首先確定手機已死,電池電量滿(有穩壓電源者更好) 刷機所需要的必備工具
需要用到:超強免費修復軟件MSTools,BL字庫和PDS修復檔案(下面有下載)
(二) 創建手機與電腦的連接
此過程對于玩家來說比較困難,但對于廣大同行來說-小菜一碟。
1.準備工作。必須要用到的工具:大小合適的良導體鑷子,拿掉SIM卡的手機,夠長的數據線,電量充足的電池。
2.正式操作。首先,不管死機活機假死機,統統電池拿出手機。。。。然后通過數據線連接電腦,連好后,我們來溫習下測試點TEST POINT的正確位置,這時你的手機沒有SIM卡,應該很容易找到它,對,就是那比芝麻還小的小樣兒
確認好測試點的位置后,左手拿手機,機面朝下,機屁股對著你,用左手拇指按住電池的屁股,電池觸點朝下壓在離手機上電池觸點的附近,電池與手機成90度,右手用鑷子的一個頭摁住測試點。
如圖:
屆時,所有前奏都已完成,現在你只需要將電池向后一歪,與手機成40度左右且順勢將電池觸點端向前推與手機的觸點接觸,保持這個姿勢15秒左右。如果失敗了,活機和假死機玩家會發現手機屏幕或者鍵盤燈亮了(個別機油可能鍵盤燈長亮但是不開機,也是失敗了),此時你可以選擇直接拿下電池重來,也可以為手機著想,拿下鑷子,電池緩緩平放入槽,讓手機完全開機,然后正常關閉,重新來;如果成功了,15秒左右之后電腦會提示找到新硬件(不是第一次進入檢測模式即以前安裝過檢測模式驅動的玩家就直接在設備管理器里看到連接成功,并且這里建議大家都事先打開設備管理器,以便觀察連接狀況)本人以下抓圖均已刻意抓出設備管理器內的motorola的驅動圖片。并且屏幕和鍵盤都不亮,這時可以拿走用來接地的鑷子,右手協助將電池緩緩平放入電池槽(期間千萬不要斷開了觸點的連接,否則又要重新來了。。。。),隨后安裝驅動,大功告成!!!
有穩壓電源者自可加上電源線,點好測試點,然后開關電源。使其找到新硬件。
3.如何確認已正確連接
這一步很簡單,打開MFF,如果是正確的連接,在下面的刷機設備名稱會看到S Blank Rainbow POG。如果不是正確的連接,就會顯示其他東西而非S Blank Rainbow POG,或者什么都不顯示。。。。好,確認是S Blank Rainbow POG后,看這里,
切記切記!!!一定要先關閉MFF,再運行MSTool,忘掉這個的造成機器損壞概不負責!!!
好,到此即完成了手機與電腦的連接
(三)利用MSTool修復BL和PDS
這一步是真正使手機起死回生的,解壓下載好的MSTool包后可以看到兩個文件load_it!.exe和mstool_8r.exe,運行load_it!.exe,會出現一個提示窗口,點擊確定后一會就會出現如下軟件界面。
現在刷新由“BL和PDS檔案”解壓出來的兩個文件E770_0671_BOOTCORE.bkp和E770_PDS.bkp,刷新方法如下圖
先寫BL再寫PDS
這里要注意每刷新好一個之后右邊會顯示英文刷新完成,再等一下,手機可能會斷開連接,這時要重復第二步來重新連接。
刷好后按*#開機鍵會看到critical error 02,但是還是不能正確連接電腦,不要緊,別急,做完最后一步你的手機就活了。
(四) unlock修復。
由于刷新了新的BL之后網絡鎖沒有解開,所以報錯,現在再用第二步的方法連接手機與電腦,用MSTool對手機進行解鎖修復,如下圖,完成后右邊顯示complete完成,手機自動斷開
至此修復工作就完成了,*#開機進DOS應該可以看到正常的DOS了,部分機油CG沒有損壞的話可能可以正常開機了
機器完全不能有任何開機跡象,只能接地連接,都修復好了。請在修復前仔細閱讀本文,特別是個別用顏色提醒的地方,否則可能修復失敗!!!


2、未經授權在國內發布的GPS軟件,Google Maps就是屬于此類
海外版本GPS軟件(暫時叫海蟹GPS軟件),并沒有國內的誤差糾正算法,所以,在該軟件上看國內出版的地圖時,就出現“你知道你在哪個地理坐標上,但是不知道你在哪個地點”。
我的測試環境及結果
經過我的測試:
Google Maps 3.1.1:
ROM 2.2 定位準確,前提是 MCC代碼必須設為 460。
Google Maps 3.1.2:
ROM 2.2/2.55/2.57 均出現偏移,無論MCC代碼必須設為 460與否。
那么ROM2.2+Google Maps 3.1.1版本為什么定位準確?
經過我的分析,初步判斷 Google Maps 處理中國移動/聯通手機的請求(MCC國家編碼 460)時,在服務器端或者本地端進行糾偏。
ROM2.57+Google Maps 3.1.2 定位偏差的糾正問題的分析
ROM 和 Google Maps 必須匹配某種組合,才能讓Google Maps 正確處理 MCC為 460 的定位請求。這種組合可能涉及到:
A) ROM 對坐標的處理算法模塊;
B) Google Maps 處理坐標的算法。
如果是 A) 的情形,通過 Patch ROM 還是可以糾偏。如果是 B),則只有依賴 Google Maps 的版本修改了。
也就是說,定位不準是由于ROM或者Google Maps程序引起的,與Google Maps服務器無關。
以上純屬簡單分析后的猜測,有更熟悉的朋友請指正。
]]>
版本為:+ ^% {3 K) P7 V
82AV4黑金版-V3.6.C020.9.19# H) F& O- M( B2 D
82AV4水果味-V3.6.C127.2.23( s5 |: } j$ y4 g% G8 K1 x& b
" }( a" m; J0 S" Q" e. s$ x+ l2 O
由于WinCE是整個系統的基礎,CE的內存使用量及穩定性直接決定了包括UI在內的可用性,因此特別針對它截了圖。
……沒法上傳圖片附件,算我多事,一個論壇,連起碼的發帖權限都這么限制,怎么叫人來混啊?找批人來灌水混分賺等級?又何必來這個沒人氣的地方?這個寫完走人了!! V9 Y4 E5 L9 J1 S( \1 ?# f
82AV4黑金版-V3.6.C020.9.19 占用內存19.2M左右3 K: w+ @* ]' t) _- b$ ^
82AV4水果味-V3.6.C127.2.23 占用內存20.6M左右% J: y; }5 v) u, T; m1 l t; }8 [* H
& v. b/ h" b* H9 @8 g8 E% L1 c
82AV4水果味-V3.6.C127.2.23 WinCE明顯有問題,除了多了個輸入法之外,系統里垃圾文件超多,建議發布這種有關貴公司形象的內核時,仔細點。想必裝電腦的時候肯定選“純凈版GHOST XP ”,自己選喜歡的軟件裝,也不會裝個控制面板都沒的系統吧?
如果說CE的軟件有些是要用在YF UI里的,OK,那就出2個版本的CE好了,UI一樣,CE分干凈和豐富的,不復雜吧?現在網上CE的軟件一找就能找到幾百M,比你們提供的豐富多了!http://www.rayfile.com/zh-cn/files/4f996cf8-ee51-11de-973c-0014221b798a/3d2001fd/
) g, v7 N- }+ ^) p
相比之下,82AV4黑金版-V3.6.C020.9.19 WinCE感覺好太多……
9 H/ c4 @, a8 U. m9 k# C
此二個版本雖然都不能順利使用 Garmin V5.00.30wp-ASN (map 7.6NT),但起碼 82AV4黑金版-V3.6.C020.9.19 在等待十分鐘后越來越快了,比起 82AV4水果味-V3.6.C127 等待20分鐘沒反應來說好得多。]]>
微軟表示,IE9將頻繁升級,開發團隊會對其功能和穩定性進行不斷完善。為了獲得有效的用戶反饋,IE項目主管Justin Saint Clair將負責挑選測試人員加入“IE技術反饋精英團隊”,今后這些測試人員將在第一時間獲得最新的IE9版本。
測試人員的挑選標準主要基于IE8 Beta測試階段參與測試的開發人員回饋情況統計,那些最活躍的反饋了最多Bug問題的測試人員將優先被選拔進入IE9技術反饋團隊。目前,已經有很多用戶收到了IE9團隊發送的測試邀請。

]]>
dw期待已久的PPC版3D導航軟體終於出現了!
用過國內好幾套的導航軟體,大多都還是停留在"
 PC"的程式操作觀念跟畫面,感覺上是電子地圖附加的GPS功能,也有廠商推出類車機的GPS導航軟體,但是在操作介面上跟程式的成熟度來講,離實際需求還有一大段距離。研勤近年來在導航軟體上的努力眾所皆知,V5版也不斷的發表更新,就消費者的觀點看來,該公司算是對消費者最有誠意的廠商。剛聽到Papago V7!的消息時,有點訝異,V5.8才剛剛更新,有了V3升級V5的經驗,我想該不會是又拿一個類似的產品換一個名字來A錢吧?等到我裝好了V7版打開來瞧瞧,才知道......哇...天啊....這才是我要的3D導航!
PC"的程式操作觀念跟畫面,感覺上是電子地圖附加的GPS功能,也有廠商推出類車機的GPS導航軟體,但是在操作介面上跟程式的成熟度來講,離實際需求還有一大段距離。研勤近年來在導航軟體上的努力眾所皆知,V5版也不斷的發表更新,就消費者的觀點看來,該公司算是對消費者最有誠意的廠商。剛聽到Papago V7!的消息時,有點訝異,V5.8才剛剛更新,有了V3升級V5的經驗,我想該不會是又拿一個類似的產品換一個名字來A錢吧?等到我裝好了V7版打開來瞧瞧,才知道......哇...天啊....這才是我要的3D導航!
把Papago!V7裝好後,直接在Today的畫面上會出現一個捷徑,Papago的工程師真是貼心,這有什麼好處呢?一上車就可以直接點選,不用到開始功能表或是程式集裡去找,對於駕駛者來說大圖示很方便操作。很棒的設計,一開始就有一個好印象!

直接點選就可以開啟PapaGO!V7,第一次開啟時會要求輸入註冊碼,先不管他按試用...咦跟以往的版本差不多嘛,只是把放大縮小的功能鍵移到畫面上罷了...不過顏色比較好看了



dw還是按照慣例,先看看設定頁面
這是一些基本的設定,嘿!多了一個參考線,嗯...有3D的架式了喔。使用者還可以自行選擇縮放器的位置。



這是關於導航的設定,注意看喔那個衛星定位修正範圍就是"鎖路"的功能,使用者可以自行調整。

語音選項頁面,跟以前差不多,又是Linda...建議研勤要不要換一下,感覺上Linda的聲音有些冰冷,要不要換一個熱情火辣的.... 呵...我是說溫柔可愛的啦!

景點的選項,可以針對自己喜好的景點類型標示在螢幕上,這樣就不會一大堆圖示擠在一起不知道要看哪一個了。


以往使用到導航軟體的經驗,在接上GPS後,PDA就會變的遲頓了,尤其再搜尋時,感覺上被牽制了,搜尋到一個地標,一按定位只閃了一下,又回到現在定位的地方,除非先將GPS斷線。Papago這次是把GPS的導航功能跟電子地圖分開,導航時亦不影響電子地圖的查詢,就是說可以一面導航一面另外查詢新的景點,兩個程式卻又緊密的結合,說起來好像很複雜,但是用起來實在是好用。
GPS是另一個程式叫GPS Control,使用者不需要另外啟動,打開V7自動會被啟動,自動搜尋GPS,並開啟。GPS可以在這裡設定。畫面看起來好眼熟喔?這是還沒有接上GPS的狀況。它還可以記錄GPS Track log喔,不單只是觀察狀態的功能而已了。既然功能都增加了,如果能再加上Coldstart的功能就更完美了。




按下下方的NAVI鍵,就跳到導航的畫面。點一下螢幕的中央,就出現導航的操作圖示,大大的圖示方便行車終點選設定。不錯吧!不輸給車機喔,大圖示方便在開車的時候快速設定,不用停在路邊等半天,在這裡可以隨時切換回地圖瀏覽模式、3D/2D導航畫面的切換、GPS的設定、目的地的設定等等...值得一提的是,V7不但可以使用快速的方式設定目的地,也可以依照以前的方式設定目的地。新手快速上線,老鳥依然熟練!



注意看螢幕上方的圖示,就是顯示GPS狀態收訊強度。最右方的插頭或是電池圖示,表示現在是用電池或是插上車充。

我們來試試看新的快速設定目的地的功能,按下目的地設定就會出現下面這樣的畫面:

很方便的,例如回家,設好了"我家"的地標後,直接按下去就會自動規劃回家的路徑。
用地圖瀏覽模式搜尋、設定"我家"的地址後,在地圖上點選直接出現對話框,選擇"設成我的家",就會出現一個家的圖示,只要設定一次,以後就直接點選就可以了。


也可以從我的地標裡看出剛剛新增的"我家"

自動規劃好的路徑

地圖檔還是維持在54Mb左右,比較適合放在記憶卡裡面,dw建議直接買256Mb以上的記憶卡比較不會後悔。


來看看3D導航的畫面吧!酷吧!看到這個畫面真是震撼啊,有一種莫名的感動,這才是真正的3D導航!畫面的質感真是不輸國外的導航軟體,連代表車子的三角箭頭的陰影都做出來了,搭配上參考線頓時立體感倍增。畫面的標示非常清楚,尤其是路名的標示真是棒透了,不會因為3D而擠在一起,清楚又明瞭,讓我對3D導航的畫面大開眼界而讚嘆不已,路口也不用換畫面了,直接就放大給你看,路線用黃色大箭頭標明,這樣夠清楚了吧!



不習慣3D?沒關係,也可以選擇2D導航的模式,不賴吧?這種路徑的標示絕對不會走錯路。而且有大改進喔,注意車子的圖示移到螢幕比較下面的地方了,V5版用戶的聲音研勤有聽到喔!



來看看上快速道路的指標跟高速公路的資訊吧!
先規劃一個龍潭交流道。雖然距離遠一點,但是在我的Arm 206CPU跑起來決不遜色喔!

這是開上市民大道快速道路及接上環快的畫面,那個參考線就大地座標,有透視圖的觀念喔。



經過兩座橋樑的上方

上了高速公路,看到這樣的畫面真是感動啊!最近的設施都一目了然。尤其半透明式的設計不會因為要顯示資訊而犧牲了導航畫面,高速公路資訊也不會因為只佔頁面一半而必須縮小,開上高速公路資訊自動顯現,不用換頁,不用點選。



螢幕上設施的數量可以由"高速公路資訊顯示物件"裡調整。
不過...毒舌的dw還是要多嘴一句,怎麼沒有現在里程呢?這個很重要耶,怎麼說呢?上了高速公路後,大多數的駕駛會聽警廣了解路況,聽到南下/北上XX公里有事故,回堵XX公里....哇...我現在到底在哪啊?如果導航軟體能提供這個資訊,相信對很多使用者是一大幫助。
夜間模式...在夜晚開車可以避免PDA螢幕太亮,讓駕駛感覺刺眼,暗色系的畫面可以有效的減少對駕駛的影響。



Papago! V7實際規劃的路徑也有進步,比起以往的版本合理性提高了。重新規劃時,走回頭路的機會少了些,不過還是會有原地迴轉的狀況。
不會要你原地迴轉,會指引你到下一個路口或是回轉道迴轉。

遇到圓環的規劃也會放大,這樣的指引夠清楚了吧!而且他的路口放大功能是隨著行車距離靠近而逐漸放大,不是忽然換頁,這樣有個好處,不會因為走到路口忽然換頁,產生換頁的延遲,讓駕駛混亂而走錯路。複雜的路口也有明確的路名跟箭頭指引,很清楚喔!


咦...這個地方可以這樣轉嗎?

會不會走回頭路?故意走錯路試試看就知道!



怎麼樣?走錯後重新規劃的路徑是由前方另闢新路喔。當然有些狀況下是會要你迴轉的,例如山區的省道,走錯了要繞道,可能會要多走好幾十公里,這種狀況除了回頭,別無他法。
另一個貼心的設計,紀錄所有的操作,這樣又多了一個快速搜尋到目的地的地方。

再來說一個要打屁股的大錯誤...從V5版到現在都沒改正過
先用搜尋功能,找創校51週年的及人國小,注意喔51週年喔!不是51個月喔,點選定位,不錯很快的定位到了...也顯示是"及人國小"


再點一次...嘿嘿嘿,變成"立人國小"了,這種小瑕疵在更新地圖時記得要修正喔!

3D導航時,圖示太多顯得畫面有些混亂,而且地標圖示蓋住了路徑跟路名,這一點要改進,圖示在跟路名或是路徑重疊時,用半透明的方式表現,或是可以從景點裡設定只顯示某些地標景點。

還有一個需要改進的,V7的地標跟V5不相容!天阿.....換軟體不能將舊的資料複製過來,很痛苦耶...研勤應該要同步發表一個轉換地標的小程式,方便舊用戶。也希望在正式版的時候能把紀錄軌跡功能補上。
後記
dw看到這樣的導航軟體,真是難掩內心的悸動,這真是PPC版導航軟體的一大進步。強大的地圖查詢功能,精美的3D畫面,人性化的操作介面,更進一步的是貼心的駕駛者快速設定方式,完全以駕駛者的使用便利性為考量,不再是強調準確、鎖路、不會飄...這些工程師的觀點,導航軟體就是要這樣做嘛!試想要規劃一個地標路徑,卻要層層搜尋...把車子停道路邊,車上好幾雙眼睛在等著看你的表演,偏偏又不知道從哪一層找想要的地標,這時真是尷尬喔...;另外V7還有一個很棒的設計,不再是設多個"經過點"了,而是多個"目的地",這樣對重新規劃路徑的時間有很大的幫助。也會路徑規劃的合理性增強不少。設多個目的地,讓導航軟體幫你找路吧!而不是設好頭尾,還要自己找經過點...如果我自己都會設經過點,我已經知道要怎麼"經過"才順,哪還要導航嗎?
dw拿到的V7應該算是全功能測試版,但是在dw的Mio 528的老機器上運行,還算不錯喔,除了手動螢幕放大縮小稍有延遲,其他路上導航也還跟的上車子實際的位置,不過感覺上3D導航會慢一點,我相信在400MHz的機種上運行應該會更順暢。2D導航流暢度就不錯,我這種老機器應該勉強能用。除了導航畫面,其他操作介面就完全沒有阻礙,不會出現畫面一片空白的窘境。另外值得一提的是,dw測了好幾天,完全沒有當機!
Papago!V7的設計出發點完全是站在使用者便利以及人性化的介面,雖然導航只是輔助,但就是思考到駕駛者、使用者的心態,把規劃圖示放大、搜尋簡單便利、簡化路徑規劃方式、使用者可以自行調整的放大縮小鍵,可以自己選擇的高速公路物件、清楚明確的3D路逕跟路名顯示,這樣才是完全貼近消費者的需求,而不是任由工程師在哪裡堅持自己的理念....
你還在考慮要買那一種導航軟體嗎?試試Papago! V7吧,絕對不會讓你失望!
感謝dw的精彩評測。
]]>
且慢!小編希望本友們務必記住隨身攜帶測試軟件。“大蝦”也許可以挑機型、講價格、查發票、辨樣機,但“大蝦”也需要借助軟件才能探明筆記本硬件的真實狀況。如今連二手本都可以弄成全新的模樣,返修本、樣機整個容更不是難事。與其依靠經驗,不如依靠客觀的測試軟件。當然,如果您準備購買二手本,測試軟件更是您唯一的保障。

二手筆記本的配置更需仔細檢查
一提到測試軟件,許多朋友就會想到我們評測時常用的3DMark系列。不過3Dmark系列體積巨大、所能測試的項目有限、安裝和運行都較為耗時,而且一般筆記本顯卡需要優化之后才能跑出讓您滿意的分數。與之相反,一些體積較小的測試軟件卻可以直觀簡潔的幫助您檢驗筆記本的性能。

體積小巧的測試軟件可以隨意拷進U盤、記憶卡里
下面,筆者就為大家推薦8款體積較小的筆記本測試軟件,我們將用它們實際測試一款符合迅馳 2平臺要求的筆記本。
這些測試軟件加在一起不到17MB,任何U盤、記憶卡都能存儲下。有興趣的朋友不妨及時下載。
● 功能全面又彪悍 Everest
Everest是一款功能全面的測試軟件。雖然它體積不大,卻能識別出絕大多數品牌推出的各種電腦配件。它可以用來測試臺式機、筆記本乃至服務器的硬件、軟件系統信息。此外,目前我們已經可以便利的使用其最強勁的“終極版”。其版本號為EVEREST Ultimate Edition 4.50.1370.0。
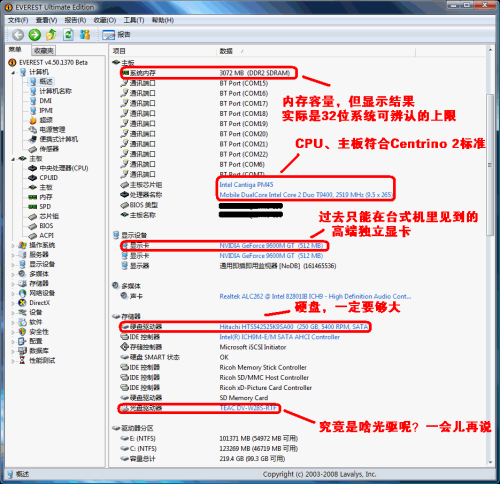
Everest軟件摘要頁面(點擊可放大)
使用Everest軟件,我們首先可以查看“摘要”頁面。這里已經列舉出了這款迅馳 2筆記本的所有主要屬性。點擊其中的各個鏈接,您可以查看自己更關心的信息。
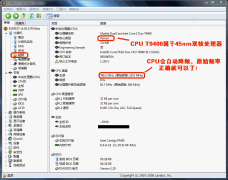

Everest軟件“超頻”和“便攜式計算機”頁面(點擊可放大)
“超頻”選項可以看到處理器的“頻率”和“原始頻率”。由于目前筆記本普遍采用了自動降頻的技術,所以“頻率”往往會比“原始頻率”低。“原始頻率”才是真實的CPU頻率,核對它就可以了。而“便攜式計算機”選項可以告訴您,這臺筆記本到底符合哪一代“迅馳”標準。當然,它符合迅馳 2“Montevina”標準。
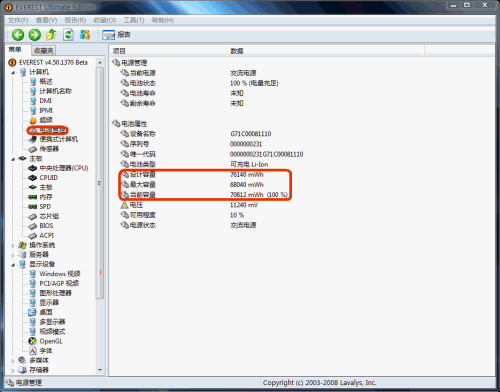
Everest軟件“電源管理”頁面(點擊可放大)
“電源管理”選項則可看見目前系統的電池狀態。如果電池的“最大容量”和“設計容量”存在明顯差距,則這臺筆記本的電池已被使用過,可能是樣機或返修機。
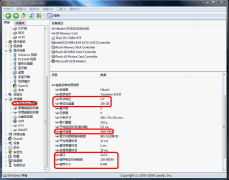
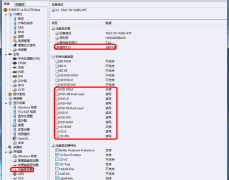
Everest軟件“Windows存儲”頁面(點擊可放大)
在“Windows存儲”選項中我們可以檢查硬盤和光驅的容量。
使用這款軟件可以快速核對筆記本配置,如果您只攜帶一個軟件購機,那么請務必帶上它。
Everest軟件下載地址 >>點擊這里
● 買電腦首先看CPU CPU-Z
在電腦的各個部件中,CPU無疑是最受人關注的。CPU甚至可以決定一款筆記本的檔次,我們會自然而然覺得“同系列兩款筆記本中,CPU好的筆記本就較好”。以下我們介紹一下最常用的CPU測試軟件——CPU-Z。
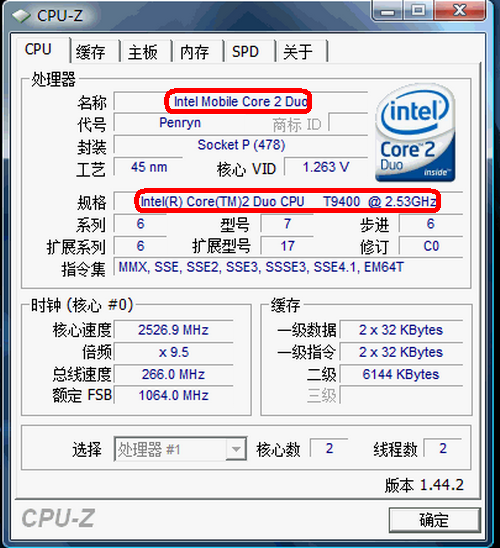
CPU-Z識別T9400
CPU-Z可以提供非常全面的處理器信息報告,包括:處理器的名稱、廠商、時鐘頻率、核心電壓、超頻檢測、處理器所支持的多媒體指令集。另外,它還可以顯示出處理器L1和L2的詳細資料(大小、速度、技術)。我們可以通過處理器的倍頻和外頻,判斷處理器是否被Remark。
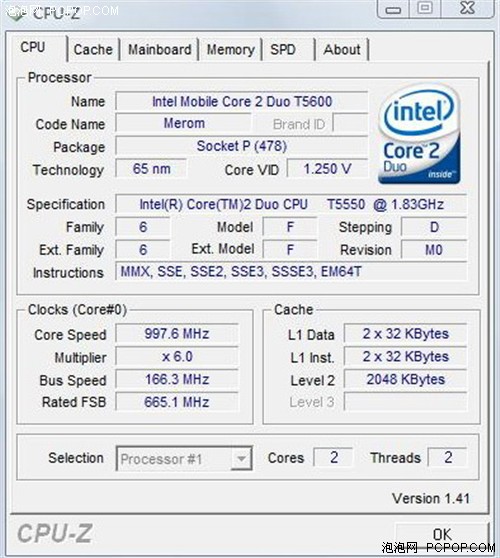
CPU-Z識別T5550
我們往往會遇到CPU-Z將一顆CPU識別成兩種型號的情況。比如說T5550剛上市時,CPU-Z會將它的名稱識別為T5600,而在“規格”一項中則顯示T5550。這是因為,“名稱”是CPU-Z按照參數推測的,而“規格”則是CPU-Z從固件讀取的數據。所以,我們以“規格”一項為準。
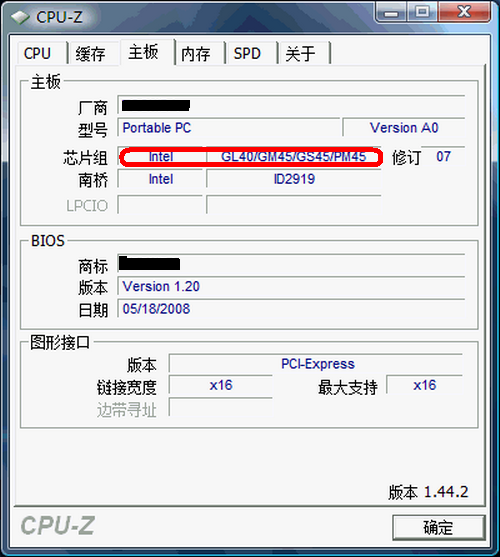
CPU-Z的主板信息
使用CPU-Z,我們往往只能得到粗略的主板信息。
CPU-Z可以分別檢測筆記本的多個內存插槽并顯示其信息。如果還有一個空插槽的話,我們就可以隨時再添加一條內存進行升級;如果兩個插槽都被插滿了,就要拔出一條原有的內存,再添加一條更大的內存進行升級。
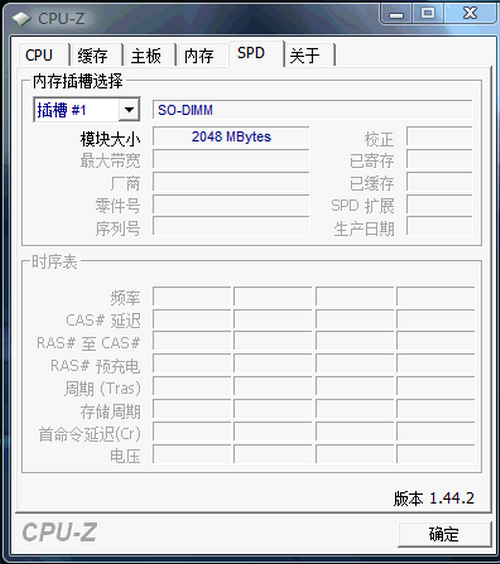
CPU-Z顯示 迅馳 2樣機的SPD信息
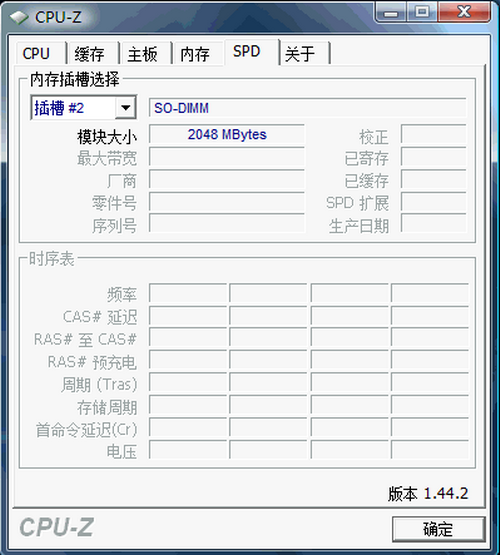
CPU-Z顯示 迅馳 2樣機的SPD信息
4GB內存已超出32位系統所能利用的內存上限,或許這是CPU-Z無法獲得關于內存的詳細信息的原因吧。正常的情況應該如下圖所示:
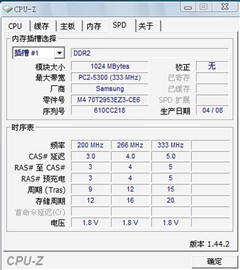
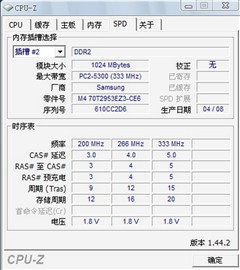
CPU-Z的SPD信息
CPU-Z軟件下載地址 >>點擊這里
● 內存條也會有壞點 MemTest
MemTest是一款袖珍內存軟件,其文件大小僅為24KB。它的操作異常簡單,達到了“傻瓜”的地步。它的測試原理也很簡單,就是將內存的各個存儲單元都使用一遍。
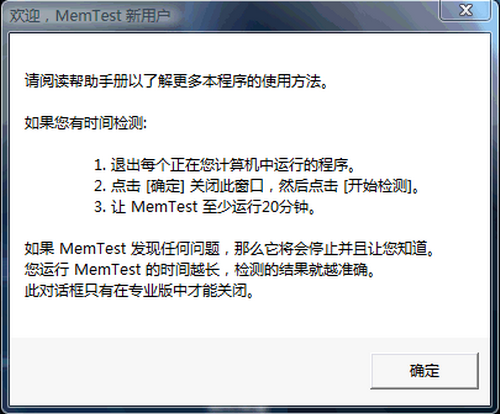
MemTest啟動時自動彈出用戶說明
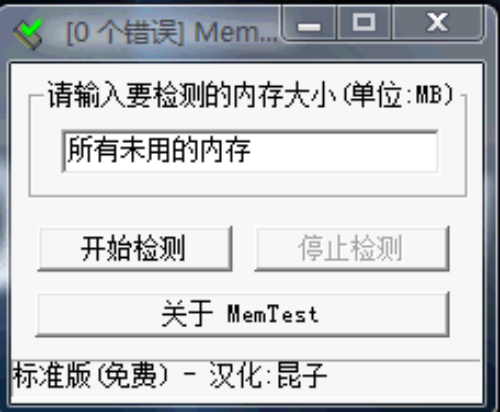
選擇檢測范圍界面
按照軟件提示進行操作,然后輸入要檢測的內存大小(默認為零)。需要注意的是,雙核筆記本需要運行多個MemTest軟件進行檢測。
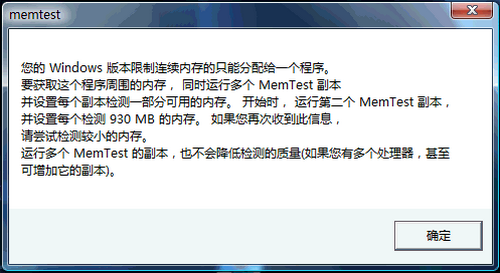
軟件提示:多核系統中需要運行多個MemTest的線程
使用這款軟件,我們可以及時診斷出問題內存并要求調換。小編就幸運的在它的幫助下發現過問題內存。
MemTest軟件下載地址 >>點擊這里
● 看看硬盤好用不 HD Tune
HD Tune是權威的硬盤測試軟件。
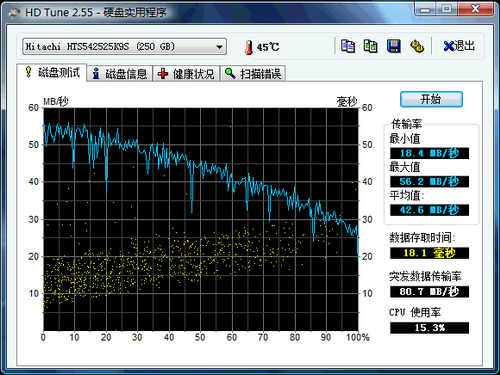
HD Tune
首先點擊HD Tune第一個選項卡里的“開始”按鈕就可啟動性能測試。藍色的性能曲線越平滑則表明整體性能越好。
]]>
受限于處理器和顯卡性能,它們之前的Beta版Light Mark只能以較低分辨率和較低的幀數運行。現在這款2007年最新拿出的Light Mark可以渲染22萬個多邊形,并且可以在高分辨率下運行,獲得比較滿意的速度。
Light Mark正式版大小28.9MB,要求顯卡Radeon 9550和GeForce 6600以上,內存至少512MB。
官方下載地址:http://dee.cz/lightsmark/Lightsmark2007.1.0.msi
驅動之家下載地址:http://tools.mydrivers.com/soft/301.htm
]]>
Everest ultimate(原名AIDA32)
Everest ultimate是一個測試軟硬件系統信息的工具,它可以詳細的顯示出PC每一個方面的信息。支持上千種(3400+)主板,支持上百種(360+)顯卡,支持對并口/串口/USB這些PNP設備的檢測,支持對各式各樣的處理器的偵測。目前Everest Home已經能支持包括中文在內的30種語言,讓你輕松使用。而且經過幾次大的更新,現在的Everest已經具備了一定的硬件測試能力,讓您對自己電腦的性能有個只管的認識。最新版本更新如下:
1.修正了Intel i940/945/955/975/E7230芯片組信息顯示方面的錯誤。
2.增加對Ageia無理卡的支持。
3.修正了Geforce 6800XT顯卡信息顯示方面的錯誤。
CPU-Z
CPU-Z是一款家喻戶曉的CPU檢測軟件,除了使用Intel或AMD自己的檢測軟件之外,我們平時使用最多的此類軟件就數它了。它支持的CPU種類相當全面,軟件的啟動速度及檢測速度都很快。另外,它還能檢測主板和內存的相關信息,其中就有我們常用的內存雙通道和三通道檢測功能。當然,對于CPU的鑒別我們還是最好使用原廠軟件。
是一款家喻戶曉的CPU檢測軟件,除了使用Intel或AMD自己的檢測軟件之外,我們平時使用最多的此類軟件就數它了。它支持的CPU種類相當全面,軟件的啟動速度及檢測速度都很快。另外,它還能檢測主板和內存的相關信息,其中就有我們常用的內存雙通道和三通道檢測功能。當然,對于CPU的鑒別我們還是最好使用原廠軟件。
CrystalCPUID
CrystalCPUID是一款處理器檢測工具,在功能方面和CPU-Z、WCPUID基本相同,它并不遜色于CPU-Z和WCPUID,它所支持的CPU類型非常全面。
此外,它還可以調節英特爾 SpeedStep 控制、AMD K6/K7/K8/LX 處理器及VIA CyrixIII/C3 處理器倍頻。
GPU-Z
GPU-Z是硬件網站TechPowerUp.com提供給我們的一款GPU識別工具,綠色免安裝,界面直觀,運行后即可顯示GPU核心,以及運行頻率、帶寬等,如同CPU-Z一樣,這也是款必備工具。
更新日志:v0.3.1
1、修正在無NVAPI系統下的崩潰問題(Win 2000或舊版NV驅動);
2、優化RV770 BIOS讀取代碼,提升程序驅動速度;
3、改進針對新款ATI顯卡的電壓讀取代碼;
4、支持NV 180.xx及以上驅動的風扇轉速監控功能;
5、增加NVIDIA GT200核心的電壓監控功能;
6、修改RV770傳感器讀取方式,修正與其他軟件的共存以及風扇控制問題;
7、修改GeForce 9800 GTX+制程顯示為55nm;
8、增加支持Intel Q43/Q45;
9、增加支持NVIDIA Quadro FX 4700 X2, GTX 295, GTX 285;
10、初步支持NVIDIA GT212, GT214, GT215, GT216, GT218。
Intel Chipset Identification Utility
英特爾(R) 處理器標識實用程序由英特爾公司提供,使客戶得以識別英特爾微處理器的品牌、特性、包裝、設計頻率和實際操作頻率。 客戶還可使用本實用程序來辨別英特爾處理器是否超出英特爾額定的頻率在操作。
Intel Chipset Identification Utility工具是一款功能強大的Intel芯片組識別工具,而且它還是一款綠色軟件,無需安裝,直接雙擊運行即可。通過它可以讓您快速、直觀的得知當前主板所使用的Intel芯片的具體型號,其中包括芯片組(Chipset)名稱,北橋芯片(內存控制芯片)(Memory Controller)名稱,南橋芯片(輸入\輸出控制芯片)(I/O Controller)名稱,集成的顯示芯片(Intergrated Graphics)名稱。3.22版具體支持檢測芯片組型號如下:Intel 910GL、915G、915GV、915P、925X、910GML、915GM、915GML、915GMS、915PM、945G、945P、945GM、945PM、945PL、955X、975X、Mobile Intel GM965/PM965
本實用程序的主要功能通過屏幕頂端的菜單選項實現。
本實用程序的頻率測試部分提供有關被選處理器操作狀態的信息。
本實用程序的 CPU 技術部分顯示被選 處理器中存在的英特爾處理器技術和功能。
本實用程序的 CPUID 數據部分識別系統中的英特爾處理器。
保存功能將處理器信息保存到文本文件。
Web 更新功能能夠更新到最新版本的英特爾處理器標識實用程序。
英特爾處理器標識實用程序不是設計用來識別非英特爾公司制造的微處理器。
HDTune
HDTune是一款極佳的硬盤檢測工具,它支持了以下主要功能: 1.基準測試:檢測硬盤的傳輸性能 2.信息:顯示硬盤的詳細信息 3.健康:通過使用SMART來檢查硬盤的健康狀態 4.錯誤掃描:掃描硬盤表面的錯誤 5.溫度顯示 另外,HDTune還同樣可以用于下列的其他存儲設備(例如:內存卡、US B存儲卡、iPods、等)。
DisplayX (LCD檢測)液晶顯示器檢測軟件。
特點
*查找LCD壞點
*檢查LCD的響應時間
*屏幕基本測試
1.2版更新日志:
增加了“銳利”測試,主要用于測試大屏幕電視的顯示效果
增加了繁體中文語言支持
改進了對比度(高)時的圖案
改進了圖片測試提示信息,當未指定測試目錄的時候,加入了提示
修改了啟動畫面的圖案,舊的看煩了吧
關于銳利的測試,就是在畫面的四角和中央顯示一些1像素寬的線條,線條間隔也是1像素(每組有9條綠色的線條)
如果大屏幕電視達不到標稱的分辨率,而只是能接受該分辨率的信號,然后將實際圖像縮小顯示,則這些線條將發生失真,通過此測試可以推斷大屏幕電視是否達標。
NONIA顯示器測試
NTEST2.NONIA.TEST主要用于測試液晶顯示器壞點,以及CRT顯示器對焦、色彩等
MemTest內存測試
MemTest是少見的內存檢測工具,它不但可以徹底的檢測出內存的穩定度,還可同時測試記憶的儲存與檢索資料的能力,讓你可以確實掌控到目前你機器上正在使用的內存到底可不可信賴。
Super PI
Super PI是利用CPU的浮點運算能力來計算出π(圓周率),所以目前普遍被超頻玩家用做測試系統穩定性和測試CPU計算完后特定位數圓周率所需的時間。
Fritz Chess Benchmark
Fritz Chess Benchmark是一款國際象棋測試軟件,但它并不是獨立存在的,而是《Fritz9》這款獲得國際認可的國際象棋程序中的一個測試性能部分。它可以讓我們的X86計算機也能完成IBM“深藍”當初所做的事情,那就是計算國際象棋的步法預測和計算,雖然現在我們的個人電腦依然無法與10年前IBM的“深藍”相提并論,并且無論是在處理器架構方面、節點方面還是AIX操作系統方面都有很大的差距,但是Fritz Chess Benchmark依然是目前在個人計算機方面最好的步法計算和預測軟件,同時也可以讓我們對等的看到目前我們所使用的個人計算機到底達到了一個什么樣子的水平。同時該軟件還給出了一個基準參數,就是在P3 1.0G處理器下,其可以每秒運算48萬步。
BatteryMon
BatteryMon是一款監視PC電池使用狀況的軟件,電池的各項參數都是由直觀的圖表即時表示的。支持便攜式電腦和UPS。
]]>
內存在系統中扮演暫時存儲CPU運算所需數據的角色,是溝通與緩沖CPU和硬盤數據的橋梁,我們大家都知道內存的速度會影響整個系統的速度,但是到底影響多大,和什么有影響,都只有大概的概念,此次組織測試的目的是驗證內存的頻率和時序對系統速度的影響程度。
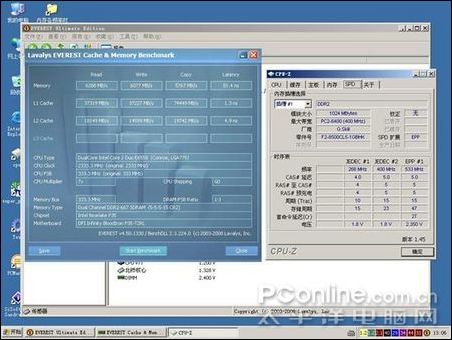
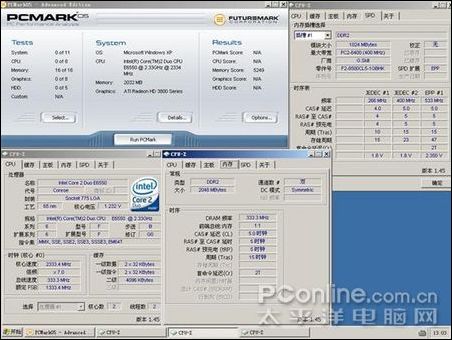
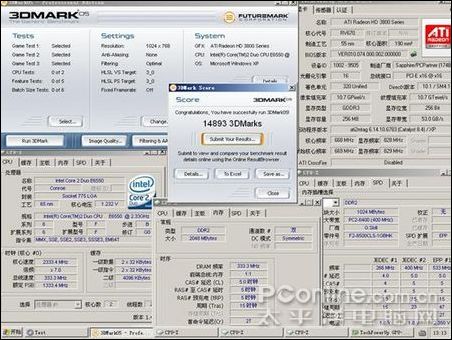
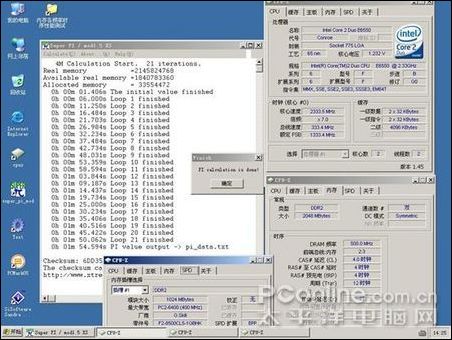
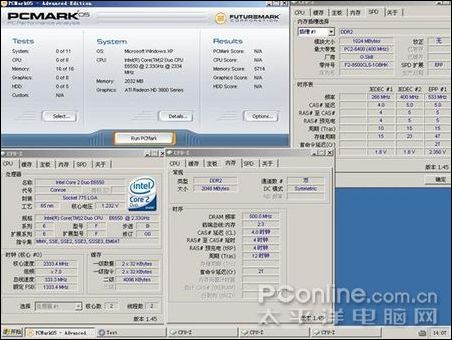
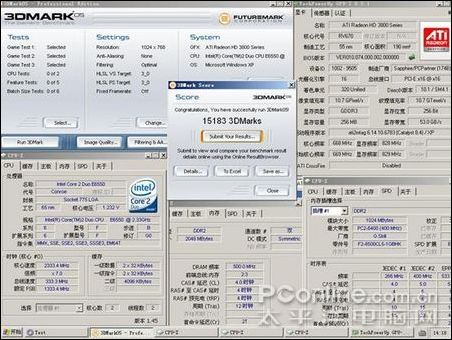
因為當前DDR2內存是主流,所以此次參與測試的是芝奇1G/1066雙通道對條,主板為DFI Infinity BloodIron P35-T2RL,顯卡是藍寶石HD3850/256M,CPU 采用E6550。軟件測試方法為在CPU主頻默認,外頻不動的情況下改變內存的異步模式與調整內存時序來模擬各種頻率和時序的內存,測試項目為:SUPER PI 4M,EVEREST的內存測試,PCMARK的內存測試,其后將測試3DMARK05的得分。最后將加入應用軟件與專業軟件的測試。
測試軟件測試
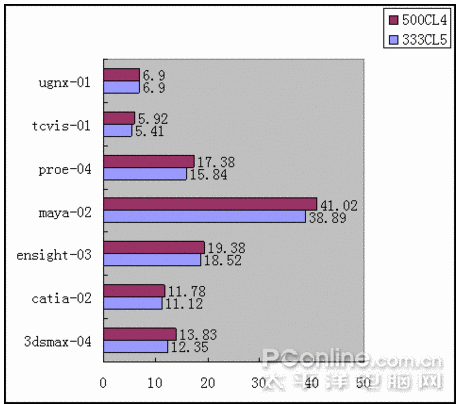
測試的芝奇內存從667MHZ超頻到1110MHZ,讀取速度快了2053MB/S,提升了約33%;寫入速度無法靠超頻獲得提升;內存復制速度快了1023MB/S,提升了約18%;內存延時慢了22.3NS,速度提升了27%;PCMARK05內存得分提高527分,提升了10%,3DMARK05得分增加290分,因為是個顯卡測試軟件,所以不好算提升比例,但290已經是個比較大的數值;4M PI快了6.6秒,提升幅度是比較可觀的。
因圖片數據過多,所以先做出了圖表,所有測試成績以表格形式列出,最后貼出成績差的配置截圖和成績好的配置截圖。
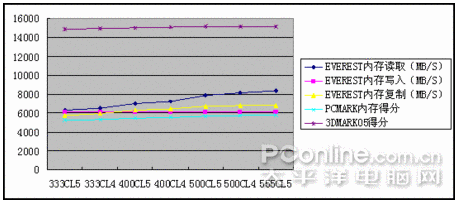
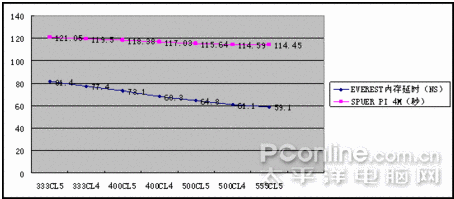
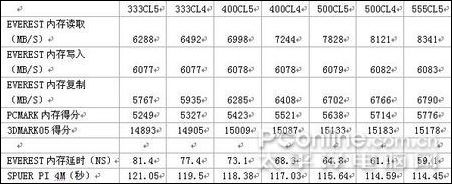
從前面三張圖可以看出,隨著CL值的減小與頻率的提升,性能是都有提升的。DDR2的時序活動空間不大,如果要穩定運行于CL3時序,頂級內存也只能降頻到800以下,常用的時序一般為4-4-4-12和5-5-5-15,而且從測試數據來看,DDR2內存,提升頻率帶來的性能提升比較明顯,同時,低時序帶來的提升也不可忽視。
MEM 333 CL5-5-5-15 4M PI截圖:
EVEREST內存測試截圖:
PCMARK05截圖:
3DMARK05截圖:
MEM 500 CL4-4-4-12 4M PI截圖:
EVEREST截圖:

PCMARK05截圖:
3DMARK05截圖:
應用軟件測試
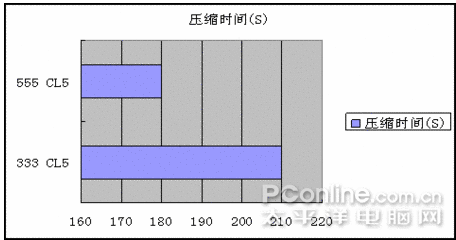
應用軟件測試,用winrar來測試內存性能對實際日常使用帶來的影響,壓縮對象為XPSP2光碟里面的I386目錄,已復制到硬盤,體積為542M,采用標準壓縮,每測試一次后刪除壓縮目錄重啟一次。只采用了667CL5和1110CL5兩種此次測試極端性能模式進行對比。
測試成績為:當內存運行667CL5時,壓縮I386目錄用時3分30秒,而當運行于1110CL5時,只用了3分鐘,整整快了30秒,相當于節約了1/7的時間,再一次說明了選擇高性能內存的必要性。
專業軟件測試
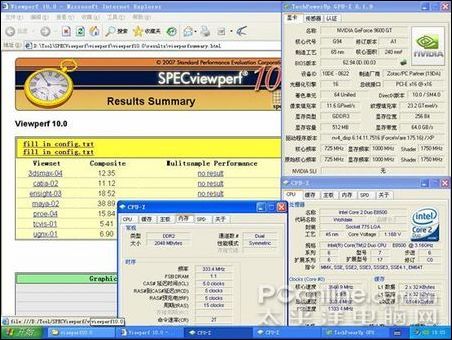
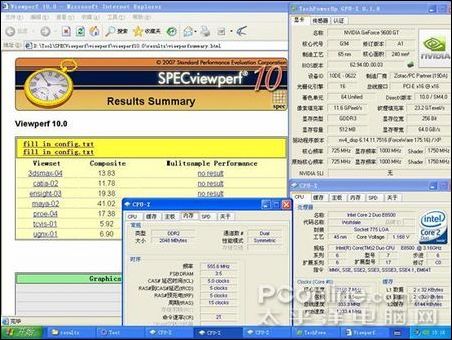
專業軟件測試:采用的是有代表性的SPECViewperf 10,SPECviewperf 10是圖形工作站專業顯卡OpenGL測試程序,可以測試顯卡在多個CAD/DCC應用程序中的OpenGL性能,包括3ds max、CATIA、EnSight、Maya、Pro/ENGINEER、SolidWorks等,它的成績可以比較真實的反映顯卡在這些軟件中的運行速度。為了盡量減低CPU的影響,此次測試CPU更換為默認3.16G的E8500,顯卡為9600GT。
SPECViewperf 10測試項目中,內存從333CL5提升到555CL5,各項測試均有不同程度的提升,以3DSMAX-04提升比例最大,所有的測試項目都是比較具有代表性的,因此,在專業軟件應用上,提升內存性能對提高工作效率,縮短工作時間均是有不小幫助的。
柱狀對比圖:

內存333/CL5時的表現:
內存500/CL4的表現:
總結
無論從測試軟件、普通應用軟件還是從專業軟件的測試情況來看,選擇高品質內存,提升內存性能對于整機性能的提升具有極大的意義,象國際知名的G.SKILL、OCZ之類的頂級內存品牌,價格也不是貴得離譜,非常值得選購。
為了對得起自己這三天的忙活,(那個證卡活總共還不到300元),決定把這個軟件完善一下,爭取能做成一個通用的小軟件見點效益,現在拿出來公開測試。頭10個測試出問題的朋友,等軟件完善后免費贈送正式版。
現在這個軟件肯定是有一些我沒有測到的問題,測試時間太短,另外也是看網友們是否認可這個軟件的功能,如果大家認可,在下一個版本中可以增加更多強大的功能,當然也是要花很多時間的,如果朋友們不認可,那這個軟件就當成自己用的小工具,不再多費力氣了。
不說太多廢話了,下面是軟件功能:
FoxPrint是一款簡易靈活的可變印刷軟件,可以在一個jpg圖片文件的固定位置寫入文字。文字的字體樣式和顏色可以提前設定好,然后根據在可變印刷頁面的設定,把大量可變數據寫入到這個jpg文件上,每一個數據和原圖片文件合成生成一個新的jpg圖片文件。
我們在印刷或者打印之前就可以通過Coreldraw或者其他拼版類軟件(如Preps)把這些不同的圖片拼到一張大版上進行輸出。
在印刷行業很少有人使用數據庫系統,一些先進的可變印刷軟件對設計師來說難以掌握,所以在這個1.0版本中沒有加入數據庫的功能。可變數據源方面我們提供兩種選擇:
一種是編號自動加一這種遞增方式,每個編號生成一個jpg圖片,這種方式容易理解、使用簡單,可以應付大部分的印務要求。
但是有些時候第一種方式并不能適合一些特殊的情況,比如婚宴中的請柬,每個人的人名都不同,并不是以數字形式來表示。本軟件提供了文本文件的方式來作為可變數據源,每一個可變數據在文本文件中占一行。如上面的請柬,每個客人名字在文本文件中占一行,這樣軟件可以根據文本文件的內容自動把所有請柬都輸出成一個個單獨的jpg圖片文件。
軟件當前還只是1.0版本,FoxPrint還不能適應可變印刷中更多的情況,如每個頁面上有兩個以上的可變數據項的復雜情況。后續的開發需要看我們這些中小從業者是否有足夠的需求,作者也是打印、復印的從業者,也開了個小復印門市照顧生計,如果新功能需求的人比較多,作者可以根據大部分的需求進行深入開發;如果這個軟件用途不大,開發就到此結束,算是只為這個項目做的小輔助功能軟件。
完全打包的下載地址: http://ishare.iask.sina.com.cn/f/5579492.html 下載FoxPrintFrameworkBeta.rar文件,迅雷可能下載不正常,用ie直接下載就行。
如果您機器上已經安裝微軟的 .net framework2.0 , 或者您手動從微軟網站下載net framework2.0,則可以在這個頁面 http://good.gd/222531.htm 下載 FoxPrintBeta.rar文件, 這個文件比較小,不到1M
幫忙測試的朋友,測試出問題可以在后面跟貼,當然最好不要寫重復的問題,前10個寫出問題的朋友請留下EMAIL地址,我把這些程序BUG解決后會給您郵箱發一份最新的程序。
]]>
一、測試軟件和插件的列表,花了大約8小時把軟件基本安裝的差不多,剩下沒裝的一般也用不到。軟件的第三方插件還得需要些時間,在后面測試的時候再安裝完善吧!因為我安裝和使用軟件比較業余,有什么不對的地方敬請指教,做不到的地方請諒解。
1、安裝的軟件列表如下圖 更新日期:2009.09.11
2、安裝完的軟件如下圖
3、Final Cut Studio 3新功能 請訪問: http://www.apple.com.cn/finalcutstudio/whats-new.html
4、Apple Snow Leopard Mac OSX系統新功能 請訪問:http://www.apple.com.cn/macosx/refinements/
安裝軟件感受:
1、蘋果的10.6系統打開dmg、cdr、iso文件超快,不管多大2秒內一定能打開。只有少數軟件dmg鏡像文件打開慢一些,它們是nuke5.1v6.dmg Poser7.dmg modo4.dmg。
2、在10.6系統上解決了在中文界面下安裝microsoft office 2008不用取消ProofingTools中Norwegian就可安裝上。
3、安裝The.Pixel.Farm.PFTrack.v4.1r3時候軟件加密驅動不能加載,好在是D版用不著也不影響使用。
4、有時退不出USB硬盤中NTFS分區,強制退出幾次和使用NTFS格式分區就四國語言(相當于Windows下藍屏),我裝了 Paragon.NTFS.for.Mac.v7.0.2暫時沒有發現用NTFS分區四國語言了,看來Snow Leopard本身在讀Windows系統的NTFS分區存在Bug.
5、系統自帶的QuickTime Player是64位的版本是10.0,我在蘋果官方網站沒看到這個版本,安裝和運行Final Cut Studio 3倒也沒有提示沒有QuickTime Player不讓裝的情況,后來發現32位版本的QuickTime Player在應用程序中的實用工具文件夾下。
6、安裝完Snow Leopard系統桌面上沒有看見硬盤,得手動顯示Macintosh HD硬盤,打開Macintosh HD硬盤下創建不了目錄,看來10.6系統安全性又提高了,我在桌面創建完文件移動到Macintosh HD下提示鑒定然后要求輸入密碼才能移過去.我沒有創建用戶密碼只是多點了兩下.我在蘋果Macbook Pro筆記本上安裝10.6沒有打開Macintosh HD硬盤下創建不了目錄的問題,具體原因我在找....
7、蘋果Snow Leopard 10.6系統啟動和關閉時間和Leopard 10.5我沒有感覺快,執行軟件和關閉軟件速度有了很大提高。總體感覺像使用10.5內核,打開了64位模式,編寫了幾個系統常用軟件64位版,做了些性能優化。
8、Snow Leopard 10.6系統比Leopard 10.5系統字體顯示清晰了很多,尤其是在Final Cut Pro軟件里更是明顯。
二、測試的硬件,手頭能借來什么就拿來用了,能力有限敬請諒解。
1、蘋果原裝機 型號MB535CH/A 標準配置,此機型取消了IEEE1394a 400硬件接口。
3、外置磁盤陣列(暫定)
三、驅動版本和QuickTime Player版本
1、AJA Kona3采集卡驅動,詳細情況請訪問:http://www.aja.com/support/kona/kona-3-3x.php
顯示器接在顯卡DVI口上裝KONA 3 Driver Version 6.5
顯示器接在顯卡DisplayPort口上裝KONA 3 Driver Version 6.5 NDD
2009.09.02我看到AJA針對Final Cut Pro 7出的KONA 3 Driver Version 7.0/7.0NDD驅動可以下載使用了
2009.09.08decklink采集卡系列新出了Snow Leopard驅動 詳細情況請訪問: http://www.decklink.com/support/software/snowleopard/
2、Redone攝像機拍的R3D文件Final Cut Pro 7支持,詳細情況請訪問:http://www.red.com/zh_CN/support/
REDCODE QuickTime Codec
RED Final Cut Studio 3 Installer
令人激動的Final Cut Studio 3中Color v1.5能直接打開.R3D文件
Final Cut Studio 3中Final Cut Pro 7記錄和傳輸中打開.R3D文件的幾種編碼方式
3、RED Final Cut Studio 3 Installer說明:Provides native REDCODE media (R3D) support for Final Cut Pro and Color. Includes: RED QuickTime Codec (v3.8.0), Log and Transfer (v20.0.0), REDCODE plugin for Color (v2.9), and Final Cut Studio RED workflow whitepaper. Note: Supports RED ONE cameras up through Build 20.
我的朋友說新出廠Redone攝像機拍攝的格式是Log and Transfer (v16.0.0),Final Cut Pro 6.0x中安裝的RED Final Cut Studio 2 Installer只能支持到Log and Transfer (v12.0.0),我確認這個問題可以用Final Cut Pro7+RED Final Cut Studio 3 Installer來解決。詳細信息請訪問:http://www.red.com/zh_CN/support/
4、Snow Leopard 10.6下的QuickTime Player 7位置在【應用程序=>實用工具】中,【應用程序】下的QuickTime Player是64位的。
32位版本QuickTime Player 7.63位置圖
64位版本QuickTime Player 10.0位置圖,運行這個版本很奇怪在桌面顯示中看不到它的界面,只能在進城管理器中看到它。
四、Final Cut Pro v7和采集卡驅動、編解碼穩定性測試
1、十五小時不中斷低壓縮比采集穩定性測試
測試通過......
2、高清數字電影視頻轉場、變速和簡單調光全片渲染穩定性測試
3、電視劇一集粗剪使用Photo-JPEG編碼回放,觀察音視頻是否同步和回放畫面是否出問題測試
4、EDL碼表回批素材,FCP7時間線中加轉場和變速效果素材是否有問題測試,在FCP6.0X中是一個很困擾人的問題,不知道FCP7是否改善了。
此測試項目中沒有FCP7實際操作使用測試,其中2、3、4項測試要有機會才行,測試完成時間未定。
五、安裝的軟件中哪個是64位的
暫時只有SIDEFX HOUDINI MASTER 10.0.374 MACOSX X86 64
六、安裝和顯示有問題軟件插件
1、顯示有問題的軟件
Imagineer Systems Mocha v1.0.0
Imagineer Systems Motor v1.1.3
2、Adobe AfterEffects CS4中顯示有些問題的插件
Digieffects Damage v1.2.21
DigiEffects Simulate Camera v1.0.22
DigiEffects Simulate Illuma v1.0.24
3、安裝不成功的插件
Genarts Sapphire v2.07 for Adobe AfterEffects CS4
Genarts Sapphire v2.08 for Adobe AfterEffects CS4(剛出的版本還有問題)
Genarts Sapphire v2.07/2.08在Adobe AfterEffects CS4中我已找到解決的辦法
Genarts Sapphire v2.09 for Adobe AfterEffects CS4支持Apple Snow Leopard系統了
Genarts Sapphire 2.02s41 for Apple Shake 4.1
這個在研究中....
4、使用不了的軟件名和版本
FTP傳輸軟件CuteFTP Mac 3.05版使用不了,這個軟件主要是和SGI機器IRIX系統傳輸文件用。
5、軟件語言顯示不對的
Roxio Toast Titanium v10.0.2多語言版在10.6系統中文界面下默認顯示的是英文???
解決辦法:除中文語言包zh.lproj保留外其它語言的.lproj文件全移走
6、其它插件顯示問題
Tiffen DFX v2 for Aperture 2.1.4
Tiffen DFX v2 for Adobe Photoshop CS4
因能力有限,這些是測試機器的一些照片
單八位RAID5盤陣
最新AJA KONA 系列Driver Version 7.0/7.0NDD驅動可以下載使用了,新圖標
Final Cut Pro 7 HD最新采集格式壓縮比:
]]>
EVEREST Ultimate Edition 5.02.1789 綠色多語版 - 支持Windows 7一個測試軟硬件系統信息的工具,32位的底層硬件掃描,使它可以詳細的顯示出PC硬件每一個方面的信息.支持上千種(3400+)主板,支持上百種(360+)顯卡,支持對并口/串口/USB這些PNP設備的檢測,支持對各式各樣的處理器的偵測.新的版本完全支持Windows XP和Windows 2003.
下載地址: http://d.namipan.com/sd/357666
HD Tune Pro V3.50 綠色MyCrack漢化修正版_主要用于檢測硬盤傳輸率、數據傳輸率工具HD Tune 是一款小巧易用的硬盤工具軟件 ,其主要功能有硬盤傳輸速率檢測,健康狀態檢測,溫度檢測及磁盤表面掃描等。另外,還能檢測出硬盤的固件版本、序列號、容量、緩存大小以及當前的Ultra DMA模式等。雖然這些功能其它軟件也有,但難能可貴的是此軟件把所有這些功能積于一身,而且非常小巧,速度又快,更重要的是它是免費軟件,可自由使用。本人覺得,把它作為一個硬盤溫度實時監測軟件非常合適。
下載地址: http://d.namipan.com/sd/357672
MemTest Version V3.8 綠色漢化版_檢測出內存的穩定度與檢索資料的能力MemTest 是少見的內存檢測工具 ,它不但可以徹底的檢測出內存的穩定度,還可同時測試記憶的儲存與檢索資料的能力,讓你可以確實掌控到目前你機器上正在使用的內存到底可不可信賴
下載地址:http://d.namipan.com/sd/357879
Nero InfoTool V5.3.3.0 綠色多語更新版_查刻錄機是否工作在UDMA模式下NeroInfoTool是光驅檢測、光盤刻錄的常用工具 ,它可以檢測光驅支持的讀取和寫入格式,檢查光盤的類型及制造商等信息。
漢化說明:
①此軟件的非標準字符串比較多,通過一些朋友反饋回來的以往版本的信息得知,其中一些非標漢化后可能造成軟件在某些平臺上運行異常。因此本漢化版會有一些未漢化的資源,但并不多,主要是為了穩定性考慮。
②調整優化了一些原版中部分控件的位置及大小。
下載地址: http://d.namipan.com/sd/357893
Nokia Monitor Test 2.0 綠色漢化特別版_NOKIA公司出品的專業顯示器測試軟件一款由NOKIA公司出品的專業顯示器測試軟件 ,功能很全面,包括了測試顯示器的亮度、對比度、色純、聚焦、水波紋、抖動、可讀性等重要顯示效果和技術參數。Nokia Monitor Test 小小的身材,一張軟盤即可攜帶,卻帶給我們強大的功能。您可以在購買顯示器時帶著它,經過它檢測過的顯示器可以放心購買,也可以用它來更好地調節你的顯示器,讓您的顯示器發揮出最好的性能。Nokia Monitor Test,不會讓您失望的
下載地址: http://d.namipan.com/sd/357900
CpuZ V1.42.0 漢化綠色版提供全面的CPU相關信息報告 ,包括有處理器的名稱、廠商、時鐘頻率、核心電壓、超頻檢測、CPU所支持的多媒體指令集,并且還可以顯示出關于CPU的L1、L2的資料(大小、速度、技術),支持雙處理器。目前的版本已經不僅可以偵測CPU的信息,包括主板、內存等信息的檢測CPU-Z同樣可以勝任。新版本加入對新一代處理器的支持,包括90 nm Athlon 64的代碼,加強了顯示系統內存的資料顯示,例如內存的生產廠商、SPD速度設定等,而且新版本可以顯示PCI-Express接口的資料。
①本漢化對所有的非標準資源字符串基本上都進行了漢化,包括主界面和生成的報告,這樣以來我們就可以利用Cpu-Z生成中文版的檢測報告了(包括網頁報告和文本報告,推薦生成網頁報告)。當然,文本報告的可讀性也比較強。
②修正了Windows 98下字體顯示不美觀的問題。強烈感謝雅楓及其他各位好友對此問題的支持。
③此版本不支持 Windows 98,英文原版即如此。可能是軟件 BUG 吧。
關于幾處翻譯(本人經驗所得,如若不當,敬請指正):
①FSB、HTT:兩者的基本意思一樣,后者對應于AMD的CPU。我們知道,對于FSB的解釋,很長時間以來都是指“前端總線”,但是現在也有人將其解釋為“外頻”,比如CPU-Z本身,這樣很容易引起混淆,因此索性將它們兩個的位置重新進行了調整。
②Bus Speed:直譯為“總線速度”,通俗講就是指“外頻”,因此也將它的位置進行了調整。
③Brand ID:此參數是為了更加詳細區分CPU的種類,可以翻譯為“品種標識”,不過其它CPU類軟件慣用的翻譯即為“商標 ID”,比如AIDA32,因此沿用。
下載地址: http://d.namipan.com/sd/357938 ]]>
默認開啟的 ME引擎允許xReader在CPU主頻為48Mhz的條件下流暢播放MP3。
1.2.0-beta6已支持后臺加載圖像,與其它PSP漫畫查看軟件相比,效率、穩定性更高。默認最多將10張圖像加入到緩存。
剛才升級了5.50-GEN(A),xReader正常運行。 然而3.71下xReader 1.2.0-beta6無法播放WMA。
使用TTF功能要求下載字體,參考:http://bbs.pspchina.net/thread-279005-1-1.html
已支持以下音樂格式:
MP3(硬件解碼)
WMA(硬件解碼)
AAC/MP4(音頻部分)/M4A (AAC LC/HE/HEv2 硬件解碼)
MPC(Musepack SV7/SV8)
OGG
FLAC
APE(最高支持標準壓縮方式)
TTA
AA3/OMA/AT3/(Sony Atrac3/Atrac3Plus)
WavPack(支持混雜模式)
WAV
Changelog:
1.2.0-beta6
[!]緩解后臺預讀帶來的內存碎片問題
[!]修復數個內存泄露問題
[!]修復無法在目錄中打開中文文件名圖像問題
[!]修復圖像旋轉設置無效問題
[!]修復改變圖像亮度時競爭關系
[!]修復音樂系統競爭關系
[!]播放OGG文件時使用緩沖IO
[!]修復字型系統的BUG
[!]修復保存/讀取文件位置菜單顯示文件名亂碼問題
[!]修復按鍵鎖被打開后搖桿未被鎖定問題
[!]修復文字編碼設置為UTF-8時打開非UTF-8文本死機問題
[+]設置管理可以保存、裝載多個播放列表
[+]添加at3 aa3 m4a音樂格式緩沖大小設置
1.2.0-beta5
[!]修復某些HTML文件轉換后丟失內容問題
[!]修復某些非標準MP3格式聲音拖慢問題
[!]打開所有音樂格式的內容緩沖,播放音樂時記憶棒不再狂閃
[!]修復大量內存泄露、兩次釋放問題,提高穩定性并節省內存
[!]優化TTA播放效率,流暢播放從原來的需要222Mhz到現在的只需111Mhz
[!]修復PSP搖稈出故障時假死問題
[!]閱讀電子書時狀態欄開啟TTF模式后不再閃爍顯示時間
[+]加入圖像后臺預讀功能,默認開啟緩沖10張圖像
[+]支持打開"CBZ" 漫畫壓縮檔案
[+]支持打開"CBR" 漫畫壓縮檔案
[+]加入fonts.conf字體配置文件,可根據配置優化字體顯示效果
1.2.0-beta4
[!]修正隨機播放次序
[!]修復在恢復菜單中開啟記憶棒加速后,書簽功能失靈問題
[!]修復自動滾屏速度太慢問題
[!]修復音樂系統中多個BUG, 穩定性進一步提高
[!]為防止爆音,播放MP3時CPU頻率提高到48Mhz
[+]支持顯示MP3 lame幀信息(設置配置文件中show_encoder_msg=on后)
[+]允許長按左右耳朵鍵對音樂文件進行快進/退
[+]在音樂條中允許按上鍵快進30秒,按下鍵快退30秒
[+]支持ogg格式
[+]支持wma格式,與cooleyes合作研究硬解WMA成功
[+]支持AT3/AA3/OMA格式(Atrac3/Atrac3Plus編碼)
[+]支持AAC/MP4/M4A格式(AAC LE編碼)
[+]支持打開"THM" PSP視頻預覽文件
1.2.0-beta3
[!]修復某些長文件名不能完全顯示導致不能打開問題
[!]修復壓縮檔案中顯示文件排序方式為以文件大小無效問題
[!]修復切換頻率時線程競爭關系
[!]修復音樂系統中多個BUG, 穩定性進一步提高
[+]自動打開千千靜聽保存在MP3 ID3v2標簽中的歌詞信息
[+]允許長按線控快進/退鍵對音樂文件進行快進/退, 長按線控播放鍵休眠PSP
[+]支持Musepack SV8
[+]添加圖像磁性滾動功能, 可在圖像邊緣處不滾動直接翻下一頁
[+]添加看圖選項翻頁滾動間隔/翻頁滾動時長功能, 進一步控制翻頁滾動
1.2.0-beta2
[!]修復退出時有極小機率死機問題
[!]取消默認強制檢查MP3校驗和,提高某些MP3裝載速度及啟動xReader速度
[!]修復某些MP3不能正確播放的問題
[+]添加MP3緩沖代碼,播放MP3時MS燈不再狂閃
[+]MP3支持ME播放,播放時CPU頻率僅需33Mhz
[+]支持APE格式(最高支持標準壓縮方式)
[+]支持FLAC格式
[+]音樂條上顯示動態比特率(如果有),以及編碼格式
[+]在音樂條按L+R鍵可重啟音頻系統,音頻系統出問題時可試試
1.2.0-beta
[!]修復上次保存圖像、文件位置更新錯誤
[!]修復HTML、CHM顯示亂碼、死機等問題
[!]修復待機時死機問題
[!]隨機播放完其它歌曲之前,不再會重復播放同一首歌
[!]修復操作靈敏度不足問題
[!]修復自動翻頁時間變長問題
[+]在圖像幻燈片播放狀態下,按○鍵暫停幻燈片移動或到下一幅圖像,按L/R鍵直接移動到上/下一幅圖像
[+]重寫音樂播放系統,目前支持Musepack、MP3、WAV、TTA格式
[+]MP3標簽支持ID3v1、ID3v2、APE標簽顯示
[+]MP3支持VBRI信息,如果有此信息的MP3裝載速度將大幅加快
推薦音樂編碼:
有損音頻格式:
高音質下(192kbps以上):MPC = OGG > MP3 > WMA > AAC
低音質(~64kbps)下: AAC > WMA > OGG > MP3 > MPC
使用可硬件解碼的編碼能夠省電,并節省CPU資源干其他的事情。
無損音頻格式:
FLAC>TTA=WavPack>APE
推薦FLAC的主要原因是FLAC解碼速度很快,只需66Mhz即可,大小卻同其他無損格式差不多。
消滅爆音:
xReader作為一個省電的播放器,有時不能處理低頻率下記憶棒速度不穩定的現象。如果播放音樂時出現爆音現象,有以下解決方法:
1. 5.00M33-6用戶可以用恢復菜單的Speed UP MS Access(加速記憶棒)功能,設置為Game或Always
2. 如果以上方法無效,可以將系統選項.設置最低頻率的值提高到爆音消失為止。
最后有爆音問題時不要忘記通知我一下,歡迎上傳有問題的音樂樣本。
]]>
1 研究背景
隨著敏捷開發的流行,傳統的軟件測試也在發生著翻天覆地的變化。傳統的軟件測試已不能適應當前的開發方式,急需新的理論和方法論來尋求改變,并以此來推進軟件工程的進步。本文將關注與敏捷測試相關理論與技術。
1.1 敏捷技術方法與分析
我們現在面對著飛速變化的業務和技術環境。在這樣一個環境中,傳統的軟件開發方法所認為需求需要在項目初期分析清楚并且保持穩定的想法是行不通的。不能快速持續的將需求變化融合到軟件中就意味著對業務環境反映遲鈍,最終導致業務上的失敗。同樣,新技術不斷地涌現,也要求軟件產品的代碼時刻處于一種良好的狀態,能夠適應各種調整。于是,敏捷開發過程應運而生。
2001年以Kent Beck,Martin Fowler,Robert C.Martin及Ward Cunningham等為首的一些軟件工程的專家成立了“敏捷聯盟”(Agile Alliance),并提出了著名的敏捷宣言,即敏捷過程的價值觀:
? 人和交互重于過程和工具。
? 可以工作的軟件重于求全責備的文檔。
? 客戶合作重于合同談判。
? 隨時應對變化重于循規蹈矩。
這些價值觀是專家們在求同存異的基礎上對敏捷技術的最基本的總結,也是他們在敏捷技術方面達成的最大共識,其反映的是兩個更深層的特點:
1) 敏捷型方法是“適應性”而非“預見性”
工程方法試圖對一個軟件開發項目在很長的時間跨度內做出詳細的計劃, 然后依計劃進行開發。這類方法在一般情況下工作良好,但(需求、環境等) 有變化時就不太靈了。因此它們本質上是拒絕變化的。而敏捷型方法則歡迎變化。其實,它們的目的就是成為適應變化的過程,甚至能允許改變自身來適應變化。
2) 敏捷型方法是“面向人”的,而非“面向過程”的
工程型方法的目標是定義一個過程,不管是誰用都工作。而敏捷型方法 則認為沒有任何過程能代替開發組的技能,過程起的作用是對開發組的 工作提供支持。
敏捷聯盟還以這4個價值觀為原則,提出了敏捷過程的12條指導原則,以期能更好的指導人們了解敏捷過程。
敏捷開發過程,指的就是一種與傳統的瀑布模型開發和CMM(Capability Maturity Model,軟件開發的能力成熟度模型)所追求的嚴謹的文檔制度截然相反的開發過程。這一開發過程注重開發團隊和成員之間的關系而不是以開發的進程和使用的工具為重點,注重所開發的軟件產品而不是追求廣泛的文檔編制,注重開發過程中與客戶的協同工作而不是以簽訂合同的談判為工作的核心,注重在開發過程中隨時調整計劃而不是同意完全遵循某一開發計劃,以實現所謂開發過程的“敏捷”。
1.2 敏捷測試及其研究現狀
敏捷方法的發展,打破了傳統的瀑布開發模型,改變了整個軟件開發過程中的角色和定位。由于在敏捷開發運動的初期,主要依靠開發人員來進行推動。很多測試人員不了解敏捷方法,仍然習慣了按照傳統的瀑布模式進行軟件測試,即按照V模型所指導的步驟進行測試,保證軟件與需求、設計的相符合,但這樣很容易形成了一種測試思維的定勢。當“用戶需求不明確”、“需求變化較快”時,沿用傳統測試方法的測試人員將變的無所適從。
目前比較流行的敏捷測試方法有測試驅動開發和相關環境驅動測試等。還有很多國外知名專家按照“敏捷”的原理為軟件測試開發了相應的測試框架,其中最著名的就是Kent Beck等提出的xUnit系列單元測試框架和Ward Cunningham等提出的Framework for Integrated Test(FIT)集成測試框架。xUnit系列提出的比較早,目前已有一套完善的測試工具和方法論來支持了,適用于各種語言的單元測試。FIT框架是當前國內外的研究重點,很多知名的測試專家如Lisa Crispin等都在如何使用FIT進行有效的軟件測試方面得出了很多的研究成果。
1.3 基于接口參數的測試用例自動生成算法
在軟件測試工作中,由于輸入、輸出空間,特別是輸入空間的無限性,使得無法對軟件進行全面的測試。因此,如何從大量的輸入數據中挑選適量的具有代表性、典型性的數據,特別是怎樣用較少的測試用例對軟件進行較全面的測試是測試人員面臨的一大難題。
測試用例的選擇無論是對黑箱測試還是對白箱測試都起著關鍵的作用,決定著軟件測試的質量和效果。所謂測試用例選擇就是指從所有的可用測試用例中選出少量典型的測試用例,以達到對測試域的最大限度覆蓋。多年來,許多研究者對之進行了廣泛而深入的研究,并取得了許多研究成果。常用的基于接接口參數的黑箱測試用例選擇方法是對系統每個接口參數采用邊際值分析法和等價類劃分法等選取一組典型的值,然后在這些取值組合中隨機選取一組測試用例,或者使用一些啟發式方法從中進行篩選。但這些方法的缺點是帶有主觀傾向性,不具有普遍性。
2 基于敏捷測試的相關技術討論
2.1 FIT框架及應用
在敏捷開發過程中,軟件測試是至關重要的,尤其是在最為流行的敏捷開發過程:極限編程(XP)中顯的更為突出。誠然,所有的過程都提到測試,但一般都不怎么強調。可是XP將測試作為開發的基礎,要求每個程序員寫一段源碼時都得寫相應的測試碼。這些測試片段不斷地積累并被整合到系統中。這樣的過程會產生一個高度可靠的建造平臺,為進一步開發提供了良好的基礎。
但是,即使是單元測試工具JUnit也存在一些缺點:比如JUnit里要進行數據填充,但是數據經常改變,使維護工作變成了可怕的噩夢,測試不同的組合,需要不同的數據,這也許會使測試工作變得日益復雜。而目前的集成測試又缺乏有效的方法論,不能自動化,測試的質量比較依賴測試人員的水平。
Framework for Integrated Test(簡稱FIT)就是一個用于增強交流和協作的工具。FIT創建了一個在客戶和程序員之間的反饋循環。FIT讓客戶和測試人員可以使用諸如Microsoft Office之類的工具來給出程序應當如何表現的例子——而無需成為直接編碼的程序員。FIT自動針對實際的程序檢測那些例子,這樣就在業務世界和軟件工程世界之間建立了一個簡單而且有效的橋梁。
FIT給予了客戶和程序員一個關于軟件的精確交流的方法。客戶所給的具體的例子讓程序員能深刻理解將要構建的產品。程序員的對于裝置的工作和軟件可以讓客戶給出不同的例子進行試驗來獲取對于軟件如何真正工作更深入的了解。這樣通過一起工作,整個團隊可以學會更多關于產品的內容并產生更好的結果。
2.2 測試用例自動生成技術
正交試驗設計起源于科學試驗,它由田口玄一博士在1949年創立,并于60年代初從日本傳人中國。它應用依據Galois理論導出的正交表,從大量試驗條件中挑選出適量的、有代表性的條件來合理地安排試驗。運用這種方法安排的試驗具有“均勻分散、整齊可比”的特點。“均勻分散”性使試驗點均衡地分布在試驗范圍內,讓每個試驗點有充分的代表性;“整齊可比”性使試驗結果的分析十分方便,可以估計各因素對指標的影響,找出影響事物變化的主要因素。
但正交試驗設計仍然存在著一些有待解決的弊端:比如正交表難以構造,因素、水平過多時測試用例數目還是過多等。所以一些專家又提出一種基于對接口參數進行組合覆蓋的黑箱測試用例自動生成算法模型,據此來得到一個對所有接口參數進行兩兩組合覆蓋的測試用例表。這種方法有著類似正交試驗設計的特點,實際上,在特定情況下,這種算法模型得出的測試用例表就是正交表。
3 技術實現的考慮
3.1 基于FIT框架對軟件進行集成測試
使用基于FIT框架的開源FIT工具來實現真正的測試先行開發過程,并讓客戶、需求提報工程師、開發人員、以及測試人員進行協同工作,達到需求更精準、減少需求更改、測試數據與JUnit單元測試代碼分離的目的,讓這一切更簡潔、更易于維護。
將根據以下步驟進行研究:
1) 使用FIT框架進行實際項目測試的實踐,從中提煉出一套使用FIT框架進行集成測試的通用方法。
2) 通過實踐,對FIT框架進行合理的改進和拓展,結合JUnit單元測試,現實單元測試和集成測試的無縫連接,達到提高軟件質量的效果。
3) 在理論研究和實踐的基礎上,規約出適用于單元測試和集成測試的通用方法。
3.2 整合測試用例的自動生成技術至FIT
按照敏捷過程中“簡單”原則,本課題將編寫一個輔助接口測試的工具,用來自動產生少而有效的測試用例,以達到對測試域的最大限度覆蓋。通過該工具產生的測試用例表,能符合FIT框架的要求,并可被FIT所執行而得到HTML形式的可視化的測試結果。通過這種方式,大大增加了測試的自動化。
為了實現該目標,將按照以下步驟進行研究:
1) 查看“正交試驗設計方法”的原理及其資料,了解測試用例生成的規則。
2) 查閱兩兩覆蓋測試用例生成的相關算法,并根據算法用程序實現,進行實踐研究。
3) 根據實踐研究,對兩兩覆蓋測試用例進行改進,以期能更高效的實現測試用例的生成。
4) 修改依據改進后的算法實現的測試工具,使其輸入輸出符合FIT框架的要求。在此基礎上,把此工具集成到FIT框架中。
4 小結
本文討論了當前軟件測試中的兩大重要研究領域:敏捷測試方法和測試用例的選擇與生成技術。進一步的工作是,根據“敏捷”的集成測試框架FIT需要人工構造表格形式的數據作為輸入的前提,深入研究如何自動生成FIT需要的表格數據?再對FIT進行擴展,為FIT嵌入測試用例表格自動生成功能。其中測試用例集的生成將依據各參數兩兩覆蓋的原則,以求達到對測試域的最大限度覆蓋
| 軟件開發和使用的歷史已經留給了我們很多由于軟件缺陷而導致的巨大財力、物力損失的經驗教訓。這些經驗教訓迫使我們這些測試工程師們必須采取強有力的檢測措施來檢測未發現的隱藏的軟件缺陷。 生產軟件的最終目的是為了滿足客戶需求,我們以客戶需求作為評判軟件質量的標準,認為軟件缺陷( Software Bug )的具體含義包括下面幾個因素: ? 軟件未達到客戶需求的功能和性能; ? 軟件超出客戶需求的范圍; ? 軟件出現客戶需求不能容忍的錯誤; ? 軟件的使用未能符合客戶的習慣和工作環境。 考慮到設計等方面的因素,我們還可以認為軟件缺陷還可以包括軟件設計不符合規范,未能在特定的條件(資金、范圍等)達到最佳等。可惜的是,我們中的很多人更傾向于把軟件缺陷看成運行時出現問題上來,認為軟件測試僅限于程序提交之后。 在目前的國內環境下,我們幾乎看不到完整準確的客戶需求說明書,加以客戶的需求時時在變,追求完美的測試變得不太可能。因此作為一個優異的測試人員,追求軟件質量的完美固然是我們的宗旨,但是明確軟件測試現實與理想的差距,在軟件測試中學會取舍和讓步,對軟件測試是有百益而無一弊的。 下面是一些軟件測試的常識,對這些常識的理解和運用將有助于我們在進行軟件測試時能夠更好的把握軟件測試的尺度。 ? 測試是不完全的(測試不完全) 很顯然,由于軟件需求的不完整性、軟件邏輯路徑的組合性、輸入數據的大量性及結果多樣性等因素,哪怕是一個極其簡單的程序,要想窮盡所有邏輯路徑,所有輸入數據和驗證所有結果是非常困難的一件事情。我們舉一個簡單的例子,比如說求兩個整數的最大公約數。其輸入信息為兩個正整數。但是如果我們將整個正整數域的數字進行一番測試的話,從其數目的無限性我們便可證明是這樣的測試在實際生活中是行不通的,即便某一天我們能夠窮盡該程序,只怕我們乃至我們的子孫都早已作古了。為此作為軟件測試,我們一般采用等價類和邊界值分析等措施來進行實際的軟件測試,尋找最小用例集合成為我們精簡測試復雜性的一條必經之道。 ? 測試具有免疫性(軟件缺陷免疫性) 軟件缺陷與病毒一樣具有可怕的 “ 免疫性 ” ,測試人員對其采用的測試越多,其免疫能力就越強,尋找更多軟件缺陷就更加困難。由數學上的概率論我們可以推出這一結論。假設一個 50000 行的程序中有 500 個軟件缺陷并且這些軟件錯誤分布時均勻的,則每 100 行可以找到一個軟件缺陷。我們假設測試人員用某種方法花在查找軟件缺陷的精力為 X 小時 /100 行。照此推算,軟件存在 500 個缺陷時,我們查找一個軟件缺陷需要 X 小時,當軟件只存在 5 個錯誤時,我們每查找一個軟件缺陷需要 100X 小時。實踐證明,實際的測試過程比上面的假設更為苛刻,為此我們必須更換不同的測試方式和測試數據。該例子還說明了在軟件測試中采用單一的方法不能高效和完全的針對所有軟件缺陷,因此軟件測試應該盡可能的多采用多種途徑進行測試。 ? 測試是 “ 泛型概念 ” (全程測試) 我一直反對軟件測試僅存在于程序完成之后。如果單純的只將程序設計階段后的階段稱之為軟件測試的話,需求階段和設計階段的缺陷產生的放大效應會加大。這非常不利于保證軟件質量。需求缺陷、設計缺陷也是軟件缺陷,記住 “ 軟件缺陷具有生育能力 ” 。軟件測試應該跨越整個軟件開發流程。需求驗證(自檢)和設計驗證(自檢)也可以算作軟件測試(建議稱為:需求測試和設計測試)的一種。軟件測試應該是一個泛型概念,涵蓋整個軟件生命周期,這樣才能確保周期的每個階段禁得起考驗。同時測試本身也需要有第三者進行評估(信息系統審計和軟件工程監理),即測試本身也應當被測試,從而確保測試自身的可靠性和高效性。否則自身不正,難以服人。 另外還需指出的是軟件測試是提高軟件產品質量的必要條件而非充分條件,軟件測試是提高產品質量最直接、最快捷的手段,但決不是一個根本手段。 ? 80-20 原則 80% 的軟件缺陷常常生存在軟件 20% 的空間里。這個原則告訴我們,如果你想使軟件測試有效地話,記住常常光臨其高危多發 “ 地段 ” 。在那里發現軟件缺陷的可能性會大的多。這一原則對于軟件測試人員提高測試效率及缺陷發現率有著重大的意義。聰明的測試人員會根據這個原則很快找出較多的缺陷而愚蠢的測試人員卻仍在漫無目的地到處搜尋。 80-20 原則的另外一種情況是,我們在系統分析、系統設計、系統實現階段的復審,測試工作中能夠發現和避免 80% 的軟件缺陷,此后的系統測試能夠幫助我們找出剩余缺陷中的 80% ,最后的 5% 的軟件缺陷可能只有在系統交付使用后用戶經過大范圍、長時間使用后才會曝露出來。因為軟件測試只能夠保證盡可能多地發現軟件缺陷,卻無法保證能夠發現所有的軟件缺陷。 80-20 原則還能反映到軟件測試的自動化方面上來,實踐證明 80% 的軟件缺陷可以借助人工測試而發現, 20% 的軟件缺陷可以借助自動化測試能夠得以發現。由于這二者間具有交叉的部分,因此尚有 5% 左右的軟件缺陷需要通過其他方式進行發現和修正。 ? 為效益而測試 為什么我們要實施軟件測試,是為了提高項目的質量效益最終以提高項目的總體效益。為此我們不難得出我們在實施軟件測試應該掌握的度。軟件測試應該在軟件測試成本和軟件質量效益兩者間找到一個平衡點。這個平衡點就是我們在實施軟件測試時應該遵守的度。單方面的追求都必然損害軟件測試存在的價值和意義。一般說來,在軟件測試中我們應該盡量地保持軟件測試簡單性,切勿將軟件測試過度復雜化,拿物理學家愛因斯坦的話說就是: Keep it simple but not too simple 。 ? 缺陷的必然性 軟件測試中,由于錯誤的關聯性,并不是所有的軟件缺陷都能夠得以修復。某些軟件缺陷雖然能夠得以修復但在修復的過程中我們會難免引入新的軟件缺陷。很多軟件缺陷之間是相互矛盾的,一個矛盾的消失必然會引發另外一個矛盾的產生。比如我們在解決通用性的缺陷后往往會帶來執行效率上的缺陷。更何況在缺陷的修復過程中,我們常常還會受時間、成本等方面的限制因此無法有效、完整地修復所有的軟件缺陷。因此評估軟件缺陷的重要度、影響范圍,選擇一個折中的方案或是從非軟件的因素(比如提升硬件性能)考慮軟件缺陷成為我們在面對軟件缺陷時一個必須直面的事實。 ? 軟件測試必須有預期結果 沒有預期結果的測試是不可理喻的。軟件缺陷是經過對比而得出來的。這正如沒有標準無法進行度量一樣。如果我們事先不知道或是無法肯定預期的結果,我們必然無法了解測試正確性。這很容易然人感覺如盲人摸象一般,不少測試人員常常憑借自身的感覺去評判軟件缺陷的發生,其結果往往是把似是而非的東西作為正確的結果來判斷,因此常常出現誤測的現象。 ? 軟件測試的意義 - 事后分析 軟件測試的目的單單是發現缺陷這么簡單嗎?如果是 “ 是 ” 的話,我敢保證,類似的軟件缺陷在下一次新項目的軟件測試中還會發生。古語說得好, “ 不知道歷史的人必然會重蹈覆轍 ” 。沒有對軟件測試結果進行認真的分析,我們就無法了解缺陷發生的原因和應對措施,結果是我們不得不耗費的大量的人力和物力來再次查找軟件缺陷。很可惜,目前大多測試團隊都沒有意識到這一點,測試報告中缺乏測試結果分析這一環節。 結論: 軟件測試是一個需要 “ 自覺 ” 的過程,作為一個測試人員,遇事沉著,把持尺度,從根本上應對軟件測試有著正確的認識,希望本文對讀者對軟件測試的認識有所幫助 |
| 以下內容含腳本,或可能導致頁面不正常的代碼 |
|---|
| 說明:上面顯示的是代碼內容。您可以先檢查過代碼沒問題,或修改之后再運行. |
windows 7 rtm 7600 chn x64 ultimate
用的是正版序列號:P 當時在MSDN開始測試WIN7的時候就申請到了.
可惜只能用到2010年中旬
硬件: (這里以主流機型作為測試.比較有代表性
Intel E8400 Stepping C0 3.0GHz / O.C 3.6GHz (做一下超頻的對比)
OCZ DDR2-800 2G * 2
Gigabyte EP45-UD3R
Leadtek 9800GTX (G92-A200 10DE 65nm)
Seagate 7200.11 640G 32M SATA2
Acbel IP470
驅動和測試軟件:
Forceware 190.18 for windows7 / vista x64 whql
intel infAllOS
Realtek ALC888
Alias Maya 7.0 32bit
Autodesk Maya 2008 32bit Ex2
Autodesk Maya 2009 64bit Sp1
Autodesk Maya 2010 64bit
Blastcode for Maya 2008/2009
Renderman Pro for Maya 2008
Renderman Eval for Maya 2009
Maxya MEL Editer
Digital Fusion 5.0
Digital Fusion 6.0 x64
Autodesk Toxik 2009 Sp2
Adobe Photoshop CS4 x64 / x86
Adobe AfterEffects CS4
Adobe SoundBooth CS4 (縮寫是SB XD
Edius 5.0 x86
測試方法:
進行一般性操作.測試基本兼容性.(太麻煩的我會吐血....
格式如下:
軟件:
兼容:
優點:
缺點:
解決方法:
對比系統是windows server 2003 x64 R2
好了現在開始正題.測試結果:
軟件: Alias Maya 7.0 32bit
兼容: NO
優點: 暫無
缺點: 四視圖顯示白圖.單視圖界面也會白圖.只要鼠標離開視圖區域.或者是不激活視圖.就白圖.
解決方法: 暫無.等著NV更新驅動吧.Alias已經被AD吃了..不可能再做這個版本的兼容包了.
軟件: Autodesk Maya 2008 32bit Ex2
兼容: NO
優點: 暫無
缺點: 白圖依然.類似7.0;另外安裝Rm pro 135和Rms1.0.1以后load會直接crash.
解決方法: 暫無
軟件: Autodesk Maya 2009 64bit Sp1
兼容: Most
優點: 比原來漂亮...
缺點: 不白圖了終于.但是RM無法使用.找不到shader path.而且09的Rm沒有Slim..當然正版的有....
解決方法: 不用RM的同學們可以忽略
軟件: Autodesk Maya 2010 64bit
兼容: YES
優點: 比09還好看...新增功能等等...并且暫時試驗中完全兼容...
缺點: 無任何插件可用...
解決方法: 等吧..
先寫到這...等會繼續...哎- -.
下了個Dt的RM教程結果杯具了....09沒有Slim.08直接crash...
我換系統去了- -.]]>
以下以TP 600E 為范例,硬盤是好的。現在可以開始測試了!
不好意思,我沒有DC,只有攝像頭,不是很清晰,大家湊合看吧。
一、將軟盤放到軟驅,并進BIOS設置為軟驅啟動。
二、開機用軟驅引導,出現如下界面,選擇第2項,只測試ATA硬盤。
[ Last edited by c@ini@o on 2004-3-17 at 14:09 ]

1.jpg
[ Last edited by c@ini@o on 2004-3-17 at 14:12 ]

2.jpg
[ Last edited by c@ini@o on 2004-3-17 at 14:12 ]

3.jpg
1、“Quick Test”:快速測試。
快速測試時間最短,但只能進行簡單的測試。
2、“Advanced Test”:高級測試。
高級測試耗時較長,但測試內容詳盡,硬盤有無問題均可測試出來,推薦使用。
[ Last edited by c@ini@o on 2004-3-17 at 14:13 ]

4.jpg
點擊“STRAT”,開始了。
需要注意的是,測試開始后,鼠標均不能使用。
[ Last edited by c@ini@o on 2004-3-17 at 14:14 ]

5.jpg
completed successfally ,DISPOSITION CODE=0*00,意思是 運算全部成功,點擊“OK”,又退回前一畫面。
[ Last edited by c@ini@o on 2004-3-17 at 14:14 ]

6.jpg
經過長時間的測試后,因為我的硬盤是好的,所以仍然提示:Operation
completed successfally,DISPOSITION CODE=0*00。
如果硬盤有任何問題,均不會出現上述提示,會有其它錯誤代碼提示并且畫面背景為紅色(后附錯誤代碼表)這樣,我們只需花不很長的時間就可以知道硬盤是好的還是壞的了。
需要注意的是,測試時間與硬盤容量大小有關,硬盤越大,測試時間越長,我的6。4G硬盤高級測試花了12分鐘。
[ Last edited by c@ini@o on 2003-12-28 at 14:52 ]
[ 本帖最后由 c@ini@o 于 2005-11-12 14:33 編輯 ]
我們看標題欄,有:DRIVE、FITNESS TEST UTILITES、HELP。
1、DRIVE(驅動器)下有:SLETCT DRIVE ALT-S(選擇驅動器),用來選擇你想測試的驅動器。
RESCAN BUS ALT-R:我查英漢詞典查不到什么意思。
EXIT ALT-X:退出,沒什么好說的。
[ Last edited by c@ini@o on 2004-3-17 at 14:18 ]

7.jpg
ADVANCED TEST :高級測試 這個我也介紹過了。
[ Last edited by c@ini@o on 2004-3-17 at 14:21 ]

8.jpg
ERASE BOOT SECTOR(抹去分區表)很顯然,這項是在分區表損壞時用來重建分區表的。我的硬盤是日立的,無法使用這一項。
ERASE DISK(格式化硬盤)應該是低級格式化。只能用在IBM的硬盤上。
CORRUPTED SECTOR REPAIR(修復壞的部分)應該是可以修復一些小問題,同樣只適用IBM硬盤。
ATA FUNCTIONE下有S。M。A。R。T。 OPERATIONS這項我記不清什么意思了。
[ Last edited by c@ini@o on 2004-3-17 at 14:22 ]

9.jpg
點擊DRIVE INFO(驅動器信息)后,顯示如下畫面:
MODEL(型號):HITACHI_DK239A-65B
CAPACITY(容量):6.45GB
CACHE SIZE(緩沖大小):512KB
ATA COMPLIANCE(看不懂):ATA-4(應該是ATA接口速率)
ULTRA DMA
HIGHEST MODE(高度方式,我也不明白什么意思):2
ACTIVE MODE(活動方式 ,我也不明白什么意思):2
SETTINGS 設置
WRITE CACHE(書寫緩沖):ENABLED(開啟)
READ LOOK-AHEAD(不懂):ENABLED(開啟)
S。M。A。R。T。 OPERATIONS(不懂):ENABLED(開啟)
S。M。A。R。T. STATUS(不懂):GOOD
SECURITY FEATURE(安全特性):SUPPORTED(支持)
PASSWORD(密碼):NOT SET (沒設)
SECUTITY MODE(不懂):FROZEN (不懂)
[ Last edited by c@ini@o on 2004-3-17 at 14:23 ]

10.jpg
希望拙文能給需要的朋友一些幫助,愿大家都能買到一塊好硬盤!
[ Last edited by c@ini@o on 2003-12-28 at 15:10 ]
補充一下檢測結束后錯誤代碼表:
0X00 - Not error
0X10- Aborted
0X20 - Device Not Present
0X22 - Password Protected
0X30- Out of memory
0X31- Wrong Parameter
0X32- Illegal Parameter
0X33- Function not supported
0X40- System Error
0X41- Bad Cable
0X42 - Temerature Limit exceeded
0X43- Pending SCSi Request
0X44- System Vibration
0X45- Low system Performance
0X70- Defective Device
0X71- Device Nor Ready
0X72- Device SMART Error
0X73- Device Damaged By Shock
0X74- SMART self test Error SMART
0X75 Defective device
]]>
基于模式的靜態代碼分析、運行時內存監測、單元測試以及數據流分析等軟件驗證技術是查找嵌入式C語言程序/軟件缺陷行之有效的方法。上述技術中的每一種都能查找出某一類特定的錯誤。即便如此,如果用戶僅采用上述技術中的一種或者幾種來進行驗證,這樣的驗證方法很有可能會漏過對程序中的一些缺陷的檢查。解決此類問題的一種安全和有效的策略就是同時使用上述軟件驗證中的所有互補技術。這樣就能建立起一個牢固的框架來幫助用戶檢查出可能會避開某種特定技術的缺陷。與此同時,用戶也自然地建立起一個能檢測出關鍵并且難以查找的功能性錯誤的環境。
本文將詳盡闡述基于模式的靜態代碼分析、運行時內存錯誤檢測、單元測試以及數據流分析等自動化技術共同使用時是如何查找出嵌入式C語言程序/軟件中的缺陷的。本文中將以Parasoft C++test為例來演示上述各項技術。C++teST是一個經廣泛的最佳實踐證明能提升軟件開發團隊開發效率以及軟件質量的自動化集成解決方案。
當讀者在閱讀本文以及任何時候思考查找到的缺陷時,關注文中的截圖是很重要的。自動化檢測例如內存崩潰和死鎖的缺陷,毫無疑問對任何開發團隊都是一項必不可少的任務。盡管如此,最致命的缺陷卻是功能性錯誤,這往往是難以自動發現的。在本文的結論部分我們將簡要地討論一下查找這些缺陷的技術。
情景簡介
為了給出一個具體的示例,我們將就一個我們最近遇到的案例來介紹以及演示我們所推薦的缺陷查找策略:一個運行在ARM 板上的簡單傳感器應用程序。
假設我們已經創建了該應用系統,但是當我們將程序上載到系統目標板上并試圖運行該程序時,我們沒有在LCD屏上看到所預期的輸出。
我們尚不明確系統不能正常工作的原因,因此我們設法對系統進行調試,但是在目標板上進行調試是一件耗時而且煩人的事。因為我們不得不手動分析調試器的結果并試圖人工判斷出問題的真正原因。或者我們使用一些被證實能自動定位出錯誤的工具或技術來幫助我們減輕負擔。
從這一點而言,我們要么期待使用調試器來調試程序能夠帶來好運,要么我們嘗試使用一種自動化的測試策略來查找代碼中所存在的錯誤。如果自動化技術仍然沒有幫助我們查找到錯誤,那么我們不得不回到使用調試器作為最后的辦法。

基于模式的靜態代碼分析
這里,我們假設僅在絕對必要的情況下才使用調試器進行調試,因此我們從運行基于模式的靜態代碼分析開始。它將查找到如下圖所示的問題:

這是違反了 MISRA 的一個規則,此違規說明該處的賦值運算符存在一些可疑情況。的確,編程者此處的本意是使用比較運算符而不是賦值運算符。因此我們將此處檢測到的沖突修改掉,并重新運行程序。
我們發現有了一些改善:一些輸出被顯示在了LCD屏上了。但是,由于一次訪問違規,程序崩潰掉了。因此我們需要再次地做出選擇。我們是應該使用調試器還是繼續使用自動化的錯誤檢測技術。由于經驗告訴我們自動化錯誤檢測技術能非常高效地檢查出我們當前程序所遇到的內存崩潰這類問題,因此我們決定使用運行時內存監測來查找問題。
整個程序的運行時內存監測
為了進行運行時內存監測,我們使用 C++test 來插裝應用程序。這樣的插裝是輕量級的,所以經過插裝后的程序適合在目標板上運行。當我們把程序上載到目標板上并運行經過插裝的程序后,我們將結果下載到PC上,如下的錯誤將被報告出來:

該結果指出在第48行代碼處產生了一次讀取數組越界的錯誤。顯然,msgIndex變量的值肯定超過了數組的范圍。如果我們隨著堆棧追蹤上一級的原因,我們將發現此處的打印信息所指示的值的確超出了數組的范圍(因為在調用printMessage()函數前我們給出了一個錯誤的條件)。我們可以刪除掉這個不必要的條件(value <= 20)以修改這個錯誤。
void handleSensorValue(int value)
{
initialize();
int index = -1;
if (value >= 0 && value <= 10) {
index = VALUE_LOW;
} else if ((value > 10) && (value <= 20)) {
index = VALUE_HIGH;
}
printMessage(index, value);
}
然后我們重新運行程序,將不會再報告任何內存錯誤。當我們把程序上載到目標板上時,它似乎如我們預期那么在工作了。盡管如此,我們仍然有一些擔心。
我們僅查找到我們所執行的代碼路徑中的一個內存寫溢出實例,我們憑什么能夠斷定我們尚未執行到的代碼就不會有內存寫溢出錯誤了呢?如果我們檢查覆蓋率分析,我們就會發現reportSensorFailure()這個函數從未被執行到。我們有必要對這個函數進行測試,但是具體如何進行呢?建立一個調用該函數的單元測試用例就是一個不錯的辦法。
在單元測試中使用運行時內存監測:我們使用C++test的測試用例向導來創建一個測試用例的框架,并向其中添加一些測試代碼。然后運行該測試用例——以檢查上面提到的未經測試的函數,同時打開運行時內存監測功能。使用C++teST,全過程大約只需要數秒鐘。結果標明該函數已經被覆蓋到了,但同時也查找到了新的錯誤:

我們的測試用例查找到了更多的內存相關錯誤。很顯然,當失敗處理函數被調用時,我們的內存初始化存在問題(空指針)。通過更進一步的分析,我們發現在reportSensorValue()函數中存在函數調用順序錯誤。finalize()函數先于printMessage()函數被調用,但是finalize()函數中釋放了printMessage()函數需要使用的內存。
void finalize()
{
if (messages) {
free(messages[0]);
free(messages[1]);
free(messages[2]);
}
free(messages);
}
將函數調用順序進行修改后,我們重新運行程序。
這樣我們就解決了上面報告中的第一個錯誤。現在我們再來分析報告中的第二個錯誤:即打印信息中的AccessViolatiONException。產生這個錯誤的原因是相應的消息列表未經初始化。為了解決該問題,我們在打印該信息前調用一次initialize()函數來對其進行初始化。經修改后的函數如下所示:
void reportSensorFailure()
{
initialize();
printMessage(ERROR, 0);
finalize();
}
當我們再次運行該測試用例時,僅有一個任務被報告出來:未經驗證的單元測試用例(an unvalidated unit test case),這其實并不算一條錯誤。我們只需對輸出進行一下驗證,以將該測試用例轉換為回歸測試。通過創建合適的斷言,C++test會自動為我們完成這些步驟。

接下來我們再次運行整個程序。覆蓋率分析告訴我們幾乎整個程序都已經被覆蓋到了,并且沒有發現任何內存錯誤。
這樣就結束了嗎?其實不然。雖然我們運行了整個程序并為未覆蓋到的函數創建了單元測試用例,但還是有一些路徑是沒有被覆蓋到的。我們仍然可以繼續創建單元測試用例,但是若指望通過這樣的方法來覆蓋程序中的所有路徑將耗費相當長的時間。或者我們使用另外的方法,使用數據流分析來對這些路徑進行模擬。
數據流分析
我們使用C++test的BugDetective來進行數據流分析,BugDetective能模擬系統中的不同路徑并檢查這些路徑中是否存在潛在的問題。進行數據流分析后,我們得到如下結果:

仔細分析報告的結果,我們發現程序中存在一條未被覆蓋到的潛在路徑可能會造成在finalize()函數中出現兩次free的操作。在程序中,reportSensorValue()函數調用了finalize()函數,然后finalize()函數調用了free()。同時,finalize()函數還會被mainLoop()函數調用。我們可以修改finalize()函數以使其更加智能化,從而修復這個問題,修改后的代碼如下:
void finalize()
{
if (messages) {
free(messages[0]);
free(messages[1]);
free(messages[2]);
free(messages);
messages = 0;
}
}
現在我們再次運行數據流分析,得到的結果將只有兩個問題:

這里我們可能使用了-1作為索引來訪問了數組。這是由于整型變量index被設置的初始值為-1,并且存在一條可能通過if語句的路徑在未將該整型變量正確的進行初始化之前便調用了printMessage()函數。運行時分析未檢查到這樣的一條路徑,并且該路徑很有可能在真實世界中永遠不可能被執行到。這就是靜態數據流分析相對于運真實運行時內存監測最主要的不足:數據流分析能檢查出潛在的路徑,這些路徑可能包含在程序實際執行過程中不會執行到或不存在的路徑。盡管如此,為了做到有備無患,我們刪除了上述的不必要的條件(value>=0)以修改這個潛在的錯誤。
void handleSensorValue(int value)
{
initialize();
int index = -1;
if (value <= 10) {
index = VALUE_LOW;
} else {
index = VALUE_HIGH;
}
printMessage(index, value);
}
相同地,我們也對最后一個報告的錯誤進行相應的處理。現在我們再次運行數據流分析,將不會再有錯誤被報告出來。
為了確保程序運行一切正常,我們重新運行整個分析過程。首先,我們開啟運行時內存監測并運行應用程序,一切表現正常。然后我們開啟內存監測并運行單元測試,一個任務被報告出來:

我們的單元測試檢測到reportSensorFailure()函數的行為已經發生了改變。這是由于我們已經對finalize()函數進行了修改——為了糾正之前報告的一個問題所做的修改。此處報告的任務是為了讓我們注意此修改,并提示我們應該對測試用例進行相應的審查,并且確定是否應該對代碼或者測試用例進行相應的修改,以表示這種新的行為實際上是我們所預期的行為。在檢查完代碼之后,我們發現后者(修改)是正確的并且應該更新斷言的正確條件。
/* CPPtest_TEST_CASE_BEGIN test_reportSensorFailure */
/* CPPTEST_TEST_CASE_CONTEXT void reportSensorFailure(void) */
void sensor_tests_test_reportSensorFailure()
{
/* Pre-condition initialization */
/* Initializing global variable messages */
{
messages = 0 ;
}
{
/* Tested function call */
reportSensorFailure();
/* Post-condition check */
CPPTEST_ASSERT(0 == ( messages ));
}
}
/* CPPTEST_TEST_CASE_END test_reportSensorFailure */
作為最終的確認,我們需要獨立地運行整個程序——在IDE中關閉掉運行時內存監測來對程序進行構建。結果顯示一切如我們所預期一樣運行。
總結
作為全文的結尾,讓我們一起對上述各個步驟進行一個鳥瞰式的總結。
首先,我們開發的程序并未如我么所預期那樣運行,我們不得不在兩種解決方法中選擇一種來查找程序中的錯誤:通過運行調試器或者使用自動錯誤檢測技術。
如果我們使用調試器運行代碼來查找錯誤,我們將會看到一些很奇怪的現象:程序中的一些變量總是被賦予了相同的值。基于這種現象我們不得不通過排除法來查找問題的原因——即在應該使用比較運算符的地方我們錯誤地使用了賦值運算符。而靜態代碼分析則能為我們自動地檢查出該邏輯錯誤。運行時內存分析是不可能檢查出這種錯誤的,因為這種錯誤與內存無關。數據流分析也很有可能找不到這類錯誤因為數據流分析僅僅是通過這些路徑而不會驗證這些條件的正確性。
當我們解決了這個問題后,程序可以運行了,但是仍然還有內存相關的問題。內存相關的問題是很難被調試器發現的;當用戶使用調試器調試程序時,用戶并不知道內存的實際大小。但是自動錯誤檢查工具能夠做到這點。因此,為了查找這些內存問題,我們將整個程序進行插裝,并使用運行時內存分析工具來運行程序。這樣我們就能知道到底是那一片內存發生了寫溢出錯誤。
盡管如此,在審查覆蓋率分析結果的時候,我們注意到在目標板上測試的時候,并不是全部代碼都被覆蓋到了。通過自動化的工具得到這樣的覆蓋率信息是簡單的,因為工具會自動地
跟蹤覆蓋率,但是,如果我們是通過調試器,就不得不判斷哪一部分程序經過了驗證。而這通常只能依靠我們人工記錄的方式來實現。
當工具提醒我們一些代碼未被覆蓋到時,我們決定改變單元測試來額外地增加我們測試執行的覆蓋率。這就揭示了程序中另外一些問題。在目標系統的正常測試中,覆蓋所有函數也許是不可能完成的任務,因為其中一些函數可能是硬件的失敗處理函數或僅在某些小概率的特定情況下才會被調用的函數。而對這些函數的測試對于一些注重安全性的程序而言又是至關重要的。試想在飛機上用來處理速度傳感器問題的程序中存在著代碼錯誤:我們會有系統崩潰的危險,而不是導致某個設備為非工作狀態。因此,通過創建單元測試用例來覆蓋這類型的執行路徑往往是對其進行有效測試的唯一方法。
接下來,我們修復了工具檢查到的所有問題,同時通過驗證相應的結果創建了一個回歸測試用例(作為報告的任務之一引導我們完成)。然后我們運行數據流分析來覆蓋在目標系統上即便使用單元測試也未執行到的路徑。在此之前,我們幾乎已經達到了100%的代碼行覆蓋率,但是我們的路徑覆蓋率卻未達到這個水平。BugDetective幫我們發現了這些方面的一些潛在問題。這些問題可能并沒有實際發生或者有可能永遠不會發生。也許在實際運行時,這些問題僅僅會在當其條件滿足的情況下才會出現,并且在現實生活中,這些條件可能永遠不可能滿足。盡管如此,我們不能保證隨著代碼的升級,應用程序不會執行到這些路徑。
安全起見,我們仍然修改了所報告的問題以排除任何可能影響它的實際應用執行的風險。在修改代碼的同時,我們同時也引入了回歸測試,當我們再次運行單元測試時立即被檢測到。在所有的自動化錯誤檢測方法中,回歸測試是唯一能夠幫助我們檢查到代碼是否發生了功能性的改變的方法,并且能驗證出對代碼進行的修改是否引入了功能性的錯誤以及不可預知的副作用。最后,我們修改了回歸測試套件,并重新測試代碼,發現一切運行正常。
正如讀者所見,我們使用的一切測試方法——基于模式的靜態代碼分析、內存分析、單元測試、數據流分析以及回歸測試——并不是相互競爭的關系,恰好相反,它們是一種互補的關系。將上述工具結合使用,它們就是一套具有強大作用的工具集,并為嵌入式C語言程序/軟件提供一個無可比擬的自動化錯誤檢測解決方案。
總而言之,通過自動地查找很多關于內存和其它編碼的缺陷,我們成功地讓程序運行起來了。盡管如此,值得注意的是,最危險的缺陷卻是實際的功能性錯誤:例如程序并未如所指定的要求運行。而不幸的是,這些錯誤往往是非常難以被發現的。
查找這類缺陷的最好的一個方式就是通過同行代碼審查來實現。即另指派至少一人來檢查代碼并且審查代碼與需求內容的一致性,這樣用戶就能對實際程序是否會如預期那樣運行有一個很好的*估。
另外一個十分有用的策略是圍繞代碼創建一個回歸測試套件,這能幫助用戶快捷地驗證代碼與規范的一致性。在本文所描述的示例情景中,單元測試被用來強制執行應用程序級的運行時內存監測所未覆蓋到的代碼:它能覆蓋到當前程序的功能性,在此之后,我們對代碼做了一些修改,它能提醒我們代碼出現的相應的功能性問題。事實上,這種單元測試用例應該被更早地創建起來:理想情況下,當用戶在實現程序的功能時就應該被創建起來。這樣,用戶就能得到更高的覆蓋率并同時構建起一個更強壯的“安全網”來捕捉關鍵的功能性改變。
Parasoft的C++test能幫助用戶完成這兩個任務:從自動化到管理同行代碼審查流程,以及幫助團隊創建,持續地運行并維護一個高效的回歸測試套件。
關于Parasoft C++test
Parasoft C++test是一個經廣泛的最佳實踐證明能提升軟件開發團隊開發效率以及軟件質量的自動化集成解決方案。C++test能進行諸如編碼策略增強、靜態代碼分析、運行時內存監測、自動同行代碼審查以及單元和組件測試,從而為軟件開發團隊提供一種更加實用的方法來確保其C以及C++程序能如所預期那樣工作。C++test可以用于在通用開發IDE下的桌面平臺中,以及在回歸測試時通過命令行以批處理模式的方式運行。同時,C++test還集成了Parasoft的報告系統,該系統能提供具有細分能力的基于Web 的儀表板,這使得開發團隊根據C++test的測試結果和其他的一些關鍵進程指標來更加方便地跟蹤項目的狀態和趨勢。
通過在宿主機上進行大量的測試以及在目標系統中進行的平滑的驗證,C++test能夠幫助軟件開發團隊減少花在嵌入式系統開發中的時間、精力以及成本。隨著代碼在宿主機上的構建,C++test的自動化框架使得開發者能在目標硬件系統尚未準備好的情況下就開始測試以提升代碼質量。這大大地縮短了花在目標系統上測試的時間。早期在宿主機上構建的測試套件可以被重用來在仿真器或真實的目標板上驗證程序的功能性。
]]>