接口。這部分程序與設備無關,主要功能包括維護設備數據緩沖區,向上提供API接口供應用層程序調用,并協調應用程序對外設操作的同步和阻塞;向下提供適配層與迷你驅動層相連,實現API接口函數到迷你驅動層程序的映射。類驅動程序與硬件無關,只要外設驅動模型選定了,類驅動程序就定下來了,不需要做多少修改。
②迷你驅動(mini driver)。迷你驅動程序與設備相關,所以設計迷你驅動程序是外設驅動開發中的重點。迷你驅動程序與類驅動層的接口格式是統一的,但迷你驅動程序對底層硬件的操作是根據硬件平臺的不同而變化的。迷你驅動接收類驅動層發出的IOM_Packet命令包,決定對底層硬件進行什么樣的操作。
外設驅動程序模型又可以分為以下3類:
①PIP/PI0模型。基于數據管道的I/O模型,每個管道都在維護自己的一個緩沖區。當數據寫入緩沖區,或從緩沖區取出數據時,便會激發notifyReader和notifyWriter函數實現數據的同步。
②SIO/DIO模型。基于數據流的I/O模型,一個數據流是單向的,要么是輸入,要么是輸出,而且SIO/DIO模瓔使用異步方式來操作I/0,對于數據的讀寫、處理可以同時進行。
③GI0模型。通用的I/O模型,靈活性很強,且沒有適配層,直接操作迷你驅動程序,主要用來設計新型的設備驅動模型。

2、視頻處理系統硬件平臺
硬件平臺如圖2所示。系統以TI公司的F2812 DSP作為中心處理器,以模擬攝像機進行視頻信號采集,再使用SAA7111視頻解碼芯片將其轉換為BT601格式的數字視頻信號。DSP將數字視頻信號處理后,再寫入輸出幀緩存AL422中,并控制視頻編碼芯片ADV7177,將其轉換為模擬電視信號輸出。整個系統以l片CPLD——IspMachLC4128來協調各個芯片之間的時序關系。
系統由Camera Link接口模塊、以FPGA為核心的圖像采集預處理與傳輸單元、以DSP為核心的圖像壓縮單元以及RS422遠距離數據傳輸單元組成。由于采集、處理均需要訪問存儲器,為了降低成本,采用普通的異步SRAM,按功能區分可分為采集SRAM和壓縮處理SRAM。讀寫邏輯由FPGA控制,采用乒乓機制進行切換。整個系統結構如圖1所示。

系統工作過程:圖像信號經由LVDS轉換芯片后轉換成LVTTL信號,直接傳送至FPGA解碼為8位數據,以字節方式一行一行寫入SRAM靜態存儲器(存儲器由兩部分組成),用于乒乓緩存輸入數據,每部分滿1幀后由FPGA控制送出幀中斷給DSP,DSP啟動EDMA讀入1幀數據,采用JPEG2000方式編碼后連續寫入到FIFO_OUT,FPGA負責從FIFO_OUT讀出數據,非空即讀,緩存積累不會超過1幀數據。讀出的數據另行打包后以9 Mb/s的碼率通過DS26LV31 422接口芯片從out1接口輸出,或者分流后從out1和out2以各4.5 Mb/s的碼率輸出。
2 FPGA功能模塊設計
2.1 Camera Link接口模塊
Camera Link接口模塊負責對高頻幀數字攝像頭輸出的LVDS信號轉換為TTL標準信號。
關于Camera Link的采集數據的邏輯代碼,關鍵之處在于產生存儲器的地址信號、存儲器寫信號以及在對應的地址處將數據穩定地寫進存儲器。本系統用像素時鐘產生列地址計數器、行同步信號產生行地址計數器,兩者拼接產生存儲器的地址信號。這樣產生的有效地址雖然不連續,但意義明確,而且有利于顯示部分的隔行隔列顯示。對于8 bit的數據,可將2個有效數據拼接成16 bit后再存儲,這樣可以提高FPGA讀寫存儲器的速度。
Camera Link接口時序如圖2所示。

圖2中:VD為幀同步信號,電平模式,高電平有效;HD為行同步信號,脈沖模式,上升沿有效;PCLK為像素同步時鐘,脈沖模式;DATA為10 bit圖像數據,在PCLK的下降沿推出,接收端在PCLK上升沿采集,PCLK為常運行模式。每個VD有效期內有480個HD有效信號,在第0~478個HD有效時,每個HD有效期間有600個有效圖像數據,第479個HD(即每幀的最后1行)有效時,前600個DATA為有效圖像數據,600個DATA后預留6個字節輸出圖像相關信息,即第D600~D605為預留字節。
2.2 SRAM乒乓緩存
在圖像采集處理系統中,DSP的壓縮算法在實現時間上往往并不是固定不變的,然而前端的采集模塊卻使用均勻速度對圖像進行采集,這樣存在時間上的不同步,有可能會導致圖像數據的丟失和影響幀數據的完整性[2]。為此,本系統在采集和壓縮模塊之間增加1個緩沖電路來解決這一問題。
常用的緩沖電路主要有3種[3]:雙口RAM結構、FIFO結構和乒乓結構。由于乒乓結構可以使用相對比較便宜的高速大容量SRAM,而且可以實現數據的連續性,因此本系統采用了乒乓結構雙SRAM作為視頻數據的緩沖。在將1幀圖像的數據全部存儲完以后,DSP再利用很短的時間直接將1幀圖像數據讀入片內,這樣既可以保證不丟失像素數據、DSP可以連續采集每1幀像素數據,又能為DSP留出更多空余時間,為后面進行圖像處理提供可能。為了實現數據幀的完整性,必須保證讀取數據幀的優先級要高于寫數據幀的優先級,所以本系統的數據輸入輸出單元是根據數據處理流程來進行切換的。
乒乓控制模塊按照功能還分為:S0、S1、S2、S3 4個轉換狀態。其中,狀態S0為初始化狀態(所有信號都處于初始化狀態),系統加電或者復位后進入此狀態;在S1狀態,主要負責對SRAM0的寫入,不可以對SRAM1進行讀操作;在S2狀態,主要負責對SRAM1進行寫操作,對SRAM0進行讀操作,當SRAM1寫完后,如果SRAM0未讀完,則繼續處于狀態S2,如果SRAM0讀完,則進入狀態S3;在S3狀態,主要負責對SRAM0進行寫操作,對SRAM1進行讀操作,當SRAM0寫完后,如果SRAM1未讀完,則繼續處于狀態S3,如果SRAM1讀完,則進入狀態S2。乒乓控制模塊狀態轉換圖如圖3所示。

SRAM乒乓電路如圖4所示。圖中,wr_data為Camera Link接口接收到的只包含灰度信號的圖像數據。為了方便圖像數據的管理,每個像素、每行的像素都對應到了SRAM的固定地址,所以wr_addr為該像素在SRAM中的地址,同時也可以表示該像素在一幅圖像中的位置。CHANNEL_SEL為讀SRAM的標志位,0代表SRAM0,1代表SRAM1。

2.3 FIFO緩存模塊和RS422傳輸模塊
由于DSP向RS422模塊傳輸數據并不是勻速傳輸,而且傳輸速度比RS422的傳輸速度快很多倍,所以必須采用FIFO模塊。
3 DSP程序設計
TI公司的TMS320DM642芯片是一款高性能視頻處理器,其主頻可以高達600 MHz,數字處理能力可以達到4 800 MI/ps[3]。
DSP工作流程圖如圖5所示,DSP在相關外設與EDMA相關寄存器初始化完成后,才開始響應中斷事件觸發EDMA傳輸,在本系統中由EXITUINT4中斷上升沿觸發EDMA進行傳輸。在接收到FPGA發送的中斷信號后,開始進行EDMA傳輸,整個EDMA傳輸的過程需要10 ms左右,傳輸完成后觸發EDMA中斷,在中斷服務函數中觸發1個軟中斷,在軟中斷服務函數中進行圖像數據的壓縮。

3.1 EDMA乒乓程序設計
在整個DSP的工作流程中,要實現圖像數據采集、壓縮、傳輸同時進行,則在DSP程序中需要1個雙緩沖buffer,在向buf1中采集圖像信號的時候,DSP可以對buf2中的數據進行壓縮,而在對buf2中進行采集的時候,DSP可以對buf1中的數據進行壓縮。
實現這個功能的方法是采用EDMA ping_pong方式。在DSP中使用hEdmaPing和hEdmaPong雙通道EDMA并建立PingBuffer和PongBuffer兩個數據存儲區。 當寫完1幀圖像后,FPGA發送EXTINT4中斷信號啟動hEdmaPing將數據搬移到PingBuffer,同時將通道鏈接至hEdmaPong。在下一個中斷事件發生時將數據搬移到PongBuffer中,CPU在hEdmaPong通道完成中斷服務程序中鏈接hEdmaPing通道。如此往復,使系統數據搬移和處理連續進行。
3.2 DSP/BIOS調度程序設計
僅僅采用EDMA乒乓方式進行EDMA數據傳輸還是不夠的,不能實現數據的采集和壓縮同時進行,還需要DSP/BIOS調度程序。在任務、硬件中斷、軟件中斷中進行調度,在軟中斷服務函數中進行圖像壓縮任務。
DSP/BIOS是TI公司所設計開發的、尺寸可裁剪的實時多任務操作系統內核,通過使用DSP/BIOS提供的豐富的內核服務,開發者能快速地創建滿足實時性能要求的精細復雜的多任務應用程序。
DSP/BIOS程序編寫過程如下:
(1)在DSP/BIOS配置面板中添加1個軟中斷jpeg_swi,并將該軟中斷的服務函數設置為jpeg。
(2)添加軟中斷服務函數jpeg();代碼如下:
void jpeg(void)
{
Uint32 i;
if(pingpong)
bitstream_length=my_jpegenc->fxns->encode(my_jpegenc,(XDAS_Int8**)buf0,output_bitstream_buffer);
else
bitstream_length=my_jpegenc->fxns->encode(my_jpegenc,(XDAS_Int8 **)buf1,output_bitstream_buffer);
submit_qdma();
while(!(EDMA_getPriQStatus()&EDMA_OPT_PRI_HIGH));
}
(3)在EDMA中斷服務函數中添加如下代碼:
SWI_post(&jpeg_swi);
該函數的作用是觸發jpeg_swi軟中斷。
4 系統關鍵技術
4.1 時鐘
在使用內部生成的時鐘過程中,可能引起設計上的功能和時限問題。組合邏輯產生的時鐘會引入毛刺,造成功能問題,而引入的延遲則可能會導致時限問題。
本設計中用到很多全局時鐘的整數倍分頻,且由于分頻的整數倍較大,如果利用FPGA中自帶的DCM模塊很難實現這樣的功能。因此,采用同步計數器的分頻方法,并且在各個時鐘信號輸出之前,再加一級寄存器輸出,這樣的操作就避免了組合邏輯生成的毛刺被阻擋在寄存器的數據輸入端口上。
4.2 DSP與FPGA數據交換
由于壓縮算法采用MECOSO公司的JPEG壓縮算法,經過優化和處理后,壓縮1幅圖像僅需要4 ms。所以影響整個系統能否實現高頻幀的關鍵技術是EDMA向SDRAM中搬移數據的速度,在本設計中設幀圖像的大小為600×480=288 KB,傳輸1幅圖像所需的時間需要10 ms。影響其速度主要有2個因素:EMIF所使用的ECLOCK和EMIF相關設置的寄存器。
在本系統中,ECLOCK采用了DSP的CPU4分頻,使EMIF的CLOCK工作在150 MHz,大大提高了搬移速度。由于SRAM映射在DSP的CE2空間,考慮到讀取數據需要建立(setup)、選通(Strobe)和保持(Hold)3個步驟,故將CE2相關寄存器的建立時間和選通時間選擇為1個clk,經Hold時間設置為0。這樣設置后EMIF總線的數據吞吐量為:

本文設計的圖像壓縮系統實現了分辨率為600×480、幀頻率為100幀/s的視頻信號輸入的圖像采集,并能夠進行實時的JPEG壓縮。系統采用DSP+FPGA的方案,雖然是一種較常用的組織方式,但在該系統中解決了一些關鍵的問題,大大提高了圖像壓縮速度及系統的靈活性。本系統已經應用于航天領域某監測系統,效果良好,運行穩定。
| 以下內容含腳本,或可能導致頁面不正常的代碼 |
|---|
| 說明:上面顯示的是代碼內容。您可以先檢查過代碼沒問題,或修改之后再運行. |
1 引言
在極低譜密度,高頻譜利用率的大容量無線傳輸技術中,高速實時信號處理成為技術的 關鍵。目前市場上,能滿足對高速實時信號處理的需要有具有良好的可編程性的器件主要有 DSP 和FPGA。
TMS320C6000 系列DSP 是TI 公司推出的一種高性能的數字信號處理器,包含定點和浮 點兩個系列,其中定點系列包括TMS320C62xx 和TMS320C64xx,浮點系列包括TMS320C67xx。 C6000 系列DSP 有三種啟動方式:
(1) 主機啟動
如果選擇主機啟動模式,在復位信號結束后,DSP 的CPU 被內部“阻塞”而其他部分都 被釋放。在此期間,一個外部的主機在必要時可以通過主機接口初始化CPU 的內存空間,包 括配置與啟動相關的內部寄存器。一旦主機完成了所有必須的初始化,它必須將HPIC 寄存 器的DSPINT 位置“1”來完成啟動過程。在程序加載完后,CPU 被從“阻塞”中喚醒,然后 從地址0 處執行指令。在CPU 被喚醒后,CPU 需要將DSPINT 位清零[1]。
(2) ROM 啟動
如果采用ROM 啟動模式,則C6000 系列的DSP(C621x/C671x/C64x)復位后自動從CE1 空間的起始處拷貝1K 字節的代碼到內存空間。該拷貝過程由EDMA 完成,使用默認的Rom 時鐘。在此過程中CPU 一直處于“阻塞”狀態,直到拷貝完成后才被被喚醒,然后從地址0 處開始執行程序[1]。
(3) 無啟動
如果選擇無啟動模式,CPU 復位后直接從地址0 處開始執行指令。 C6000 系列DSP 的器件配置情況決定了選擇的啟動方式。具體來說就是DSP 的啟動模式 管腳(boot mode pins)接上拉還是下拉電阻。以C6416 為例,BEA[19:18]是啟動模式管 腳,它們取不同的值(上拉電阻代表“1”,下拉電阻代表“0”)代表的含義如表1-1 所示:
如果DSP 的程序小于1K 字節,那么上述ROM 啟動機制已經可以完成程序的加載。然而 事實上大部分DSP 的程序會大于1K 字節,這時就需要創建一個特定啟動程序來完成更多代 碼的加載。該特定啟動程序又被稱作二級bootloader[2]。
在需要二級bootloader 的程序中,這段特定啟動代碼通常駐留在ROM 存儲器的起始位 置以便在DSP 復位后能自動被加載到內存地址0 處。當1K 字節代碼被加載完畢后,CPU 開 始從地址0 處執行,也就是執行二級bootloader 的內容。二級bootloader 的功能就是將程 序的剩余部分拷貝到內存中。
2 啟動方法的設計與實現
采用二級bootloader 的DSP 啟動方法的實現大體分為四步:配置存儲器;編寫 secondary bootloader 代碼;編譯程序,轉換目標文件的格式;將程序燒寫進FLASH。圖1 為實施該啟動方法的硬件平臺示意圖,其中DSP 的型號選擇C6416,FLASH 的型號選擇 AM29LV800B。
2.1 配置存儲器
2.1.1 定義存儲器分區
為了實現使用二級bootloader 的ROM 啟動,需要將FLASH 劃分為FLASH_BOOT, FLASH_REST 兩個區。這兩個區分別存儲由on-chip bootloader 拷貝的程序段和由secondary bootloader 拷貝的程序段。對于BIOS 程序,Memory 段的定義在MEM(Memory Section Manager)對象里。對于非BIOS 程序,Memory 段定義在linker command file 中。一個C6416 的Memory 段定義的例子如下所示:
]]>
隨著測試技術的不斷發展,低功耗、高性能的DSP逐漸取代了通用單片機在數據采集處理系統中的地位;同時,以太網技術也在數據采集、測試測量技術中發揮越來越大的作用。本文從軟件、硬件出發,介紹一種基于DSP和以太網的數據采集處理系統的設計思想及實現。
1 基于以太網的數據采集處理系統
生產和科研領域對測試的要求越來越高,所需測試和處理的數據量也越來越巨大,有時需要多個測試儀器同時進行測試,各測試儀器之間又需要進行數據交換;而且測試領域也越來越廣泛,有些現場不適合工作人員親臨,這時就需要通過網絡進行控制。以太網技術在數據采集處理系統中的應用如圖1所示。
與工業現場應用比較多的現場總線比較,以太網最大的特點是開發性好、成本低。通過把復雜的TCP/IP協議封裝而提供各種網絡測試技術,使網絡測試的開發變得不再復雜。同時,由于網絡測試帶來巨大效益,使網絡測試在測試自動化領域得到廣泛應用。以太網作為分布式測試的一個網絡方案,其潛力無疑是巨大的。

圖1 數據采集處理系統中的以太網應用
以太網接口控制器和DSP微處理器的價格不斷下降,使得將以太網直接集成到基于DSP等嵌入式系統的測試、采集、工業I/O設備中成為越來越明顯的趨勢。基于以太網的I/O設備是將以太網接口直接嵌入到設備內部,所以使得設備更簡潔,體積更小,安裝也更靈活。和一些目前應用于工業的其它通信方案比較,以太網方式通常需要功能更強大的微處理器和更大的內存。而網絡和計算機技術的發展,特別是DSP技術的應用,可以大大降低這方面的成本。
2 數據采集處理系統的硬件設計
該系統以TI公司的TMS320C6000系列DSP中的TMS320C6211和10/100M自適應以太網控制芯片MX98728EC為核心,主要包括ADC數據采集、DSP數據處理和以太網接口三個部分。圖2為數據采集處理系統框圖。
2.1TMS320C6000DSP
TMS320C6000是美國TI公司于1997年推出的新一代高性能DSP芯片。這種芯片是定點、浮點兼容的DSP。其定點系列是TMS32C62XX,浮點系列是TMS320C67XX。TMS320C6000片內有8個并行的處理單元,分為相同的兩組,芯片的最高時鐘頻率可以達到300MHz。當芯片仙部8個處理單元同時運行時,其最大處理能力可以達到2400MIPs。本數據采集處理系統采用TMS320C6211,其主要特別如下:
相±
·每個周期8條32位指令
·8個高度獨立的功能單元,包括6個32/40位的運算器和2個16位的乘法器(32bit結果)
·32個32位通用寄存器

圖2 數據采集處理系統框圖
·靈活自由的數據/程序定位,L1/L2存儲器結果:4K字節L1P程序Cache、4K字節的L1D數據Cache、64K字節L2通用RAM/Cache
·32位外部存儲器接口(EMIF):對異步存儲器的無縫接口,如SRAM、EPROM;對同步存儲器的無縫接口,如SDRAM、SBSRAM;共512M字節外部存儲器可尋址空間
·增強的DMA(EDMA控制):16個獨立通道
·兩個32位通用定時器
·支持JTAG邊界掃描標準,調試時可以方便可靠地控制DSP上面的所有資源
2.2以太網控制器MX98728EC
MX98728EC是一個通用的單片10/100M快速以太網控制器,通過它的主機總線接口,可以實現各種各樣的應用,而不需要或者只需極少的外部控制邏輯。單片機的解決方案可以減小電路板的尺寸,減少板上芯片的數量,以降低系統的成本。MX98728EC的特點如下:
·32位通用異步總線結構,支持頻率最高達33MHz
·單片解決方案,集成了10/100MTP收發器
·可選的外部收發器MII接口
·完全兼容IEEE802.3u協議
·支持16/8bit打包緩沖數據寬度和32/16bit主機總線數據寬度
·分離的TX和RXFIFO,支持全雙工模式,獨立的TX和RX通道
·豐富的片上寄存器,支持各種各樣的網絡管理功能
·支持16/8bit的用于打包緩沖器的SRAM接口、支持片上FIFO的突發DMA模式
·自動設置網絡速度和協議的NWAY功能
·可選的EEPROM設置,支持1kbit和4kbit的EEPROM接口
·支持軟件EEPROM接口,方便升級EEPROM的內容

圖3 DSP和以太網接口部分硬件設計
2.3系統結構
2.3.1ADC數據采集部分
CPLD1由DSP提供時鐘信號,主要作用是提供掃描表SRAM的地址,掃描表SRAM的數據由DSP寫入。掃描表輸出的數據用來設定A/D轉換的通道和儀表放大器的增益。ADC采用14位的LTC1416。32路模擬信號通過多路復用器后,其中一路信號被選中,進入儀表放大器,放大之后進入ADC。ADC的轉換時鐘由DSP的定時器提供。
2.3.2DSP數據處理部分
ADC轉換后的14位數據通過FIFO進入DSP進行處理,FIFO采用4片CY7C425形成乒乓結構,以實現模擬信號的不間斷采樣。DSP擴展一片FlashMemory作為DSP的程序存儲器,另外還擴展了一片SRAM作為程序緩存。脫機運行時,DSP將Flash中的程序寫入SRAM,再寫入DSP內部RAM。CPLD2主要用于控制FIFO的讀寫,并且提供以太網接口部分的控制信號。DSP系統中的數字信號處理算法主要實現濾波、采樣率變換、非線性修正、溫漂修正等。
2.3.3以太網接口部分
以太網主控芯片MX98728EC通過RJ45接口連接以太網,擴展一片SRAM作為以太網數據收發存儲器,另外又擴展一片EEPROM以存儲以太網卡的MAC地址、IO基地址、中斷線選擇等配置寄存器的初始化數據。CPLD3通過DSP高位地址線的譯碼控制以太網芯片的片選并提供以太網接口部分的復位信號等。DSP和以太網的接口部分硬件如圖3所示。

3 數據采集處理系統的軟件設計
軟件編程時應該充分利用硬件資源及開發工具,使代碼達到所期望的性能,并且在DSP嵌入式系統的基礎上集成已經封裝的TCP/IP協議棧,增加網絡連接代碼。由于DSP系統硬件以及以太網協議的復雜性,本系統中的軟件編程是一個難點。
在本系統的軟件設計過程中,采用了TI公司的基于C6000系列DSP的實時操作系統DSP/BIOS以及DSP/BIOS提供的實時數據交換功能RTDX(Real-Time-Data-eXchange)。DSP/BIOS針對DSP的應用環境,通過一系列的對象模塊向開發者提供了一個實用優秀的實時操作系統。它可以壽命用戶提高軟件的模塊化程度、并行性和可維護性等,有利于降低系統成本和縮短開發周期,運行于該操作系統之上的應用程序在開發時間、軟件維護、升級等方面都有了極大的提高。實時數據交換功能是DSP/BIOS提供的一個全新的功能。在很多應用中要求DSP不停下來,而需要從主機中實時地讀取數據或者向主機實時地輸出數據。
因為本系統的軟件結構較為復雜,涉及的算法較多,故應采用模塊化、由頂向下、逐步細化的結構化程序設計方法。這一方法可節省軟件工作量、提高工作效率。圖4為簡化的數據采集處理程序流程圖。
實踐證明,根據以上方案設計基于DSP和以太網的數據采集處理系統,可以很好地實現對模擬信號的采集和處理。在此基礎上,也可以將其作為其于DSP和以太網的網絡測試平臺開發過程中的調試工具,從而加速把以太網集成到測試、采集和工業I/O儀器中的開發進程。(T002)
]]>從主機向DSP下載可執行文件的常用方式有:(1)利用仿真器,通過USB總線和JTAG端口,把可執行文件從主機下載進DSP。這種方式適用于軟件研制階段。(2)利用燒寫器,把可執行文件燒寫進硬件電路板上的Flash芯片中。DSP上電復位之后,將固化在Flash芯片中的代碼讀入DSP的片上RAM或片外RAM映射成的存儲區域里。這種方式適用于軟件調試結束、需要將其固化在電路板上的階段。固化之后,整個系統可以脫離主機運行。
在軟件無線電系統的實際應用過程中,還需要這樣一種下載方式:從主機直接向DSP下載可執行文件并且啟動程序運行。這些可執行文件是已經經過調試、滿足要求的功能模塊。主機將它們分別實時下載并啟動運行,能夠迅速地切換整個軟件無線電系統的業務模式,使系統迅速地滿足不同場合的要求,從而把系統面向廣大用戶的通用性與面向特定用戶的專用性很好地結合起來。
1 以DSP為核心的軟件無線電硬件平臺簡介
圖1是本文實例的硬件平臺框圖。A/D的工作方式由FPGA控制,外界模擬信號通過A/D采樣,進入雙口RAM,DSP從雙口RAM里讀取采樣數據。DSP芯片采用TI公司推出的TMS320C6000系列中的C6701,它通過EMIF與SDRAM和SBRAM芯片相連。PCI芯片AMCCS5933在主機和DSP之間起橋梁作用,它使得主機可以通過PCI總線訪問DSP的所有存儲空間,DSP也可以通過PCI總線向主機發送信息。
 |
2 從主機通過PCI總線向DSP下載可執行文件
2.1 實現流程
圖2顯示了下載可執行文件的整個流程。
 |
2.2 文件格式轉換
開發運行在TMS32C6000系列DSP上的程序時,通常都使用TI公司推出的集成開發環境CCS。編譯通過之后,會生成一個可執行文件*.out。下載到DSP中的就是該*.out文件里的代碼。
以文件loadProgTest.out為例,闡述文件格式的轉換過程:
首先把loadProgTest.out文件轉換成十六進制格式的文件,編寫一個名為loadProgTest.cmd的文件,內容如下:
各條語句的含義如下:
 |
第1行是out文件名;第2行表示輸出ASCII的十六進制格式;第3行指明轉換后的十六進制文件為image模式;第4行表示生成名為loadProgTest.mxp的文件,可以從該文件中看到各段所占的存儲單元;第5行和第6行分別指明memory和ROM的寬度;第7行指明little-endian方式(如果需要使用big-endian方式,把L改為M即可)。
可執行文件中的代碼從組織形式上分成若干段,從內容上則分為程序代碼和數據代碼。第10行表示在DSP的存儲區域中,為程序代碼開辟的空間是從地址0x00000000到0x0000ffff;程序代碼轉換成十六進制格式之后,將被寫入loadProgTest.hex文件。第11行表示在DSP的存儲區域中,為數據代碼開辟的空間是從地址0x80000000到0x8000ffff;數據代碼轉換成十六進制格式之后,將被寫入loadProgTest.a10文件。
編寫好loadProgTest.cmd文件之后,從CCS安裝目錄下拷貝出一個名為hex6x.exe的應用程序,把它和loadProgTest.out文件以及loadProgTest.cmd文件放在同一個文件夾里。執行命令行hex6x loadProgTest.cmd。
執行完后,將生成3個文件:loadProgTest.mxp、loadProgTest.hex和loadProgTest.a10。
其次,把loadProgTest.hex和loadProgTest.a10 2個文件分別轉換為頭文件
編寫一個C語言應用程序,利用C語言中的文件庫函數,新建一個名叫code.h的頭文件,然后打開loadProgTest.hex,按從前到后的順序逐一讀取其中的字符。每讀取8個字符,就在這8個字符中最先讀取的字符前面加上“0x”,然后把它們寫入頭文件code.h。這樣,就把loadProgTest.hex中的程序代碼組織成了一個數組,存放進code.h頭文件。用同樣的方法,把loadProgTest.a10中的數據代碼組織成一個數組,存放進data.h頭文件里。
經過了上述轉換之后,就可以把頭文件code.h和data.h中的數組,即可執行文件loadProgTest.out中的代碼下載進DSP中了。
2.3 下載代碼
下載代碼之前要做的準備工作是把DSP的BOOT方式設置為HPI方式(HPI指DSP的主機并行端口),并給DSP一個復位脈沖,以鎖存HPI的BOOT方式。這時,DSP的內核將處于reset狀態。
設置并鎖存DSP的BOOT方式之后,就可以向它下載代碼了。下載代碼的過程全部在PCI驅動程序里完成,主機可以通過HPI訪問DSP的所有存儲空間。本實例中,下載程序代碼時,首先配置HPI控制寄存器HPIC為0x00010001,其次配置HPI地址寄存器HPIA為0x00000000,這是程序代碼在DSP存儲空間中的起始存儲地址,然后把code.h里的數組寫進自動增量模式的HPI數據寄存器HPID。下載數據代碼的步驟和下載程序代碼一樣,只是要把HPIA配置成0x80000000,這是數據代碼在DSP存儲空間中的起始存儲地址。
2.4 啟動程序運行
成功下載可執行文件的代碼之后,主機向HPIC寄存器中的DSPINT位寫入1。這個動作同樣是在PCI驅動程序里完成。只要DSPINT=1,DSP的內核將被喚醒,自動從0x00000000處開始執行已下載的程序。
圖2是一個演示實例,程序功能是向地址0x80007000至0x80007010的DSP存儲區寫入0x12345678。可以看到下載程序前后DSP存儲區的內容變化。
 |
3 結 論
通過轉換可執行文件的格式,把DSP設置成HPI的BOOT方式,復位DSP,下載可執行文件代碼,設置HPIC寄存器的DSPINT位為1,可以實現從主機通過PCI總線在線下載可執行文件、并且啟動程序運行的目的。本文中的實例DSP采用了TMS320C6701,對于其它型號的DSP,本文同樣具有指導意義。
]]>MPC860 是PowerPC系列產品。PowerPC系列是由IBM、Motorola和Apple聯合研制的基于RISC結構的微處理器。PowerPC可運行于多種操作環境,使用的工作平臺從便攜式設備到服務器。TMS320C6000系列是1997年美國TI公司推出的DSP芯片,這種芯片是定點、浮點兼容的 DSPs系列。其中定點系列是TMS320C62xx,浮點系列是TMS320C67xx,它們可以通過DSP的HPI(Host Port Interface)和MPC860相連。本文針對C6202介紹另外一種接口方法,即同步主機接口模式下C6202的擴展總線與MPC860的接口實現,其中C6202為從處理器,MPC860為主處理器。
1 TMS320C6000的主要特點
TMS320C6000 系列DSP(數字信號處理器)是TI公司最新推出的一種并行處理的數字信號處理器。TMS320C6000片內有8個并行的處理單元,分為相同的兩組。它的體系結構采用超長指令字(VLIW)結構,單指令字長為32bit,8個指令組成一個指令包,總字長為8×32=256bit。芯片內部設置了專門的指令分配模塊,可以將256bit的指令包同時分配到8個處理單元,并由8個單元同時運行。芯片的最高時鐘頻率可以達到300MHz,通過片內的鎖相環(PLL)將輸入時鐘倍頻獲得。當片內的8個處理單元同時運行時,最大處理能力可以達到2400MIPS。
TMS320C6000主要是為移動通信基站的信號處理而推出的超級處理芯片。200MHz時鐘的C6201完成1024點定點FFT的時間只要66μs,比傳統的DSP要快一個數量級,在民用和軍用領域都將有廣闊的應用前景。
2 TMS3206000的擴展總線
目前,TMS320C6000系列中中有C6202和C6203具有擴展總線。它們是在C6201/6701主機接口(HPI)的基礎上發展起來的。
擴展總線是一個32bit寬的總線,支持與異步外設、異步/同步FIFO、PCI橋及外部主控處理器的接口。它同時還提供了一個靈活的總線仲裁機制,可以進行內部仲載,也可以由外部邏輯完成。
擴展總線從結構上可以分為兩部分:I/O接口和主機接口,如圖1所示。
I/O 接口,擴展總線共管轄4個XCE外部空間,4個空間可以分別配置成兩種工作模式:異步I/O模式和同步FIFO模式。這兩種模式可以在一個系統中同時工作。異步I/O模式的接口信號時序與EMIF類似,具有可編程程度高的特點。這一模式下,擴展總線接口的4根地址信號使得每個XCE空間最多可以掛接16 個外部設備。FIFO模式則提供了與同步FIFO無縫接口的能力,可以直接控制1個進行讀操作的同步FIFO或4個進行寫操作的同步FIFO。借助少量外部邏輯,每個XCE空間可以管理16個讀操作FIFO或16個寫操作FIFO。擴展總線I/O口與DSP的其他存儲空間由DMA控制器進行連接。
主機接口也有兩種工和模式:同步和異步。同步模式提供了主控和從屬兩種工作方式,此時地地址信號和數據信號復用相同的管腳。異步模式只有從屬功能,它與 C6201/C6211/C6701/C6711的HPI操作完全類似,只是數據寬度為32bit。異步模式可以用來與全類似,只是數據寬度為 32bit。異步模式可以用來與其他微處理器接口。擴展總線主機接口與DSP存儲器的連接由DMA輔助通道完成。
在同步主機接口模式下,主機的數據與地址信號復用,并且與i960Jx兼容。目前主流的PCI接口芯片都采用i960總線作為芯片內部總線,這樣C6000 與PCI總線接口時,需要的外部邏輯可以減少到最少。尤其在作為從屬處理器時,同步主機接口同樣可以非常方便地與其他一些通用處理器接口。C6202的擴展總線還具有突發傳輸的能力。本文即利用這一方式實現MPC860與C6202擴展總線的接口。
C6202處理器的工作頻率最高可以采用50MHz,經內部4倍頻后升至200MHz,每個時鐘周期最多可以并行執行8條指令,從而可以實現1600MIPS的定點運算能力,完成1024點定點FFT的時間只需70μs。
3 MPC860介紹
MPC860 PowerQUICC是當今比較流行、性能相當優越的單片集成嵌入式微處理器,繼承了以前享有盛譽的32bit 68360Quicc和68302的許多優點。它內部集成了微處理器和一些控制領域常用的外圍組件,特別適用于互聯網絡和數據通信市場。 PowerQUICC可以被稱為MC68360在網絡和數據通信領域的新一代產品,提高了器件運行的各方面性能,包括器件的適應性、擴展能力和集成度等。 MPC860 PowerQUICC通信處理器可根據用戶要求提供2~4個串行通信控制器、不同規格的指令和數據緩存及各種級別的網絡協議支持。該產品專為寬帶接入設備如:遠程接入路由器、DSLAM、接入集線器、LAN/WAN交換機、PBX系統和網關等設計。
在MPC860中包括3個主要模塊:PowerPC核心、系統接口單元(SIU)、通信處理模塊(CPM)。PowerPC是主要的處理機單元,通常稱為Embedded PowerPC核心(或EPPC),它包括緩存和存儲器管理單元(MMU),在40MHz時鐘時為50 MIPS指令速度;第二個主要模塊為系統接口單元,它的主功能是提供內部總線和外部總線的接口;第三個主要模塊為通信處理機模塊,CPM在不同的通信設備如SCC和SMC上發送接收數據通信,通信設備可以獨立工作。SCC和SMC也可以用于時分復用總線。
CPM模塊中有一個32位RISC微處理機。MPC860有2個CPU:PowerPC和32位RISC。PowerPC執行高層代碼,RISC處理實際通信的低層通信功能。2個處理機主要是通過內部存儲空間配合工作。在存儲器區,每個處理機都可以設置控制位、讀狀態位。
MPC860 中有16個串行DMA單元。每一個通信設備都有一個發送DMA和接收DMA。32位RISC控制這16個串行DMA在通信設備和存儲器之間傳送數據。當 MPC860接收數據時,串行DMA從通信設備接收數據并放入存儲器中;發送數據順序相反,串行DMA從存儲器中取數據,把數據送到通信設備。串行DMA 只服務CPM的RISC,但是2個虛擬的IDMA可以為用戶所用。4 擴展總線接口實現
MPC860內部集成了嵌入式的PowerPC核和使用特定RISC處理器的通信處理模塊(CPM)。這個雙處理器結構優于傳統結構,因為CPM可以從嵌入式的PowerPC核卸出外圍任務。
4.1 接口實現
同步主機接口模式下,C6202和MPC860的接口如圖2所示。盡管圖2中的C6202處于從方式,但還是具有擴展總線仲裁的能力,用于異步I/O和擴展總線的FIFO接口。只有當這兩個設備共享總線時,MPC860內部的仲裁才被使用。
擴展總線的管腳定義
擴展總線管理 MPC860的管腳 功能定義
XCNTL A[29] MPC860用于控制信號的地址位,A31是MPC860地址總線的LSB
XBLAST BDIP 觸發傳輸指示,XBLAST的極性(在這個例子高有效)由復位時XD[13]的上位電阻決定
XW/R RD/WR 讀寫存取指示,XW/R的極性(在這個例子高有效)由復位時候的XD[12]的上拉電阻決定
XD[31:0] D[0:31] MPC860用D[0:3]作為32位的接口。D0是MPC860數據總線的MSB,而XD31是擴展總線的MSB。
XCLK XLKOUT 自身(擴展)總線時鐘
XHOLD 間接邏輯需與 擴展總線仲裁信號
XHOLDA BR、BG和BB連接 注意內部擴展總線仲裁已經處于使能端
XAS TS 新的轉移開始指示
XCS A[28:0] MPC860的地址解碼從而產生XCS信號
XBE[3:0] TSIZE[1:0]、A[31:30] 字節使能用TSIZE和A[31:30]的解碼來實現
XRDY TA SETA bit在MPC860選擇寄存器中設置為1,用于指示TA由外部總線產生
MPC860的內部總線仲裁處于禁止狀態,相反擴展總線的仲裁處于使能狀態。DSP的字節使能信號由TSIZE[1:0]和MPC860的地址線A[31:30]通過解碼得到,DSP字節使能換算表如表1所示。表1 DSP字節使能換算表
| TSIZE | A30 | A31 | XBE[3:0] | 0 10 10 10 11 01 00 0 | 0011010 | 0101000 | 0 1 1 11 0 1 11 1 0 11 1 1 00 0 1 11 1 0 00 0 0 0 4.2 自舉配置 MPC860 及擴展總線把數據總線的上拉和下拉電阻用于硬件復位的BOOT配置,MPC860和DSP需要不同的上拉電阻配置。方法之一就是用總線開關(bus switch)。在這個例子中用SN74CBT16390(2個16bit和32bit之間FET復用/解復用總線開關)在復位的時候人離MPC860和 DSP的數據總線,允許每一個設備有自己不同的復位配置字。方法之二就是首先硬件復位(復位的過程中,XBUS的上拉和下拉電阻用于配置MPC860),而DSP復位應該在MPC860之后。在DSP復位之后,MPC860有效地驅動數據總線上用于配置DSP的數據值,從而DSP將被配置。 由于兩個設備都可以運行在內部總線仲裁使能或者禁止方式,所以內部擴展總線仲裁(TMS320C6000擴展總線)處理總線的仲裁。不管內部還是外部的仲裁配置都在系統復位時設置。假設處于外部仲裁,那么在MPC860從數據總線上取樣硬件復位配置字的時候,MPC860的ERAB位必須設置為1;而當 DSP從復位到內部總線仲裁的數據總線上取樣硬件復位配置字的時候,TMS320C6000的XARB位必須設置為1。 通過在XD[31:0]上拉和下拉電阻的擴展總線自舉配置如下: 字段(field) 定義 BLPOL 當DSPs作為擴展總線的從屬時,XBLAST信號的極性BLPOL=1,XBLAST最高有效 RWPOL 擴展總線讀/寫信號的極性,RWPOL=1,為XW/R HMOD 主機(host)的模式(對應于HPIC中的XB狀態),HMOD=1,外部的主機接口處于同步的主/從模式 XARB 擴展總線仲裁使能(對應于XBGC中的狀態),XARB=1,內部擴展總線仲裁處于使能狀態 FMOD FIFO模式(對應于XBGC中的狀態) LEND 小端模式,LEND=1,系統運行在小端模式 BootMode[4:0] 設定設備自舉模式,包括芽機口自舉、ROM、boot、存儲器映射選擇 為使工作準確,MPC860的高速緩存必須關閉使能。數據緩存是否使用,只要將相應的狀態寫放DC_CST寄存器。在禁止狀態,緩豐了標志狀態位被忽略,訪問將通過總線傳輸。數據緩存在復位后默認為禁止。禁止的數據緩存不影響數據地址的邏輯轉換,在MSROR位的控制下繼續進行,任何寫入DC_CST寄存器的操作必須優先于一個同步指令,則確保在數據存儲時,數據緩存的使能變化。由于總線錯誤或者執行特定的直接緩存線性控制時,數據緩存產生一個中斷信號,緩存進入禁止狀態,類似于禁止。每一頁都有不同的存儲控制屬性,MPC860支持緩存禁止(CI)、寫入(WT)和監視(G)屬性,但不支持存儲器的一致性。對于要求存儲一致性的頁,必須編程設置為緩存禁止。G屬性用于映射那些對不確定存儲比較敏感的I/O設備,有G屬性的頁使存儲強行停止,除非是非敏感性存儲或者被核(core)取消。是否可緩存的區域必須定義,對于主要存儲區的寫回(write-back)或寫通(write-through)模式,必須在使數據緩存使能之前通過初始化MMU來選擇。 經實驗驗證,MPC860可以對擴展總線進行寫操作,也可以讀操作,基本功能已經實現。此方案具有一定的實用性。
|
1 C6201/C6701新一代DSP處理器




DSP/BIOS 是一個用戶可剪裁的實時操作系統,主要由3部分組成:多線程實時內核;實時分析工具;芯片支持庫。利用實時操作系統開發程序,可以方便快速地開發復雜的DSP程序。操作系統維護調度多線程的運行,只需將定制的數字信號處理算法作為一個線程嵌入系統即可;芯片支持庫幫助管理外設資源,復雜的外設寄存器初始化可以利用直接圖形工具配置;實時分析工具可以幫助分析算法實時運行情況。
DSP/BIOS實時操作系統的圖形配置界面包括:
(1)全局設置(system)— 包括內存配置、芯片支持庫設置、endian模式設置等;
(2)操作系統調度工具(scheduling)— 包括定時器、周期器、硬件中斷管理、軟件中斷管理、任務調度、系統空載任務函數等;
(3)同步機制(synchronization)一一提供一般操作系統都具有的信號燈、郵箱、隊列、鎖4個工具;
(4)芯片支持庫(chip support library)— 針對不同的DSP芯片幫助配置DSP的外設資源,最常用的有DMA,MCBSPEMIF,TIMER等的配置;
(5)主機交互接口(input/output)— 提供DSP實時運行時與主機通過仿真口和CCS(集成開發系統)交互數據的機制;
(6)調試工具(instrumentation)— 記錄器(LOG)可以提供調試信息,但是特別針對實時操作優化;統計工具(STS)可以統計調試過程中的各種事件。
通過使用 DSP/BIOS,我們可以:
(1)使用多線程技術高效地管理DSP的運行,以提高運行效率;
(2)使用標準接口的I/O和中斷;
(3)高效地定義和配置系統資源,如系統內存和中斷向量表;
(4)通過實時分析工具對用戶應用程序的運行狀況實時查看;
(5)向用戶的目標應用程序添加數據結構并圍繞一組相關線程來加以組織:
(6)幾乎所有的初始化都可以通過圖形化配置來完成,而不必詳細了解各個寄存器的每一位所代表的意義;
(7)通過調用DSP/BIOS或CSL(芯片支持庫)的API庫函數,使代碼效率更高、程序可讀性和可移植性更強,從而使得向新的TMS320DSP移植更加容易。例如:開全局中斷可以用HWI_enable(),啟動DMA可以用DMA_start(hDMA0),這樣比直接通過寄存器配置來完成具有更強的可讀性和可移植性,而且不會出錯,也不必查閱相應的寄存器信息。
2 DSP/BIOS的資源優化
由于 DSP/BIOS的很多功能只有在調試時使用或者根本不用,如果不需要用到的部分都使用默認的配置將會占用較大的內存資源,如果用戶程序較大就會造成DSP內存資源緊張或不足。由于DSP/BIOS是一個可剪裁的操作系統,可以很方便地將不需要用到的功能關閉,以節省空間。表1列出了減少DSP/BIOS所占資源的幾種措施以及在C62x中可以減少的存儲空間大小。
表中減少的空間大小只作為參考,隨著CCS的版本不一樣可能會有一定差別。筆者在CCS2.20.18上編寫了一個簡單的程序,DSP采用的是TMS320C6203,主程序采用C語言編寫。優化前的.out文件大小為78.6KB,轉化成二進制文件為28.3KB;優化后的.out文件為29.4KB,轉化成二進制文件為4.4KB。
3 程序的自舉引導方法
TMS320C6000器件可以設置成3種自舉方式,其加載過程分別敘述如下:
①不加載 。CPU直接從存儲器的0地址處開始執行指令。如果系統中使用的是SDRAM,那么CPU 會先掛起,直到SDRAM的初始化完成。TMS320C6x1x 不具有這類方式。
②ROM 加載。位于外部存儲空間的ROM中的程序首先通過DMA/EDMA搬入地址。處。盡管加載過程是在芯片外部被復位信號釋放以后才開始的,但是當芯片仍處于內部復位保持時,就開始了上述的傳輸過程了。用戶可以指定外部ROM 的存儲寬度,EMIF會自動將相鄰的8bit或16bit數據合并成32bit。ROM中的程序必須以little endian的格式存儲。用DMA/EDMA進行的這一加載過程是一個單幀的數據.tk傳輸。傳輸過程完成
之后,CPU退出復位狀態,開始執行地址0處的指令。對于 TMS320C6x0x,DMA使用默認的ROM時序從CEl空間中拷貝64KB數據到地址0處。
對于 TMS320C6x1x,EDMA使用默認的ROM時序從CE1空間(C64x從EMIFB CE1空間)拷貝1KB數據到地址0處。

③主機 (HPI)引導。CPU停留在保持狀態,其余硬件部分均保持正常狀態。在這期間,外部主機通過主機口或PCI口(如6205或64x)初始化CPU的存儲空間。主機完成所有的初始化工作后,將主機口控制寄存器中的DSPINT位設置為1,結束引導過程。此時CPU退出復位狀態,開始執行地址0處的指令。在主機引導過程中,主機可以對DSP所有的存儲空間進行讀和寫。
其中,用得最多的是ROM加載。為了生成可以從ROM中自舉的代碼,就要注意DSP/BIOS中的存儲器設置。對于TMS320C6x0x,一般而言,64KB的代碼就足夠了,那樣就只需選擇好各個代碼段的Load Address和Run Address就可以了。DSP/BIOS將自動生成cmd文件,而不需用戶自己編寫。如果64KB不夠,則需自己編寫boot程序。而對于TMS320C6x1x ,1KB的程序一般是不夠用的,所以要自己編寫boot程序。下面以TMS320C6711為例介紹DSP/BIOS中程序空間的配置以及boot程序的編寫方法。
TMS320C6711內部含有64KB的RAM,既可以配置為L2Cache,也可以配置成SRAM。一般而言,在系統上電復位時配置為SRAM,將1KB的引導程序從ROM中拷貝到SRAM中,而在引導程序中將用戶的程序從ROM中拷貝到SBSRAM中或SDRAM中去執行。在主程序的初始化部分將內部RAM配置為高速緩存,這樣可以提高程序的運行速度。當然,也可以把內部RAM用作SRAM,把全部的用戶程序都引導到其中來執行,
這樣可以不用外接SBSRAM或SDRAM 。
首先在 DSP/BIOS的存儲器段管理器(Memory Section Manager)中指定如下幾段:
FLASH_BOOT:or igin=000000000,le ngth=0x400;(存儲自舉代碼)
FLASH_REST:or igin=0x90000400,le ngth=Ox1fc00;(存儲主程序代碼等)
IRAM :or igin= 000000000,length= 0x10000;(內部RAM)
SDRAM 或SBSRAM:origin=Ox80000000(CEO),length與外接存儲器大小有關,如果沒有則可省略。
上電復位時,FLASHesBOOT中的數據被復制到IRAM 中從地址0開始的一段,然后從地址0開始執行程序。因此,在這段代碼中要把其它相應的段從加載地址復制到運行地址。在DSP/BIOS程序中,所用到的段及其相應的加載地址和運行地址建議按表2、表3安排。


在 BOOT 程序中,首先要初始化EMIF的相關寄存器,特別是有外接存儲器時(如SDRAM或SBSRAM),一定要先初始化相關寄存器,主要是EMIF全局控制寄存器和CE空間控制寄存器。然后將加載地址位于ROM中而運行地址位于RAM中的段從ROM中復制到RAM中。具體的加載地址和運行地址可以在map文件中查到。最后,將程序指針跳轉到主程序入口(c_int00)開始執行。BOOT程序如下:
.sect " .myBootCode "
.global myBootCode
.ref _c_int00
;====myBootCode ===
myBootCode :
;***************
;Configure EMIF
;***************
...... ......
;***************
;CopySections
;***************
...... ......
;***************
;StartProgram
;***************
mvkl .S 2 _c_int00, B0
mvkh .S 2 _c_int00, B0
B . S2 B0
; jump to _c_int00
nop 5
編寫完 boot程序后,在cmd文件中加上一句:.my_boot_code: {} load=FLASH_BOOT,run=IRAM
]]>我的經歷
錯過第一次學習機會
我2000年進入大學,專業通信工程。入學的時候成績不錯,還拿過一等獎學金,自以為自己很聰明。當時我們學院有個科技協會,簡稱科協,那時的科協會長是個大四的學兄,給人印象深刻,感覺他很厲害,就入了科協,第一堂課是用555做個流水燈,科協已經把印制板做好,我只用把器件焊上去就行了,燈是亮了很好玩,于是自己琢磨電路的原理,那時是個剛入學的小子,什么也不懂,看那東西根本搞不懂,感覺太難了,后來慢慢就不去參加活動,再后來放棄了。
現在想想那個時候太輕言放棄了,包括后來大學里自學51單片機、學FPGA都是只淺嘗則止,而沒有持之以恒,以至于后來錯過了很多很多機會。所以在這里要告訴大家,也告訴我自己,學技術一定要堅持,不管碰到什么困難,絕不能輕言放棄,堅持就會有進步,就像長跑,總有幾個困難點,堅持過去就覺得不是那么困難,水平才會有提升。
第一次使用C51
說起這個,不得不感謝下我的一個大學室友,是他帶我入門C51,第一次用protel畫印制板,第一次申請免費樣片、第一次編寫調試程序,第一次使用示波器等等,這些都得歸功于他的指導。
時間過得很快,一轉眼就大四了,想想自己大學游戲玩了三年,學業荒廢,畢業設計這個機會一定要把握住,不然自己沒什么資本找工作啊,于是在選題的時候選了個單片機的題目“基于DDS的信號發生器設計”。雖然之前接觸過51、protel,不過那都是看看書而已,實際做起來什么都不會,我確定的方案是用C51去控制AD9853輸出相應頻率的波形,當然這里離不開鍵盤和LCD顯示,AD9853是從AD公司申請的樣片,那時我第一次知道還有免費午餐,大公司真的不錯,記得當時TIDSP都可以申請,我就申請了一片6202,不過后來沒那么容易申請了,這次我堅持了下來,一步一步地做,最終圓滿完成了畢業設計。
我是幸運的,因為身邊就有個很好的老師,初學者大都沒有這樣的條件,即便如此,初學者還是應充分挖掘身邊的資源,將它們都利用起來,這樣你才能更接近成功。
接觸DSP
2004畢業后我到一個研究所工作,我所在的部門是做視頻跟蹤器的,主要用DSP+FPGA,對我來說入魚得水,因為我對這些東西很有興趣。當時我的同事們用的還是TI C50DSP,這個很多人可能聽都沒聽過,TI的DSP按時間大概經歷了這幾個系列,C25-C50-V33-2000-5000-6000,C50的功能很有限,只有匯編開發環境,因為功能簡單,所以學起來也相對容易,加上我有51的基礎,很快就上手了,一年半后部門器件換代直接換成了64xx,由于受C50的影響,我們開發還是習慣用匯編,2006年5月前后,我率先用C開發產品,取得了不錯的效果。
這當中我接觸到了很多,由于我個人性格的原因,學什么都想學精,走了很多彎路。比如PCB剛開始用protel,后來發現它畫復雜板子的時候不方便,于是學用allegro,后來又學SI;DSP也是,6000會用了想學2000、5000,后來發現自己很幼稚,其實一到二門精通了足以,學什么要注意學習理念,工具平臺這些始終是外家功夫,要勤修內功。
總結及建議
1)選好自己的工具和平臺學DSP當然首先要選擇一款DSP(這里主要說TI的DSP,AD公司的不熟這里就不說了)。如果是個人學習的話主要看個人需要和應用場合,比如做圖像處理那當然首推TI6000了,初學者不必將DSP分出三六九等,各個系列沒有明顯的優劣,但有明確的應用領域,2000偏接口控制,5000偏語音,6000適合做大數據量信號處理,比如圖像、雷達等等。初學者最好有個開發板,不然無異于紙上談兵,2000、5000的開發板相對便宜,6000的就比較昂貴。
就上手容易度來說,我個人覺得6000更易上手,6000的結構較2000、5000明了清晰,硬件上的條條框框比較少,你不需要看很多的硬件結構資料就能著手編程,這個大概是技術的進步吧。不過還是這句話,應用場合決定你的選擇。
2)自己先動手
初學者如果會C語言語法,在看過一些資料后就可以著手寫自己的第一個程序,如果寫不出來,看看TI最初級的例程,完成自己第一個程序。我給我們單位新同事做6000培訓的時候,給他們的第一個題目就是寫一個程序讓LED燈不停閃爍,這個燈可能接在GPIO上或者通過EMIF譯碼與FPGA配合控制(后者可能更有意義),更進一步的程序是控制閃爍的頻率。我比較喜歡讓他們用GPIO和EMIF,它們可能是6000里最簡單和用的最多的外設了,它們是初學者最早要攻克的堡壘。
初學者往往對硬件結構和軟件的配合沒有概念,對片內存儲空間、片外存儲空間、片上外設這些概念沒有實在的理解,這些概念需要自己的反復的思考、反復的實驗、反復的體會才能最終搞清楚,這些弄明白了你也就入門了。
初學者比較忌諱看太多和太復雜的例程,看得太多你的思緒會比較亂,看得太復雜你會心浮氣躁,復雜的例程一般它都有相對復雜的編程結構,這個初學者是很難體會到的,所以剛開始不要看,等你寫了20到30個程序的時候再試著看相對復雜的例程。
3)多動手
這個不用多說了,光看不練假把式。
4)片上外設
這里拿DM642來說,我把常用的外設由簡單到復雜排個序:GPIO-TIMER-EDMA-EMIF-I2C-MCASP-VideoPort-EMAC、MDIO,MCASP我沒用過,不過看過資料感覺不復雜,我給初學者的建議是先把前面4個學清楚,可以先學GPIO這個真的是簡單,剛開始不要急著用CSL,用匯編或是C寫個程序讓某個GPIO腳上輸出波形,這樣有助于理解片上外設以及有關的概念。前面4個明白了后面的具體用到再學,這個時候你可以看TI相應的例程,拿來用就可以。
5)匯編、C和線性匯編
現在開發6000的標準流程是先用C寫,C的好處很多這里不說了,有太多的文章在論述,不過對于準備做優化的同志們來說,匯編不會也不行,用匯編相對于C更助于你理解6000的架構,很多初學者對C語言中用指針對某個空間操作不理解,用匯編寫的話相對要好理解的多。
大家不必對匯編心存畏懼,其實它也很簡單,只不過它比較晦澀,用它開發整個系統的時間上的花費太多,不過關鍵算法的優化有時還是離不開它,TI目前還提供線性匯編,它是匯編和C的折中,兼備匯編的效率和C的易開發性。
匯編和C都只是工具,關鍵還是你對架構的理解和編程理念,所以選擇哪個都有道理,通過工具去探索架構而已。我個人覺得初學者主要應學習C,畢竟它是主流,可以用匯編寫4-5個小程序,熟悉它的語法就行,日后用它做優化也不會什么都不知道,而且也助于對硬件架構的理解。
結束
就寫這么多了,一家之言,里面有很多廢話,希望對初學者有點幫助,拋磚引玉,也希望高手們多多寫出自已的經驗。
優化一起放過來了~~~
關于優化我的經驗是這樣的:
一、首先考慮從系統結構上優化,比如盡量減少待處理數據的無謂搬移,考慮你DSP片內存儲量和每次處理數據量對系統結構優化,這部分的優化應該最早做;
二、其次從算法層面上著手,看采用的算法有沒有更好更簡單的計算方法,算法是否有某種對稱性,可否采用更合適的數據結構等等,這方面的優化比程序上的優化更明顯;
三、如果算法層面暫時無更好的優化辦法,看看軟件結構能否優化。
比如:
1)多層的循環結構能否減層。我經常看到這樣的程序:
for(i = 0; i++; i< A)
for(j = 0; j++ j< B)
{
E[j] = C[j] - D[j];
}
這個可以優化成:
for(i = 0; i++; i<A*B)
{
E = C - D;
}
2) 關鍵循環結構中的條件、跳轉指令應盡量避免,哪怕會增加一些循環次數,循環中沒有條件指令優化器更容易優化;
3)關鍵循環不要調用子函數
其它還有一些,具體可以看看手冊,手冊上講的很清楚
四、結合DSP系統的硬件結構優化
1)看你處理的數據是放在片內還是片外,如果放在片外的話這個建議將數據分塊分批倒入片內處理,類似于流水結構;
2)針對外部數據可對L2 cache優化
五、結合DSP優化器、指令系統等進行優化
這部分可以詳細的看TI的手冊,大概有這幾個方法:
1)優化選項,-o3 -pm 取消-g 等等這些選項,如果你的軟件結構很好,那么它們的優化效果很明顯;
2)加一些優化指示符指導優化,這部分看手冊,包括存儲地址無關性,SIMD(單指令多數據處理)等等;
3)用一些專用指令,比如6000提供飽和加、溢出減指令,可以不必用條件判斷;
4)如果效果還是不好,用線性匯編改寫你的程序,將你的優化思想用線性匯編表述出來,一般到地步就可以了;
5)如果線性匯編優化未能盡顯你的優化思想,那就匯編吧,優化器不會再幫助你優化,完全是你自己控制程序了,自己做軟件流水吧;
這部分需要有比較豐富的優化經驗和扎實的優化功底,多多積累,多看資料。
最后要重點說下:
優化是沒有止境的,在對程序對細致優化前要對程序每個部分測試下時間,對非常耗時的部分做優化,一但滿足你的要求就可以,不要為了優化而優化,我們應該有更重要的東西要學,不要陷在優化上而不能自拔!!
本文來自CSDN博客,轉載請標明出處:http://blog.csdn.net/ww303875615/archive/2009/12/10/4977742.aspx
]]>引言
近年來,以高速數字信號處理器(DSP)為基礎的實時數字信號處理技術飛速發展,并獲得了廣泛的應用。TMS320C6000系列DSP是德州儀器公司(TI)推出的定點、浮點系列DSP,其中定點產品峰值處理能力達到4800MIPS,浮點產品峰值處理能力達到1350MFLOPS,是目前國際上性能最高的DSP之一,其卓越的性能使得它在傳統的DSP領域、雷達、無線電基站等高端領域,以及寬帶媒體、身份識別等新興領域都有很好的應用前景。隨著DSP性能和功能的不斷增強,應用系統的設計越來越復雜,要將DSP的性能充分釋放出來,合理的板級設計是DSP系統開發人員面臨的一個關鍵性的問題。
BGA封裝的設計分析
C6000系列DSP采用的是一種高密度BGA(Ball Grid Array)封裝,采用這種封裝的好處包括可以獲得更好的高頻電氣性能、比引腳封裝具有更長的使用周期、尺寸更小以及制造成本更低等。BGA封裝給芯片制造商以及芯片本身的性能都帶來了好處,但是對于板級開發人員來說,卻造成了很多不便之處,布線、焊裝、檢測與調試都比以前更加困難。
在設計密腳距(Fine-Pitch)的BGA封裝時,不同技術的應用會帶來不同的生產質量,PCB上焊盤的合理設計能提高生產的可靠性。有兩種焊盤的設計方法可以選擇:阻焊定義(SMD,solder mask defined)的焊盤和無阻焊定義的焊盤(NSMD,non-solder mask defined)。圖1是這兩種焊盤的不同的焊裝效果。
圖1 SMD焊盤(a)和NSML焊盤(b)不同的焊裝效果(略)
這兩種焊盤定義都有其優缺點。使用SMD焊盤時,焊盤需要的尺寸比期望的尺寸大,而且如圖1所示,焊料與焊盤的接觸面尺寸由阻焊層的空隙大小決定,過大的焊盤使得走線非常困難。這種焊盤定義的優點是它能夠精密的控制尺寸,焊盤也能夠更好的附著在PCB板的基底層上。與它相比,NSMD焊盤蝕刻在阻焊層內(如圖1),焊盤的尺寸決定于銅層的蝕刻,沒有SMD焊盤尺寸精密,但是NSMD是TI公司推薦使用的焊盤定義,它可以在板上留下較多的布線空間以適應密腳距的BGA封裝,可以使器件與PCB板的結合更加的緊密。圖2是TI公司提供的焊盤的最佳配置。另外,BGA封裝的器件需要采用回流焊設備進行焊裝,為了保證器件封裝與PCB板有良好的連接,板子上的焊盤一般應比器件上的管腳焊點(低溫金屬球)的直徑略大。
在密腳距的BGA封裝設計時,布線也是需要注意的問題。電路板設計時,通常采用0.1mm的最小線寬,0.2mm的間距。以腳間距為0.8mm的TMS320C6415(GLZ-532)為例,由于焊盤間的距離大概只有0.38mm(該距離是假定焊盤直徑為0.41mm時的最壞情況),在兩腳間最多只能布一條線。另外,焊盤通常通過較寬的銅導線與其他設備或者金屬化孔(PTH,Plated Through Hole)相連。作為一個規則,焊盤必須和PTH分離,將PTH放在焊盤的間隙處,并通過導線與焊盤連接是通用的辦法。
印制電路板的設計與分析
C6000系列DSP的板級設計不可避免地涉及到了多層印制電路板的設計問題,多層板有很多優點,但是因其密度和層數的關系,在加工制作過程中難度大,測試困難,可靠性保障程度相對于雙面板而言較低,一旦出現故障,幾乎沒有維修的可能。多層板的質量和可靠性以及是否能取得合理的價格,很大程度上與多層板的設計有關,作為設計者必須熟悉印制板有關的設計標準和要求。
通過使用高密度布線技術,可以解決在設計中遇到的可供信號線通過的空間過小的難題。在高密度板設計中,孔密度(Via Density)是一個需要注意的因素。孔密度即特定面積的PCB板上的過孔個數。使用較小的過孔,可以增加PCB板的布通率,進而使用更少的板面積,并能增加孔密度,微孔的使用解決了很多與孔密度相關的問題。下面想要分析的是兩種高密度的六層板的設計方法。
圖2 NSMD焊盤最佳配置(略)
通常在C600系列DSP的板級設計時,BGA封裝外圍的孔密度相對較大,這是因為管腳焊點間布線路徑的有限選擇導致的。為了減少封裝外圍孔密度的問題,設計者可以如圖3所示的垂直設計方法,在焊盤之間垂直的轉一個0.25mm的孔,穿過內層,設計者可以選擇適當的層和布線的路徑,并使用一種被稱為狗骨形(dog bone)的導線來連接通孔和焊盤。這種方法最多需要為每一個管腳焊點轉一個通孔。除了這種方法以外,還有一種方法需要使用先進的微孔技術,通過使用盲孔和埋孔來連接各層。如圖4所示,盲孔將頂層和底層與中間層連接,埋孔連接中間層。這種方法需要使用激光在焊盤上轉0.1mm的微孔并在第二層埋上狗骨形的連接導線。因為埋孔沒有暴露出來,可以使用較大的孔徑如0.25mm。如果需要可以在底層放上旁路電容和其他的分立元件。
SMT生產工藝流程中需要注意的問題 元器件貼片
元器件的貼片是SMT生產工藝流程中焊膏印刷后的第二道工序。BGA封裝具有"自對準"的特性,在元器件貼片這道工序中由于熔化的焊料的表面張力可以使BGA封裝元件自動的對準,在一定的偏差范圍內使焊點和焊盤更好的結合。作為慣例,放置BGA封裝元件時焊盤尺寸50%以內的偏差都是允許的。
圖3 通用的PCB板設計框圖(略)
圖4 微孔化的PCB板設計方法(略)
元器件的貼片通常都是使用能夠根據BGA金屬球版本來放置BGA封裝器件的設備完成的。如果金屬球的版本號對設備而言無效的話,可以根據元器件的邊緣來對齊器件,在這種情況下,由于器件的差異性,放置元器件時可能會有很大的偏差,推薦使用金屬球的對準的方式。放置元器件時注意不要將焊膏濺出,一般200到300克力就可以使得元器件很好地與焊膏接觸了。
回流焊接
回流焊接是BGA裝配過程中最難控制的工序,在回流過程中需要注意檢查PCB板上所有器件回流時的形態并確保它們在焊接過程中有充分的回流。當使用的回流爐不能使PCB板均勻受熱的情況下,需要在板上不同的位置安裝多重的熱電偶。如果需要的話,還應該重新調節溫度使元器件有更好的焊接。回流一般經過預熱、浸潤、回流、冷卻幾個階段。預熱時緩慢加熱,較理想的升溫速度為每秒1.5℃到2℃,升溫至120℃到140℃;浸潤階段里,額外的揮發性物質被蒸發掉,助焊劑也開始揮發。這個階段的設置很大程度上依賴與焊膏的選擇,一般保持120℃到170℃,持續時間約120到180秒較好,以確保雜質盡可能的揮發。回流階段應該使溫度很快的上升到使焊料熔化成液體的溫度,一般最高的溫度為220℃到235℃,超過180℃的持續時間為60到75秒,一旦焊接完畢,進入到冷卻的階段,一般降溫的速度控制在2到3℃/秒。
小結
本文對TI C6000 DSP板級設計時需要注意的問題進行了分析,除了以上提到的這些問題,要想很快設計出PCB板,并使BGA封裝可靠的連接,還需要更好的和制板商以及貼片廠家溝通,以了解他們能夠達到的制造工藝水平,并告知在制作過程中需要他們特別注意問題。
關鍵詞:C6000;程序優化;軟件流水;線性匯編
0 引 言
目前在DSP平臺上編程多使用匯編語言與C語言,為了追求代碼的高效,過去一般用匯編語言來編制。DSP程序匯編語言簡潔高效,能夠直接操作DSP的內部寄存器、存儲空間、外設,但可讀性、可修改性、可移植性較差;隨著DSP應用范圍不斷延伸,應用的日趨復雜,匯編語言程序在可讀性、可修改性、可移植性和可重用性的缺點日益突出,軟件需求與軟件生產力之間的矛盾日益嚴重。引入高級語言(如C語言,C++,Java),可以解決該矛盾。在高級語言中,C語言是一種較為高效的高級語言,在可讀性、可移植性等方面優于匯編指令。各個DSP芯片公司都相繼推出了相應的C語言編譯器。
但由于DSF結構的特殊性,使得該平臺上的C語言編譯器無法充分發揮DSP器件的性能優勢。同樣功能的C語言程序,效率往往只有直接書寫的匯編程序的幾分之一甚至幾十分之一,因此有必要根據DSP的特性對C語言編寫的程序進行進一步的優化。
l TMS320C6000處理器介紹
TMS320C6000是TMS320系列產品中的新一代高性能DSP芯片,共分為兩大系列。其中定點系列為TMS320C62xx和TMS320C64xx;浮點系列為TMS320C67xx。由于TMS320C6000的開發主要面向數據密集型算法,它有著豐富的內部資源和強大的運算能力,所以被廣泛地應用于數字通信和圖像處理等領域。
C6000系列CPU中的8個功能單元可以并行操作,并且其中兩個功能單元為硬件乘法運算單元,大大地提高了乘法速度。DSP采用具有獨立程序總線和數據總線的哈佛總線結構,僅片內程序總線寬度就可達到256位,即每周期可并行執行8條32位指令;片內兩套數據總線的寬度分別為32位;此外,DSP還有一套32位DMA專用總線用于傳輸。靈活的總線結構使得數據瓶頸對系統性能的限制大大緩解。C6000的通用寄存器組能支持32位和40位定點數據操作,另外C67xx和C64xx還分別支持64位雙精度數據和64位雙字定點數據操作。除了多功能單元外,流水技術是提高DSP程序執行效率的另一主要手段。由于TMS320C6000的特殊結構,功能單元同時執行的各種操作可由VLlW長指令分配模塊來同步執行,使8條并行指令同時通過流水線的每個節拍,極大地提高了機器的吞吐量。
2 C6000軟件開發流程
圖1為C6000的軟件開發流程圖。圖中陰影部分是開發C代碼的常規流程,其他部分用于輔助和加速開發討程.

C/C++源文件首先經過C/C++編譯器(C/C++cornpiler)轉換為C6000匯編源代碼。編譯器、優化器(optimizer)和交疊工具是C/C++編譯器的組成部分。編譯器使用戶能一步完成編譯、匯編和連接;優化器調整合修改代碼以提高C程序的效率;交疊工具把C/C++語句和對應的匯編語句交疊列出。
匯編源代碼再經過匯編器(Assembier)翻譯為機器語言目標文件。機器語言是基于通用目標文件格式(Common Object File Format,COFF)的。
連接器(Linker)連接目標文件,生成一個可執行文件。它要完成地址的重分配(Relocation)和解析外部引用(Resolve External References)。
得到可執行文件之后就可以進行調試。可用軟件仿真器(Simulator)在PC機上對指令和運行時間進行精確仿真;用XDS硬件仿真器(Emulator)在目標板上進行調試。
調試通過后即可下載到目標板進行獨立運行。
3 程序優化流程及方法
3.1 程序優化階段
由于DSP應用的復雜度,在用C語言進行DSP軟件開發時,一般先在基于通用微處理器的PC機或工作站上對算法進行仿真,仿真通過后再將C程序移植到DSP平臺中。
所以,DSP的軟件開發與優化流程主要分為3個階段:C代碼開發階段;C代碼優化階段;手工匯編代碼重編寫階段。如圖2所示。

在圖2中,第一階段:沒有C6000知識的用戶能開發自己的C代碼,然后使用CCS中的代碼剖析工具,確定C代碼中可能存在的低效率段,為進一步代碼優化做好準備。第二階段:C代碼優化階段。在這個階段,主要利用intrinsics函數以及編譯器編譯選項來提高代碼的性能。優化后利用軟件模擬器檢查代碼的效率,如仍不能達到期望的效率,則進入第三階段。第三階段:寫線性匯編優化。在這個階段中,用戶把最耗費時間的代碼抽取出來,重新用線性匯編寫,然后使用匯編優化器優化這些代碼。在第一次寫線性匯編時,可以不考慮流水線和寄存器分配。然后,提高線性匯編代碼性能,往代碼中添加更多的細節,如分配寄存器等。由于這一階段所需的時間要比第二階段多,所以整個代碼的優化盡量放在第二階段來完成,而少使用線性匯編代碼優化。
3.2 C/C++代碼優化方法
為了使C/C++代碼獲得最好的性能,可以使用編譯選項、軟件流水、內聯函數和循環展開等方法來對代碼進行優化,以提高代碼執行速度,并減小代碼尺寸。
3.2.1 編譯器選項優化
C/C++編譯器可以對代碼進行不同級別的優化。高級優化由專門的優化器完成,低級的和目標DSP有關的優化由代碼生成器完成。圖3為編譯器、優化器和代碼生成器的執行圖。

當優化器被激活時,將完成圖3所示的過程。C/C++語言源代碼首先通過一個完成預處理的解析器(Parser),生成一個中間文件(.if)作為優化器(Optimi-zer)的輸入。優化器生成一個優化文件(.opt),這個文件作為完成進一步優化的代碼生成器(Co
最簡單執行優化的方法是采用cl6x編譯程序,在命令行設置一On選項即可。n是優化的級別(n為0,1,2,3),它控制優化的類型和程度。
3.2.2 軟件流水優化
軟件流水是編排循環指令,使循環的多次迭代并行執行的技術。使用一02和一03選項編譯C/C++程序時,編譯器就從程序中收集信息,嘗試對程序循環做軟件流水。
圖4顯示一個軟件流水循環。圖4中A,B,C,D和E表示1次迭代中的各條指令;A1,A2,A3,A4和A5表示一條指令執行的各階段。循環中,一個周期最多可并行執行5條指令,即圖中陰影部分所示的循環核(Loop Kernel)部分。循環核前面的部分稱為流水循環填充(Pipelined Loop Prolog),循環核后面部分稱為循環排空(Pipelined Loop Epilog)。

3.2.3 內聯函數優化
通過下面的方法改進C語言程序,可使編譯出的代碼性能顯著提高:
(1)使用intrinsics(內聯函數)替代復雜的C/C++代碼;
(2)使用字(Word)訪問存放在32位寄存器的高16位和低16位字段的數據;
(3)使用雙字訪問存放在64位寄存器的32位數據(僅指C64xx/C67XX)。
C6000編譯器提供了許多內聯函數,它們直接對應著C62X/C64X/C67X指令可快速優化C代碼。這些內聯函數不易用C/C++語言實現其功能。內聯函數用前下劃線“_”特別標示,其使用方法與調用函數一樣。例如C語言的飽和加法只能寫為需要多周期的函數:

這段復雜的代碼可以用_sadd()內聯函數實現,它是一個單周期的C6x指令。
result=_sadd(a,b);
要提高C6000數據處理率,應使一條Load/Store指令能訪問多個數據。C6000有與內聯函數相關的指令,例如_add2(),_mpyhl(),_mpylh()等,這些操作數以16位數據形式存儲在32位寄存器的高位部分和低位部分。當程序需要對一連串短型數據進行操作時,可使用字1次訪問2個短型數據,然后使用C6000相應指令來處理數據。相似的在C64x或C67x中,有時需要執行64位的LDDW來訪問兩個32位數據,4個16位數據,甚至8個8位數據。
3.2.4 循環展開
循環展開是改進性能的另一種,即把小循環的迭代展開,以讓循環的每次迭代出現在代碼中。這種方法可增加并行執行的指令數。當每次迭代操作沒有充分利用C6000結構的所有資源時,可使用循環展開提高性能。
有3種使循環展開的方法:
(1)編譯器自動執行循環展開;
(2)在程序中使用UNROLL偽指令建議編譯器做循環展開;
(3)用戶自己在C/C++代碼中展開。
3.3 匯編優化
在對C/C++代碼使用了所有的C/C++優化手段之后,如果仍然不滿意代碼的性能,就可以寫線性匯編程序,然后用匯編優化器進行優化,生成高性能的代碼。
3.3.1 寫線性匯編
使用C6000的剖析工具(Profiling Tools)可以找到代碼中最耗費時間的部分,就是這部分需要用線性匯編重寫。線性匯編代碼與匯編源代碼相似,但是,線性匯編代碼中沒有指令延遲和寄存器使用信息。這樣做的目的是由匯編優化器來為自己設定這些信息。
寫線性匯編代碼時,需要知道:匯編優化器偽指令、影響匯編優化器行為的選項、TMS320C6000指令、線性匯編源語句語法、指定寄存器或寄存器組、指定功能單元、源代碼注釋等。
3.3.2 匯編優化器優化
匯編優化器的任務主要有:
(1)編排指令,最大限度的利用C6000的并行能力;
(2)確保指令滿足C6000的延遲要求(Latency Requirements);
(3)為源代碼分配寄存器。
4 結 語
C6000系列的DSP C/c++代碼優化比傳統的代碼優化要方便的多,但要真正發揮其芯片的工作效率還是需要一定的經驗和技巧。這不僅要求開發人員熟悉其硬件體系,還要求對編譯器的編譯原理有一定的理解。另外,在C語言層面上要達到DSP芯片的峰值即8條指令并行是很難的,大多情況下都只能達到6.7條指令并行。在實際開發中,若優化結果已達到6,7條指令并行卻還離實時的要求相差很遠,再花大量的人力去力求達到8條指令并行是不經濟的,此時應該考慮其他的技術改進或策略上的調整以求達到目的。
]]> 其中,TI公司推出的TMS320C6000系列DSP器件更是在許多需要進行大量數字信號處理運算并兼顧高實時性要求的場合得以應用TMS320C6000系列DSP的系統設計過程中,DSP器件的啟動加載設計是較難解決的問題之一
其中,TI公司推出的TMS320C6000系列DSP器件更是在許多需要進行大量數字信號處理運算并兼顧高實時性要求的場合得以應用TMS320C6000系列DSP的系統設計過程中,DSP器件的啟動加載設計是較難解決的問題之一
C6000系列DSP的啟動加載方式包括不加載、主機加載和EMIF加載3種
3種加載方式的比較:不加載方式僅限于存儲器0地址不是必須映射到RAM空間的器件,否則在RAM空間初始化之前CPU會讀取無效的代碼而導致錯誤;主機加載方式則要求必須有一外部主機控制DSP的初始化,這將增加系統的成本和復雜度,在很多實際場合是難以實現的;EMIF加載方式的DSP與外部ROM/Flash接口較為自由,但片上Bootloader工具自動搬移的代碼量有限(1 KB/64 KB)本文主要討論常用的EMIF加載方式
1 EMIF加載分析
實際應用中,通常采用的是EMIF加載方式,把代碼和數據表存放在外部的非易失性存儲器里(常采用Flash器件)
下面以TMS320C6000系列中最新的浮點CPU——TMS320C6713(簡稱“C6713”)為例,詳細分析其EMIF加載的軟硬件實現
硬件方面,其與16位寬度的Flash器件的接口如圖1所示
 |
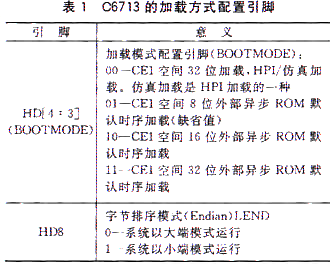
對于不同的DSP器件,加載方式的配置引腳稍有不同C6713的配置引腳及其定義如表1所列
 |
應用程序的大小決定了片上的Bootloadet工具是否足夠把所有的代碼都搬移到內部RAM里對于C6713,片上的Bootloader工具只能將1 KB的代碼搬入內部RAM通常情況下,用戶應用程序的大小都會超過這個限制所以,需要在外部Flash的前1 KB范圍內預先存放一小段程序,待片上Bootloader工具把此段代碼搬移入內部并開始執行后,由這段代碼實現將Flash中剩余的用戶應用程序搬移入內部RAM中此段代碼可以被稱作一個簡單的二級Bootloader
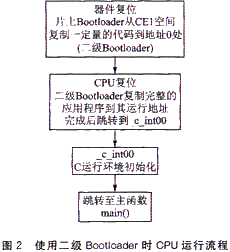
圖2所示為使用二級Bootloader時的CPU運行流程
 |
使用二級Bootloader需要考慮以下幾個事項:
·需要燒寫的COFF(公共目標文件格式)段的選擇;
·編寫二級Bootloader;
·將選擇的COFF段燒入Flash
一個COFF段就是占據一段連續存儲空間的程序或數據塊COFF段分為3種類型:代碼段、初始化數據段和未初始化數據段
對于EMIF加載方式,需要加載的鏡像由代碼段(如.vectors和.text等)和初始化數據段(如.cinit,.const,.switch,.data等)構成另外,可以單獨定義一個.boot-load段存放二級Bootloader此段也需要寫入Flash
所有未初始化的數據段(如.bss等)都不需要燒入到Flash中
2 二級Bootloader的編寫
·由于執行二級Bootloader時C的運行環境還未建立起來,所以必須用匯編語言編寫二級Bootloader可參照其他類似文獻及TI相關文檔此處不再贅述
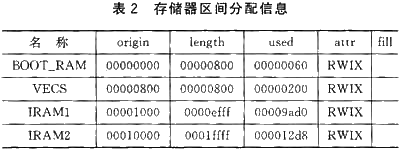
·CCS中用戶工程編譯鏈接后產生的.map文件包含了存儲器的詳細分配信息一個典型的map文件中包含的存儲器分配信息如表2所列
·與cmd文件不同,map文件不僅包含了各段存儲在哪一段內存空間的信息,從map文件中還可以具體知道每個內存區間中有多少被實際使用(燒寫Flash時會用到這個參數)內存區間中未被使用部分是不需要寫入Flash內容的,實際被使用的部分才是真正需要寫人到Flash中的內容
3 Flash的燒寫
把代碼等寫入Flash的辦法大體上可分為以下幾種:
① 使用通用燒寫器寫入
② 使用CCS中自帶的FlashBurn工具
③ 用戶自己編寫燒寫Flash的程序,由DSP將內存映像寫入Flash
其中,使用通用燒寫器燒寫需要將內存映像轉換為二進制或十六進制格式的文件,而且要求Flash器件是可插拔封裝的這將導致器件的體積較大,給用戶的設計帶來不便
使用TI公司提供的FlashBurn工具的好處在于使用較為直觀FlashBurn工具提供的圖形界面可以方便地對Flash執行擦除、編程和查看內容等操作但這種力法的缺點也不少:首先,FlashBurn工具運行時需要下載一個.out鏡像(FBTC,FlashBurn Target Component)到DSP系統中,然后由上位PC機通過仿真器發送消息(指令和數據)給下位DSP,具體對Flash的操作由FBTC執行然而,這個FBTC一般是針對TI公司提供的DSP專門編寫的,與板上使用的Flash的接口寬度(默認是8位)、操作關鍵字(因生產廠商不同而各異)都有關,所以,對用戶自己制作的硬件不一定適合例如:如果用戶自己的電路板上使用的是與DSK同品牌的Flash芯片,接口為16位數據寬度,那么,使用FlashBur’n工具燒寫將最多只有一半的Flash容量能夠被使用,要想正確實現]EMIF加載就必須選擇8位加載方式這就造成了Flash存儲器資源的浪費,同時限制了用戶開發的靈活性
雖然TI公司提供了FBTC的源代碼供有需要的用戶修改,但這樣用戶需要去了解FBTC的運行機制及其與上位機的通信協議,并對Flash燒寫函數進行修改用戶可能需要修改的幾個地方如下:對Flash編程的關鍵字和地址,BurnFlash函數中的數據指針和EMIF口的配置(針對1.0版本FBTC)這就給用戶開發帶來了不便把開發時間浪費在了解一個并不算簡單的Flash燒寫工具上并不是一個好的選擇
 |
其次,FlashBurn工具不能識別.out文件,只接受..ex的十六進制文件,因此,需要將.out文件轉換為.hex文件這個轉換的工具就是TI公司提供的Hex6x.exe工具轉換過程的同時,需要一個cmd文件(即圖3中的Hex.cmd)指定作為輸入的.out文件,輸出的.hex文件的格式,板上Flash芯片的類型和大小,需要寫入Flash中的COFF段名等
 |
使用用戶自己編寫的燒寫Flash的程序較為靈活,避免了文件格式轉換的繁瑣不過,此方法要求用戶對自己使用的Flash芯片較為熟悉
通常采用的Flash燒寫程序是單獨建立一個工程的辦法:先把用戶應用程序(包含二級Bootloader)編譯生成的.out文件裝載到目標DSP系統的RAM中,再把燒寫Flash的工程編譯生成的.out文件裝載到目標DSP系統RAM的另一地址范圍,執行Flash燒寫程序,完成對Flash的燒寫這個辦法要注意避免兩次裝載可能產生的地址覆蓋,防止第2次裝載修改了應該寫入Flash的第1次裝載的內容
實際上,可以將Flash燒寫程序嵌入到用戶主程序代碼中去,比單獨建立一個燒寫Flash的工程更為方便Flash芯片的燒寫程序段如下:
 |
 |
ChipErase函數和ProgramFlashArray函數的編寫可參照用戶使用的Flash芯片的Datasheet以及參考文獻[1]
ProgramFlashArray函數的第1個參數是源地址指針(指向內部Ram),第2個參數是目標地址指針(指向外部Flash),第3個參數是要寫入的數據長度(單位為字)
編寫Flash燒寫函數時有3點需要注意:
① 指向Flash地址的指針由于C6713的低兩位地址用于譯碼作字節選擇,地址總線的最低位是EA2,所以,邏輯地址需要適當的移位才能正確地指向日標
對8位存儲器而言,應該左移2位;對16位存儲器而言,應該左移1位;對于32位存儲器,則不需要移位例如要從(往)Flash的0x00000003地址讀(寫)一個字,其邏輯地址應該是0x90000000+(0x0003<<1),而非0x90000003
② map文件中各內存區間被實際占用的尺寸大小是以字節為單位的,而ProgramFlashArray函數寫入Flash的數據單位為字,所以需要將map文件中得到的尺寸大小的一半作為ProgramFlashArray函數的參數
③ 燒寫函數中使用了flash_burned常量作為判斷是否需要對Flash操作的依據,且將其初始化為1這是為了避免Flash加載之后會執行對Flash的操作此變量應在燒寫Flash時手動修改為0
在仿真加載方式下,可以在CCS里的watchwindow窗口手動修改flash_burned常量為0,強迫CPU進入對Flash編程的程序段實驗證明,在仿真加載方式下手動修改flash_burned并不影響寫入到Flash中的flash_burn-ed的值(仍為1),所以,寫入Flash的flash_burned的值仍然是1在系統Flash加載之后,CPU就會跳過此段代碼,實現正確運行
4 結 論
本Flash加載方案以C6713為例,稍加修改即可適用于TMS320C6000系列的其他DSP器件經過在研制的伺服測試平臺中的應用,證明本方法切實可行且易于實現,避免了目標文件格式的轉換,比通常采用的FlashBurn工具使用起來更靈活方便,用戶可以通過簡單修改Flash燒寫函數使之適應自己的硬件情況對于Flash器件接口與TI的DSP不一致的情況,本方案是一個很好的選擇
TMS320C6000系列DSP(數字信號處理器)是TI公司最新推出的一種并行處理的數字信號處理器。它是基于TI的VLIW技術的,其中TMS320C62xx是定點處理器,TMS320C67xx是浮點處理器。本文主要討論TMS320C6201。該處理器的工作頻率最高可以采用50MHz,經內部4倍頻后升至200MHz,每個時鐘周期最多可以并行執行8條指令,從而可以實現1600MIPS的定點運算能力,而且完成1024定點FFT的時間只需70μs。
1.1 TMS320C6000的硬件結構
圖1是TMS320C6000 CPU的結構圖。

TMS320C6000的CPU有兩個數據通道A和B,每個通道有16個32位字長的寄存器(A0~A15,B0~B15),四個功能單元(L,S,M,D),每個功能單元負責完成一定的算術或者邏輯運算。A、B兩通道的寄存器并不是完全共享,只能通過TMS320C6000提供的兩個交換數據通道1X、2X,才能實現處理單元從不同通道的寄存器堆那里獲取32位字長的操作數。
TMS320C6000的地址線為32位,存儲器尋址空間是4G。C6201片內集成有1Mbit SRAM——512Kbit的程序存儲器(根據需要可全部配置成Cache)和512Kbit的數據存儲器。通過片內的程序存儲空間控制器,CPU一次可以取出256bit,即一次最多可以取出8條32位指令。
C6201有32位的外部存儲接口EMIF為CPU訪問外圍設備提供了無縫接口。外圍設備可以是同步動態存儲器(SDRAM)、同步突發靜態存儲器(SBSRAM)、靜態存儲器(SRAM)、只讀存儲器(ROM),也可以是FIFO寄存器。
為了便于進行多信道數字信號處理,TMS320C6000配備了多信道帶緩沖能力的串口McBSP。McBSP的功能非常強大,除具有一般DSP串口功能之外,還可以支持T1/E1、ST-BUS、IOM2、SPI、IIS等不同標準。McBSP最多支持128個信道;支持多種數據格式(8/12/16/20/24/32bit)的傳輸;可自動進行u律、A律壓擴。其工作速率可達到1/2時鐘速率。
TMS320C6000提供的16位主機接口(HPI)使得主機設備可以直接訪問DSP的存儲空間。通過內部或外部存儲空間,主機和DSP可以交換信息。主機也可以利用HPI直接訪問映射進存儲空間的外圍設備。
DSP器件一般都帶有DMA控制器,可以在CPU操作的后臺進行數據傳輸。TMS320C6201的DMA控制器有4個獨立的可編程通道,可以同時進行四個不同的DMA操作,每個通道的優先級可以通過編程設定。每個通道可以根據需要傳輸8/16/32bit的數據,并且DMA控制器可以訪問全部32位的地址空間。此外,還有一個輔助通道允許DMA控制器響應主機通過HPI口發來的請求。
1.2 指令系統
C62xx和C67xx共享同一個指令集。C67xx可以使用所有的C62xx指令,但因為C67xx是浮點芯片,所以C67xx的指令集中有一些指令只能用于浮點運算。TMS320C6201CPU的設計采用了類似于RISC的結構,指令集簡單、運算速度快。8個功能單元負責不同功能的運算,指令和功能單元之間存在一個映射關系。其中,L單元有23條指令,M單元有20條指令,S單元29有條指令,D單元有26條指令。
TMS320C6201的大部分指令都可在單周期內完成,都可以直接對8/16/32bit數據進行操作。同時,TMS320C6201指令集針對數字信號處理算法提供了一些特殊指令:為復雜計算提供的40bit的特殊操作的加法運算;有效的溢出處理和歸一化處理;簡潔的位操作功能等。TMS320C6201中最多可以有8條指令同時并行執行;所有指令均可條件執行。以上所有特點提高了指令的執行效率、減小了代碼長度、大大減少了因跳轉引起的開銷、提高了編碼效率。
流水線操作是DSP實現高速度、高效率的關鍵技術之一。TMS320C6000只有在流水線充分發揮作用的情況下,才能達到1600MIPS的速度。C6000的流水線分為三個階段:取指、解碼、執行,總共11級。和以前的C3x、C54x相比,有非常大的優勢,主要表現在:簡化了流水線的控制以消除流水線互鎖;增加流水線的深度以消除傳統流水線結構在取指、數據訪問和乘法操作上的瓶頸。其中取指、數據訪問分為多個階段,使得C6000可以高速地訪問存儲空間。
2 優化編程的幾個方法
使用TMS320C6000進行程序設計時,首先的感覺是匯編指令集太小了。C6000在設計時采用了一種類RISC機的結構,運算速度特別快,但是指令集卻非常簡單。象DSP算法中常用的乘加指令、循環操作指令等,在C54x和C3x中兩條指令就可以完成的功能,而在C6000中卻需要一個循環體,所以它的程序設計一般比較復雜。要想充分發揮C6000的運算能力,必須從它的硬件結構出發,最大限度地利用八個功能單元,使用軟件流水線,盡量讓程序無沖突的并行執行。
并行處理的長處在于,在處理彼此之間沒有承接關系的運算時,在CPU資源允許的情況下可以并行完成。但對于前后有承接關系或者判斷、跳轉頻繁的情況,就無法發揮并行的優勢。一般循環體都滿足并行處理的條件,并且循環體往往是程序中耗時最長的地方。因此進行C6000應用開發時應將優化重點放在循環體上。為了降低開發難度,C6000提供了很多在高級語言(如ANSI C)一級對程序進行優化的方法。在應用滿足實時性處理要求時,應盡量采用這種方法。但是這種方法的效率比較低,C語言優化最好的例子是點乘,這種循環使用C語言進行優化可以百分之百地的利用CPU資源,程序的并行性達到最好。但是我們在做20點的點乘時發現它的耗時是匯編語言程序的3倍。所以如果系統的實時性要求比較高,就不能使用這種優化方法了。
這時可以考慮使用線性匯編語言進行開發。線性匯編語言是TMS320C6000中獨有的一種編程語言,介于高級語言和低級語言之間。因為在用手寫匯編語言進行應用開發時,開發者除了要精通C6000的指令系統之外,還必須為指令分配功能單元、考慮指令的延遲和功能單元之間的配合以及合理分配使用32個寄存器,才能寫出高效的并行指令,發揮C6000的威力。上面任何一個方面出現問題,都會嚴重影響算法的效率。
線性匯編語言的指令系統和匯編語言的指令系統完全相同,但是它有自己的匯編優化器指令系統,用于和匯編優化器配合使用。與匯編語言的最大區別在于,編寫線性匯編語言時不需要考慮指令的延時、寄存器的使用和功能單元的分配,完全可以按照高級語言的方式進行編寫。當然由于它不是高級語言,有許多編程的限制。例如,在優化循環體時,不能使用跳轉到循環體之外的跳轉指令;另外計數器只能使用減計數,如果使用加計數,優化器將不能工作等等。但總的說來,它的代碼效率遠遠高于高級語言,而且開發難度和開發周期比匯編語言要小得多。
在實際開發過程中需要具體情況具體分析,選擇一種高效、快捷的開發方法。以下結合應用開發中的幾個模塊來簡述我們使用的優化方法。
2.1 使用匯編語言
使用匯編語言進行并行編程難度比較大。但在有些情況下,程序中數據有非常強的承接關系,并且該程序體邏輯關系清楚,使用的寄存器不超過32個,這時直接使用匯編語言實現,效率會更高。另外,有些使用C語言比較難實現的運算函數,在C6000的匯編指令集中可能有專用DSP指令,這時就可以直接使用匯編語言實現。
使用匯編語言進行編程時特別需要注意的是C6000指令的延遲情況,有些指令并不是立刻就能得到結果。C6000指令集中有延遲的指令如表1所示。

例1 32位歸一化函數norm_l()
short norm_l(long L_var1)
{short var_out;
if (L_var1 == 0L) {
var_out = (short)0;
}
else {
if (L_var1 == (long)0xffffffffL) {
var_out = (short)31;
}
else {
if (L_var1 < 0L) {
L_var1 = *L_var1;
}
for(var_out=(short)0;L_var1<(long)0x40000000L;
var_out++) {
L_var1 <<= 1L;
}}}
return(var_out);
}
使用匯編語言進行優化:
.global _norm_l
_norm_l:
B B3
CMPEQ 0,A4,B0
[!B0] NORM A4,A4
NOP 3
消耗時間(時鐘周期):C語言norm_l()為723;匯編語言為11。
2.2 使用線性匯編語言重寫整個函數
對于某些以循環體為主的函數可以使用線性匯編語言重寫整個函數。使用匯編優化器進行優化之后,效率是非常高的。
]]>
隨著近年來數字信號處理器(DSP)技術的迅猛發展,其越來越廣泛地應用于國民經濟的各個領域中。其中,TI公司推出的TMS320C6000系列DSP器件更是在許多需要進行大量數字信號處理運算并兼顧高實時性要求的場合得以應用。TMS320C6000系列DSP的系統設計過程中,DSP器件的啟動加載設計是較難解決的問題之一。
C6000系列DSP的啟動加載方式包括不加載、主機加載和EMIF加載3種。
3種加載方式的比較:不加載方式僅限于存儲器0地址不是必須映射到RAM空間的器件,否則在RAM空間初始化之前CPU會讀取無效的代碼而導致錯誤;主機加載方式則要求必須有一外部主機控制DSP的初始化,這將增加系統的成本和復雜度,在很多實際場合是難以實現的;EMIF加載方式的DSP與外部ROM/Flash接口較為自由,但片上Bootloader工具自動搬移的代碼量有限(1 KB/64 KB)。本文主要討論常用的EMIF加載方式。
1 EMIF加載分析
實際應用中,通常采用的是EMIF加載方式,把代碼和數據表存放在外部的非易失性存儲器里(常采用Flash器件)。
下面以TMS320C6000系列中最新的浮點CPU——TMS320C6713(簡稱“C6713”)為例,詳細分析其EMIF加載的軟硬件實現。
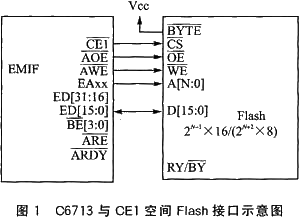
硬件方面,其與16位寬度的Flash器件的接口如圖1所示。
對于不同的DSP器件,加載方式的配置引腳稍有不同。C6713的配置引腳及其定義如表1所列。
應用程序的大小決定了片上的Bootloadet工具是否足夠把所有的代碼都搬移到內部RAM里。對于C6713,片上的Bootloader工具只能將1 KB的代碼搬入內部RAM。通常情況下,用戶應用程序的大小都會超過這個限制。所以,需要在外部Flash的前1 KB范圍內預先存放一小段程序,待片上Bootloader工具把此段代碼搬移入內部并開始執行后,由這段代碼實現將Flash中剩余的用戶應用程序搬移入內部RAM中。此段代碼可以被稱作一個簡單的二級Bootloader。
圖2所示為使用二級Bootloader時的CPU運行流程。
使用二級Bootloader需要考慮以下幾個事項:
◇需要燒寫的COFF(公共目標文件格式)段的選擇;
◇編寫二級Bootloader;
◇將選擇的COFF段燒入Flash。
一個COFF段就是占據一段連續存儲空間的程序或數據塊。COFF段分為3種類型:代碼段、初始化數據段和未初始化數據段。
對于EMIF加載方式,需要加載的鏡像由代碼段(如.vectors和.text等)和初始化數據段(如.cinit,.const,.switch,.data等)構成。另外,可以單獨定義一個.boot-load段存放二級Bootloader。此段也需要寫入Flash。
所有未初始化的數據段(如.bss等)都不需要燒入到Flash中。
2 二級Bootloader的編寫
由于執行二級Bootloader時C的運行環境還未建立起來,所以必須用匯編語言編寫。二級Bootloader可參照其他類似文獻及TI相關文檔。此處不再贅述。
CCS中用戶工程編譯鏈接后產生的.map文件包含了存儲器的詳細分配信息。一個典型的map文件中包含的存儲器分配信息如表2所列。
與cmd文件不同,map文件不僅包含了各段存儲在哪一段內存空間的信息,從map文件中還可以具體知道每個內存區間中有多少被實際使用(燒寫Flash時會用到這個參數)。內存區間中未被使用部分是不需要寫入Flash內容的,實際被使用的部分才是真正需要寫人到Flash中的內容。
3 Flash的燒寫
把代碼等寫入Flash的辦法大體上可分為以下幾種:
① 使用通用燒寫器寫入。
② 使用CCS中自帶的FlashBurn工具。
③ 用戶自己編寫燒寫Flash的程序,由DSP將內存映像寫入Flash。
其中,使用通用燒寫器燒寫需要將內存映像轉換為二進制或十六進制格式的文件,而且要求Flash器件是可插拔封裝的。這將導致器件的體積較大,給用戶的設計帶來不便。
使用TI公司提供的FlashBurn工具的好處在于使用較為直觀。FlashBurn工具提供的圖形界面可以方便地對Flash執行擦除、編程和查看內容等操作。但這種力法的缺點也不少:首先,FlashBurn工具運行時需要下載一個.out鏡像(FBTC,FlashBurn Target Component)到DSP系統中,然后由上位PC機通過仿真器發送消息(指令和數據)給下位DSP,具體對Flash的操作由FBTC執行。然而,這個FBTC一般是針對TI公司提供的DSP專門編寫的,與板上使用的Flash的接口寬度(默認是8位)、操作關鍵字(因生產廠商不同而各異)都有關,所以,對用戶自己制作的硬件不一定適合。例如:如果用戶自己的電路板上使用的是與DSK同品牌的Flash芯片,接口為16位數據寬度,那么,使用FlashBur’n工具燒寫將最多只有一半的Flash容量能夠被使用,要想正確實現]EMIF加載就必須選擇8位加載方式。這就造成了Flash存儲器資源的浪費,同時限制了用戶開發的靈活性。
雖然TI公司提供了FBTC的源代碼供有需要的用戶修改,但這樣用戶需要去了解FBTC的運行機制及其與上位機的通信協議,并對Flash燒寫函數進行修改。用戶可能需要修改的幾個地方如下:對Flash編程的關鍵字和地址,BurnFlash函數中的數據指針和EMIF口的配置(針對1.0版本FBTC)。這就給用戶開發帶來了不便。把開發時間浪費在了解一個并不算簡單的Flash燒寫工具上并不是一個好的選擇。
其次,FlashBurn工具不能識別.out文件,只接受..ex的十六進制文件,因此,需要將.out文件轉換為.hex文件。這個轉換的工具就是TI公司提供的Hex6x.exe工具。轉換過程的同時,需要一個cmd文件(即圖3中的Hex.cmd)指定作為輸入的.out文件,輸出的.hex文件的格式,板上Flash芯片的類型和大小,需要寫入Flash中的COFF段名等。
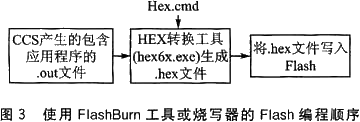
使用用戶自己編寫的燒寫Flash的程序較為靈活,避免了文件格式轉換的繁瑣。不過,此方法要求用戶對自己使用的Flash芯片較為熟悉。
通常采用的Flash燒寫程序是單獨建立一個工程的辦法:先把用戶應用程序(包含二級Bootloader)編譯生成的.out文件裝載到目標DSP系統的RAM中,再把燒寫Flash的工程編譯生成的.out文件裝載到目標DSP系統RAM的另一地址范圍,執行Flash燒寫程序,完成對Flash的燒寫。這個辦法要注意避免兩次裝載可能產生的地址覆蓋,防止第2次裝載修改了應該寫入Flash的第1次裝載的內容。
實際上,可以將Flash燒寫程序嵌入到用戶主程序代碼中去,比單獨建立一個燒寫Flash的工程更為方便。Flash芯片的燒寫程序段如下:


ChipErase函數和ProgramFlashArray函數的編寫可參照用戶使用的Flash芯片的Datasheet以及參考文獻[1]。
ProgramFlashArray函數的第1個參數是源地址指針(指向內部Ram),第2個參數是目標地址指針(指向外部Flash),第3個參數是要寫入的數據長度(單位為字)。
編寫Flash燒寫函數時有3點需要注意:
① 指向Flash地址的指針。由于C6713的低兩位地址用于譯碼作字節選擇,地址總線的最低位是EA2,所以,邏輯地址需要適當的移位才能正確地指向日標。
對8位存儲器而言,應該左移2位;對16位存儲器而言,應該左移1位;對于32位存儲器,則不需要移位。例如要從(往)Flash的0x00000003地址讀(寫)一個字,其邏輯地址應該是0x90000000+(0x0003<<1),而非0x90000003。
② map文件中各內存區間被實際占用的尺寸大小是以字節為單位的,而ProgramFlashArray函數寫入Flash的數據單位為字,所以需要將map文件中得到的尺寸大小的一半作為ProgramFlashArray函數的參數。
③ 燒寫函數中使用了flash_burned常量作為判斷是否需要對Flash操作的依據,且將其初始化為1。這是為了避免Flash加載之后會執行對Flash的操作。此變量應在燒寫Flash時手動修改為0。
在仿真加載方式下,可以在CCS里的watchwindow窗口手動修改flash_burned常量為0,強迫CPU進入對Flash編程的程序段。實驗證明,在仿真加載方式下手動修改flash_burned并不影響寫入到Flash中的flash_burn-ed的值(仍為1),所以,寫入Flash的flash_burned的值仍然是1。在系統Flash加載之后,CPU就會跳過此段代碼,實現正確運行。
4 結 論
本Flash加載方案以C6713為例,稍加修改即可適用于TMS320C6000系列的其他DSP器件。經過在研制的伺服測試平臺中的應用,證明本方法切實可行且易于實現,避免了目標文件格式的轉換,比通常采用的FlashBurn工具使用起來更靈活方便,用戶可以通過簡單修改Flash燒寫函數使之適應自己的硬件情況。對于Flash器件接口與TI的DSP不一致的情況,本方案是一個很好的選擇。
DSP芯片以其低成本、低功耗、高運算速度等優勢得到了飛速發展與廣泛運用。但目前各DSP廠商提供的開發環境(如TI的CCS)大多采用G/C++或匯編語言作為開發語言,與編寫Matlab程序相比,前者要復雜得多。
Matlab是一個強大的分析、計算和可視化工具,且編程非常方便。Simulink是Matlab產品中用來建模、分析和仿真各種動態系統的圖形化工具。通過豐富的功能模塊,可以迅速地創建動態系統模型。同時Simulink也是Real-Time Workshop(以下簡稱RTW)的支持平臺。通過RTW可以自動生成面向不同目標的代碼。
Matlab輔助DSP進行混合編程,很多學者作了許多研究和嘗試。文獻[1]提出了由Matlab向DSP傳送原始數據以及DSP反饋處理后數據的方法,充分利用了Matlab優秀的可視化功能。但仍然要在DSP開發環境中編寫復雜的代碼。文獻[2,3]利用工具包——Matlab Link for CCS Development Tools(以下簡稱CCSLink),實現了在Matlab、TI開發環境和DSP硬件間的雙向連接,極大地降低了開發人員調試DSP代碼的難度和工作量。但CCSLink只用于DSP程序的調試、數據傳遞和驗證等過程,同樣需要編寫復雜的DSP代碼。而另一工具包——ETTIC6000,利用RTW直接從Simulink模型生成面向TI C6000 DSP的高效代碼,不再需要傳統的DSP編程過程。本文在此基礎上進行研究,設計并自動生成FIR低通濾波器的DSP代碼。
2 ETTIC6000的功能、特點及開發DSP代碼過程
ETTIC6000是Math Works公司和TI公司聯合開發的工具包。利用RTW直接從Simulink模型生成面向TI的C6701 EVM和C6711 DSK目標板的可執行文件或CCS工程。在DSP代碼自動生成過程中,ETTIC6000必須與Simulink,RTW,CCS和TI目標板等軟硬件相結合才能充分顯現其功能。它們之間的關系如圖1所示。
應用ETTIC6000開發DSP代碼的過程一般經過如下幾步:
(1)概念構思和DSP處理算法設計。
(2)在Simulink環境下,利用Matlab基本模塊,Simulink基本模塊,數字信號處理工具箱,以及專門面向TI C6000的模塊組等模塊,構建算法模型并運行仿真。并非所有模塊都可以轉化為DSP代碼并順利編譯。例如一些面向Win32的程序模塊在轉化為DSP代碼或在CCS中進行編譯時就會出現無法兼容或找不到相關頭文件等錯誤提示。
(3)對仿真結果進行評價,若仿真結果滿意,即可在模型中加入C6701 EVM或C6711 DSK目標板的輸入輸出模塊。否則,重新進行算法設計、建模、仿真。
(4)在設計好的面向具體目標板的模型中,設置Simulation選項,包括RTW中的編譯連接等選項。
(5)執行代碼自動生成、編譯、調試并裝載到目標板上運行。
從整個設計過程來看,DSP開發人員只需在Matlab中進行Simulink模型設計、構建與仿真。省去了編寫、調試復雜DSP代碼的過程。下面以實現FIR低通濾波器為例,詳細闡述應用ETTIC6000開發DSP代碼的全部過程。
 |
3 FIR低通濾波器實現過程
此系統要求對頻率分別為200 Hz,600 Hz和1 000 Hz,幅度為1的混合正弦信號進行低通濾波,保留200 Hz的正弦信號。采用Simulink環境下的FDATool工具設計FIR低通濾波器。在以下軟硬件環境中設計并通過測試,以下軟件均采用默認安裝路徑,若軟硬件環境不同,相應的參數設置將有很大差別。
硬件環境:TMS320C6711 DSK開發板、PC聲卡、雙頭音頻線等。
軟件環境:Matlab 7.4(R2007a),CCStudio 3.1,Simulink 6.6,Real-Time Workshop 6.6,Target forTI C6000(tm)3.2,Link for Code ComposerStudio 3.0。
Matlab附帶軟件可以在命令窗口通過ver命令查看,附帶軟件的使用可以充分利用help命令。
3.1 Simulink環境下構建算法模型并仿真
依據設計思想,在Simulink環境下,通過Simulink基本模塊庫和數字信號處理工具箱構建如圖2所示系統模型。三個輸入信號模塊關鍵參數設置:頻率分別設置為200 Hz,600 Hz和1 000 Hz;幅度為1;采樣頻率為1 600 Hz。FDA Tool關鍵參數設置:濾波類型選擇低通;階數為80;采樣頻率為1 600 Hz;起始頻率為100 Hz;截至頻率為500 Hz。
 |
對圖2所示模型運行仿真,仿真結果如圖3所示。從濾波后的波形看,此濾波器的參數設置比較合理。
 |
3.2 構建面向C6711 DSK目標模型
(1)依據仿真模型利用ETTIC6000中C6711 DSK輸入輸出模塊構建如圖4所示面向C6711 DSK目標模型。C6711 DSK ADC與C6711 DSK DAC參數采用默認設置。FDA Tool參數與仿真模型中參數保持一致,設置完成后將模型保存在Matlab默認目錄下,命名為myfilter.mdl。
 |
(2)依據圖4構建如圖5所示的硬件平臺。TMS320C6711 DSK與PC通過并口線連接;信號源由PC聲卡輸出,經C6711 DSK A/D轉換后進行FIR低通濾波,由Line OUT將濾波后信號輸出至PC聲卡,最后采集聲卡信號,顯示濾波后波形。
3.3 DSP代碼自動生成
進行DSP代碼自動生成前,首先要安裝、配置相應的軟硬件環境。正確安裝、配置是此系統能夠成功運行的關鍵。具體配置有如下幾個方面:
(1)依據圖5實現硬件連接。在BIOS中將并口傳輸模式改為EPP模式;在DOS模式下,運行C:\CCS-tudio v3.1\C6000\DSK6X11\conftest\dsk6xtst.exe文件,可以檢測目標板是否連接正常;最后檢查PC聲卡輸入輸出是否正常。
(2)正確配置CCS。點擊Setup CCStudio V3.1,選擇C6711 DSK Port 378 EPP Mode模塊,點擊Add,設置并口地址為0x378;保存設置后退出。
(3)打開myfilter.mdl模型,展開simulation>Configuration Paraineters面板,面板中相應選項設置如下:
 |
其他選項設置為默認模式。
(4)點擊RTW面板Generate code按鈕,執行代碼自動生成過程,此時Matlab命令窗口將顯示如下信息:
 |
(5)CCStudio 3.1將自動運行,窗口中自動生成myfilter.pit的工程文件。
3.4 FIR低通濾渡器實現
(1)對myfiher.pit的工程文件在CCS中進行編譯、連接、裝載、運行。
(2)利用Matlab中的daqfcengen函數,可以實現向PC聲卡輸出端輸出波形。在Matlab命令窗口輸入daqfcengen命令,將顯示波形發生器窗口,將頻率設置為200 Hz,幅度設置為1,如圖6所示。點擊Start按鈕。在Matlab命令窗口繼續輸入daqfcengen命令,相繼實現頻率為600 Hz,1 000 Hz的波形輸出。這樣PC聲卡就輸出了三個不同頻率波形的疊加。
 |
(3)利用Matlab中的daqscope函數,可以實現顯示PC聲卡輸入端的波形。在Matlab命令窗口輸入daqscope命令,將顯示波形顯示器窗口,如圖7所示,即為濾波后的輸出波形。
 |
4 結 語
從整個FIR低通濾波器實現過程看,沒有編寫一行DSP代碼,全部采用圖形化的編程模式,生成的CCS工程文件既可供初學者學習、借鑒。又可供具有一定編程經驗的程序開發者對代碼進一步修改或優化,提高代碼執行效率。
從實驗結果看,設計的FIR低通濾波器濾波效果明顯。充分說明利用DSP代碼自動生成技術實現FIR低通濾波器的方法是可行的、高效的。Matlab輔助DSP在語音處理、圖像處理、通信、雷達等領域還有許多值得研究的地方。采用多語言工具進行程序開發也是今后發展的趨勢.
]]>表1 C6000的有延遲指令

例1 32位歸一化函數morm_1()
short morm_1(long L_var1)
{short var_out;
if (L_var1= = 0L){
var_out = (short)0;
}
else {
if (L_var1= = (logn)0xffffffffL{
var_out = (short)31;
}
else {
if (L_var1< 0L) {
L_var1 = ~L_var1;
}
for(var_out=(short)0;L_var1<(long)0x40000000L;
var_out++){
L_var1 <<= 1L;
}}}
return(var_out);
}
使用匯編語言進行優化;
.global norm_1
_norm1:
B B3
CMPEQ 0,A4,B0
[!B0] NORM A4,A4
NOP 3
消耗時間(時鐘周期):C語言norm_1()為723;匯編語言為11。
2.2 使用線性匯編語言重寫整個函數
對于某些以循環體為主的函數可以使用線性匯編語言重寫整個函數。使用匯編優化器進行優化之后,效率是非常高的。
下面例子是算法中計算幀能量的函數,其中包含兩個單循環體。進行優化時,首先要確定循環的次數。對于循環次數是變量的情況,優化器不進行并行優化;其次盡量減少數據存取次數,例如以32位存取指令對16位數據進行存取,可以節省一增的存取周期。仔細觀察C代碼,會發現兩次循環次數相同。第二個循環要用到第一個循環的結果,因此可以將兩個循環合并在一起,這樣就避免了在第二個循環中再從存儲器中取結果,減少了一半的Load操作。
Long Comp_En(short *Dpnt)
{ int i;
long Rez;
short Temp[60];
for (i=0;i<60;i ++) Temp [i] = shr(Dpnt[i],(short) 2);
Rez=(long) 0;
for (i=0; i <60; i ++) Rez=L_mac(Rez,Temp[i],Temp[i]);
return Rez;
}
相應的線性匯編程序如下:
.global _Comp_En ;函數名定義,對c變量前加_
_Comp_En .cproc Dpnt;函數頭定義,Dpnt是參數
.reg Rez,Rez1,Rez2,1 ;寄存器定義,不必考慮實際的寄存器分配
.reg t1,t2,x1,c1,m1,m2
zero Rez
zero Rez1
zero Rez2
mv Dpnt,c1
mvk 30,i ;確定循環次數。因為用LDW代替LDH,循五環次數減少一半。
loop1 .trip 30
ldw *c1++,x1
sh1 x1,16,t1
shr t1,2,t1
shr x1,2,t2 ;將兩個循環合在一起,又減少了一半的從內存取數據的時間。
smpyh t1,t1,m1
smpyh t2,t2,m2
sadd Rez1,m1,Rez1
sadd Rez2,m2,Rez2
[i] sub i,1,i ;循環計數器從30遞減
[i] b loop1
sadd Rez1,Rez2,Rez
.return Rez
.endproc
消耗時間(時鐘周期):C語言為32971;線性匯編語言為93。
2.3 使用線性匯編改寫復雜函數中的循環體
當函數的邏輯關系復雜,判斷、跳轉、函數調用情況特別多時,上面方法的效果就會在打折扣。這時可以使用線性匯編將其中的循環部分改寫成一個函數,以優化后的函數調用代替環部分,而不是優化整個復雜函數。
高速數字信號處理器件的應用范圍越來越廣,特別是在移動通信領域中,軟件無線電、智能天線等新技術的實都需要強大的實時數字信號處理的支持。TMS320C6000系列DSP完全可以滿足此類要求。但目前對于并行DSP技術的軟硬件開發還處在摸索階段,如何充分利用高速DSP的資源,是這方面的研究重點。本文研究了最新推出的TMS320C6000的優化策略,從工程和系統的角度總結出一套既能滿足實時性又能保證開發時效性的實用的優化編程方法,以供分饗。
]]>
C6000系列DSP的啟動加載方式包括不加載、主機加載和EMIF加載3種。
3種加載方式的比較:不加載方式僅限于存儲器0地址不是必須映射到RAM空間的器件,否則在RAM空間初始化之前CPU會讀取無效的代碼而導致錯誤;主機加載方式則要求必須有一外部主機控制DSP的初始化,這將增加系統的成本和復雜度,在很多實際場合是難以實現的;EMIF加載方式的DSP與外部ROM/Flash接口較為自由,但片上Bootloader工具自動搬移的代碼量有限(1KB/64KB)。本文主要討論常用的EMIF加載方式。
1 EMIF加載分析
實際應用中,通常采用的是EMIF加載方式,把代碼和數據表存放在外部的非易失性存儲器里(常采用Flash器件)。
下面以TMS320C6000系列中最新的浮點CPUTMS320C6713(簡稱“C6713”)為例,詳細分析其EMIF加載的軟硬件實現。
硬件方面,其與16位寬度的Flash器件的接口如圖1所示。

對于不同的DSP器件,加載方式的配置引腳稍有不同。C6713的配置引腳及其定義如表l所列。

應用程序的大小決定了片上的Bootloader工具是否足夠把所有的代碼都搬移到內部RAM里。對于C6713,片上的Bootloader工具只能將1 KB的代碼搬入內部RAM。通常情況下,用戶應用程序的大小都會超過這個限制。所以,需要在外部Flash的前l KB范圍內預先存放一小段程序,待片上Bootloader工具把此段代碼搬移入內部并開始執行后,由這段代碼實現將Flash中剩余的用戶應用程序搬移入內部RAM中。此段代碼可以被稱作一個簡單的二級Bootloader。
圖2所示為使用二級Bootloader時的CPU運行流程。

使用二級Bootloader需要考慮以下幾個事項:
◇需要燒寫的COFF(公共目標文件格式)段的選擇;
◇編寫二級Bootloader;
◇將選擇的COFF段燒入Flash。
一個COFF段就是占據一段連續存儲空間的程序或數據塊。COFF段分為3種類型:代碼段、初始化數據段和未初始化數據段。
對干EMIF加載方式,需要加載的鏡像由代碼段(如.vectors和.text等)和初始化數據段(如.cinit,.const,.switch,.data等)構成。另外,可以單獨定義一個.bootload段存放二級Bootloader。此段也需要寫入Flash。
所有未初始化的數據段(如.bss等)都不需要燒入到Flash中。
2 二級Bootloader的編寫
由于執行二級Bootloader時C的運行環境還未建立起來,所以必須用匯編語言編寫。二級Bootloader可參照其他類似文獻及TI相關文檔。此處不再贅述。
CCS中用戶工程編譯鏈接后產生的.map文件包含了存儲器的詳細分配信息。一個典型的map文件中包含的存儲器分配信息如表2所列
]]>C6000系列DSP的啟動加載方式包括不加載、主機加載和EMIF加載3種。
3種加載方式的比較:不加載方式僅限于存儲器0地址不是必須映射到RAM空間的器件,否則在RAM空間初始化之前CPU會讀取無效的代碼而導致錯誤;主機加載方式則要求必須有一外部主機控制DSP的初始化,這將增加系統的成本和復雜度,在很多實際場合是難以實現的;EMIF加載方式的DSP與外部ROM/Flash接口較為自由,但片上Bootloader工具自動搬移的代碼量有限(1 KB/64 KB)。本文主要討論常用的EMIF加載方式。
1 EMIF加載分析
實際應用中,通常采用的是EMIF加載方式,把代碼和數據表存放在外部的非易失性存儲器里(常采用Flash器件)。
下面以TMS320C6000系列中最新的浮點CPU——TMS320C6713(簡稱“C6713”)為例,詳細分析其EMIF加載的軟硬件實現。
硬件方面,其與16位寬度的Flash器件的接口如圖1所示。

對于不同的DSP器件,加載方式的配置引腳稍有不同。C6713的配置引腳及其定義如表1所列。

應用程序的大小決定了片上的Bootloadet工具是否足夠把所有的代碼都搬移到內部RAM里。對于C6713,片上的Bootloader工具只能將1 KB的代碼搬入內部RAM。通常情況下,用戶應用程序的大小都會超過這個限制。所以,需要在外部Flash的前1 KB范圍內預先存放一小段程序,待片上Bootloader工具把此段代碼搬移入內部并開始執行后,由這段代碼實現將Flash中剩余的用戶應用程序搬移入內部RAM中。此段代碼可以被稱作一個簡單的二級Bootloader。
圖2所示為使用二級Bootloader時的CPU運行流程。

使用二級Bootloader需要考慮以下幾個事項:
◇需要燒寫的COFF(公共目標文件格式)段的選擇;
◇編寫二級Bootloader;
◇將選擇的COFF段燒入Flash。
一個COFF段就是占據一段連續存儲空間的程序或數據塊。COFF段分為3種類型:代碼段、初始化數據段和未初始化數據段。
對于EMIF加載方式,需要加載的鏡像由代碼段(如.vectors和.text等)和初始化數據段(如.cinit,.const,.switch,.data等)構成。另外,可以單獨定義一個.boot-load段存放二級Bootloader。此段也需要寫入Flash。
所有未初始化的數據段(如.bss等)都不需要燒入到Flash中。
2 二級Bootloader的編寫
由于執行二級Bootloader時C的運行環境還未建立起來,所以必須用匯編語言編寫。二級Bootloader可參照其他類似文獻及TI相關文檔。此處不再贅述。
CCS中用戶工程編譯鏈接后產生的.map文件包含了存儲器的詳細分配信息。一個典型的map文件中包含的存儲器分配信息如表2所列。

與cmd文件不同,map文件不僅包含了各段存儲在哪一段內存空間的信息,從map文件中還可以具體知道每個內存區間中有多少被實際使用(燒寫Flash時會用到這個參數)。內存區間中未被使用部分是不需要寫入Flash內容的,實際被使用的部分才是真正需要寫人到Flash中的內容。
3 Flash的燒寫
把代碼等寫入Flash的辦法大體上可分為以下幾種:
① 使用通用燒寫器寫入。
② 使用CCS中自帶的FlashBurn工具。
③ 用戶自己編寫燒寫Flash的程序,由DSP將內存映像寫入Flash。
其中,使用通用燒寫器燒寫需要將內存映像轉換為二進制或十六進制格式的文件,而且要求Flash器件是可插拔封裝的。這將導致器件的體積較大,給用戶的設計帶來不便。
]]>