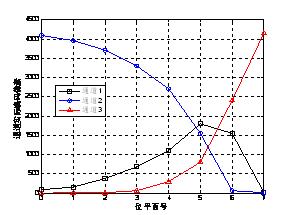
łD3 ╬╗ŲĮ├µŠÄ┤a╚²éĆ═©Ą└ŽĄöĄŠÄ┤aöĄ┴┐ūā╗»╩ŠęŌłD
═©▀^ī”ē║┐sąį─▄蹊┐░l¼FŻ¼į┌ē║┐s▒╚▌^ąĪĢr▒Š╬─Ė─▀M╦ŃĘ©▒╚ś╦£╩╦ŃĘ©Ą─ē║┐sąį─▄╝sĄ═0.4dbū¾ėęŻ¼į┌ē║┐s▒╚▌^┤¾Ģrā╔š▀Ą─ē║┐sąį─▄ŽÓę╗ų┬Ż¼▒Ż┴¶┴╦JPEG2000ā׫ɥ─ē║┐sąį─▄Ż╗Å─ŠÄĮŌ┤aĢrķgüĒ┐┤Ż¼į┌ėąōpē║┐sŠÄ┤ał╠ąąĢrķg╔ŽŻ¼▒Š╬─╦∙Įo│÷Ą─Ė─▀M╦ŃĘ©▒╚ś╦£╩╦ŃĘ©Ģrķg┐sČ╠8%ĄĮ12%Ż¼ĮŌ┤aĢrķg┐sČ╠2%ĄĮ5%Ż¼╠ßĖ▀┴╦ŠÄ┤aą¦┬╩Ż¼▀_ĄĮ┴╦Ė─▀MĄ──┐Ą─ĪŻ
3 JPEG2000ś╦£╩ųąĖ─▀M╦ŃĘ©Ą─DSPīŹ¼F
3.1 DSPė▓╝■ķ_░lŲĮ┼_
▒Š╬─╩╣ė├įu╣└░Õ╩Ū▒▒Š®┬ä═ż╣½╦ŠĄ─TDS642Ż¼░Õ╔ŽĄ─DSPąŠŲ¼╩ŪTMX DM642Ż¼BGA548ĘŌčbŻ¼ā╚▓┐╣żū„ĢrńŖ×ķ600MŻ¼═Ō▓┐┐éŠĆĢrńŖ×ķ100MŻ¼ėŗ╦Ń─▄┴”Ė▀▀_4.8ā|ųĖ┴Ņ├┐├ļĪŻ
įōŲĮ┼_╠ß╣®┴╦žSĖ╗Ą─═Ōć·Įė┐┌ĪŻ░Õ╔Žėąā╔éĆÅ═║ŽęĢŅlŻ©PAL/NTSC/SECAMSŻ®▌ö╚ļ║═1éĆÅ═║ŽęĢŅl▌ö│÷Č╦┐┌Ż╗┴ó¾w┬Ģ▌ö╚ļ/│÷╗“å╬ę╗¹£┐╦’L▌ö╚ļČ╦┐┌Ż╗╠ß╣®ā╔éĆUARTĪóęį╠½ŠWĮė┐┌Īóūė░ÕĮė┐┌ĪóPC104Įė┐┌║═JTAGĮė┐┌[6][7]ĪŻ░Õ╔Ž▀Ć╠ß╣®┴╦4M BytesĄ─Flash┤µā”Ų„Ż¼╬╗ė┌DM642Ą─CE1ĄžųĘ┐šķgŻ¼īÆČ╚×ķ8bitsŻ¼FPGAöUš╣┴╦3Ė∙ĄžųĘŠĆŻ¼░čFlashĘų│╔8ĒōŻ¼Flash Ą─Ą┌0ĒōĄ─Ū░░ļĒō┤µĘ┼ė├æ¶Ą─ūįåóäė│╠ą“Ż¼║¾░ļĒō┤µĘ┼FPGA│╠ą“Ż¼Ą┌1Ēō╬▓ė├æ¶┤µĘ┼öĄō■┐šķgŻ¼Ą┌2Ēōų┴Ą┌8Ēōė├ė┌┤µĘ┼ė├æ¶│╠ą“ĪŻ
3.2 ║╦ą─╦ŃĘ©Ą─DSPīŹ¼F
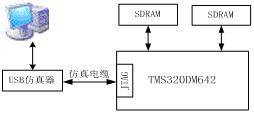
Ż©1Ż®╦ŃĘ©┐é¾w┐“╝▄ĪŻ▒Š╬─╦ŃĘ©╗∙ė┌DM642EVMīŹ¼FĢrų„ę¬Ęų×ķā╔éĆ┤¾Ą──ŻēKŻ©╚ńłD4Ż®Ż¼Ą┌ę╗▓┐Ęų×ķDWTūāōQ─ŻēKŻ¼╦³īó▌ö╚ļłDŽ±öĄō■ūāōQ×ķę╗ŽĄ┴ąĄ─ąĪ▓©ŽĄöĄŻ╗Ą┌Č■▓┐Ęų×ķEBCOT╦ŃĘ©─ŻēKŻ¼īó┴┐╗»║¾Ą─Ą─ąĪ▓©ŽĄöĄŠÄ┤a╔·│╔ē║┐s┤a┴„ĪŻė▓╝■ķ_░lŲĮ┼_ĮYśŗ┐“łD╚ńłD5╦∙╩ŠĪŻ

łD4 ╦ŃĘ©┐“╝▄łD
łD5 ╦ŃĘ©ė▓╝■ķ_░lŲĮ┼_ĮYśŗ┐“łD
Ż©2Ż®ā╚┤µĘų┼õĪŻī”ė┌łDŽ±öĄō■Ą─╠Ä└ĒŻ¼═∙═∙╔µ╝░ĄĮ┤¾┴┐Ą─Å═ļsĄ─öĄō■īżųĘėŗ╦ŃŻ¼ī”ė┌Å═ļsĄ─īżųĘėŗ╦ŃŻ¼Ųõ║─┘MCPUĄ─ėŗ╦Ń┴┐┐╔─▄▒╚īŹļHöĄō■▓┘ū„Ą─ėŗ╦Ń┴┐▀Ć┤¾ĪŻ╦∙ęįę¬╝ė┐ņCPUī”öĄō■Ą─įLå¢╦┘Č╚Ż¼▓╗Ą½ę¬Ū¾┤µā”Ų„▒Š╔ĒĄ─╦┘Č╚┐ņŻ¼Č°Ūę▀ĆąĶę¬ę╗éĆ║Ž└ĒĄ─öĄō■ĮYśŗüĒ║å╗»CPUī”ĄžųĘĄ─ėŗ╦ŃĪŻ┴Ē═ŌŻ¼DM642ī”öĄō■Ą─įLå¢╝╝ągŻ¼╚ńCacheĪóEDMA║═īÆbitöĄō■ų▒ĮėūxīæĄ╚Ż¼Č╝╩Ū╗∙ė┌┤µā”ĄžųĘĄ─▀B└mąįĪŻ╗∙ė┌ęį╔Ž┐╝æ]Ż¼▒Š╬─į┌ā╚┤µĘų┼õ╝░Č©╬╗ĢrŻ¼ę└ō■ęįŽ┬┤¾Ą─įŁätŻ║Ą┌ę╗Ż¼į┌ØMūŃŠ½Č╚ę¬Ū¾Ą─ŪķørŽ┬Ż¼╩╣ė├▌^Č╠Ą─öĄō■ŅÉą═Ż╗Ą┌Č■Īó┤¾Ą─öĄō■ēKŻ¼╚ńįŁ╩╝łDŽ±ĪóųžśŗłDŽ±┤µā”į┌Ų¼═ŌSDRAMŻ╗Ą┌╚²ĪóĻPµIöĄō■ĪóąĪĄ─öĄō■ēKŻ¼▒╚╚ń▀\╦ŃĢrĄ─ŽĄöĄĪóŽĄĮyČ茯Īó╚²éĆ═©Ą└Æ▀├ĶČ╝ąĶę¬ŅlĘ▒Ą─įLå¢öĄō■ģ^║═╔ŽŽ┬╬─ś╦ųŠģ^Ą╚Ż¼┤µĘ┼ĄĮŲ¼ā╚┤µā”Ų„Ż╗Ą┌╦─Īóī”L2╝ē┼õų├ūŃē“Ą─Cacheęį▒ŃCPUī”öĄō■Ą─┐ņ╦┘ūxīæŻ╗Ą┌╬ÕĪóī”ė┌Š▀ėą▀\╦ŃŽÓĻPąįĄ─öĄō■Ż¼æ¬į┌ā╚┤µųą░┤ą“▀B└m┼┼Ę┼ĪŻ«ö╔µ╝░ĄĮŲ¼ā╚═ŌöĄō■ēKĄ─░ßęŲ▓┘ū„ĢrŻ¼┐╔ė╔DM642Ą─EDMAå╬į¬╚ź═Ļ│╔Ż¼╦³┐╔┼cCPU▓óąą╣żū„Ż¼▓╗š╝ė├CPUĄ─ėŗ╦Ńų▄Ų┌[8]ĪŻ
Ż©3Ż®łDŽ±öĄō■Ą─ūxīæĪŻė╔ė┌▒Š╬─╣żū„ų„ę¬═Ļ│╔ßśī”łDŽ±Ą─ē║┐s╣”─▄Ż¼▓╗╔µ╝░łDŽ±▓╔╝»Ż¼╦∙ęįį┌łDŽ±öĄō■Ą─▌ö╚ļ▌ö│÷╔Žū÷┴╦▀m«öĄ─╠Ä└ĒĪŻ┐╝æ]ĄĮCCSĄ─Simulator═Ļ╚½ų¦│ųC/C++šZčįŻ¼ę“┤╦įŁ╩╝łDŽ±öĄō■Ą─▌ö╚ļ▓╔ė├CšZčįųąĄ─Ņ^╬─╝■ą╬╩ĮŻ¼ąĪ▓©ūāōQ─ŻēKŻ¼EBCOT╦ŃĘ©─ŻēK▓╔ė├┤µĘ┼į┌PCÖCĄ─öĄō■╬─╝■ą╬╩ĮĪŻ▒Š╬─ų„ę¬▓╔ė├Ņ^╬─╝■║═Č■▀MųŲöĄō■╬─╝■Ą─ą╬╩ĮŻ¼īółDŽ±Ą─ĘŪ╬─╝■Ņ^▓┐ĘųĄ─╦∙ėąöĄō■═©▀^Ī░fprintfŻ©fpŻ¼Ī░%3dŻ¼Ī▒Ż¼image_in [i][j]Ż®Ī▒šZŠõīæĄĮ.h╬─╝■ųąĪŻ
Ż©4Ż®DWTĄ─īŹ¼FĪŻė╔ė┌DM642×ķČ©³c╠Ä└ĒŲ„Ż¼▓╗▀m║Žė┌ĖĪ³c▀\╦ŃŻ¼╦∙ęį▒Š╬─▀xō±LeGallŻ©5Ż¼3Ż®š¹öĄ×V▓©Ų„═Ļ│╔JPEG2000ųąĄ─ąĪ▓©ūāōQĪŻį┌▀MąąąĪ▓©ūāōQĢrŻ¼╩ūŽ╚Č©┴xā╔éĆ┼cłDŽ±ēK┤¾ąĪŽÓĄ╚Ą─┤µā”ŠÅø_Ų„Ż¼ę╗éĆ╩ŪłDŽ±Ų¼öĄō■Ą─▌ö╚ļŠÅ┤µBufŻ¼ę╗éĆ╩Ūė├üĒ┼RĢr┤µĘ┼łDŽ±Ų¼öĄō■ĮøąĪ▓©ūāōQ║¾Ą─ĮY╣¹ŠÅ┤µTempBufĪŻ├┐Įø▀^ę╗╝ēąĪ▓©ūāōQŻ¼łDŽ±Ų¼öĄō■Č╝ꬎ╚║¾ā╔┤╬Įø▀^integerŻ©5Ż¼3Ż®Ą─Ą══©║═Ė▀═©×V▓©ĪŻTempBufųą▒Ż┤µĄ─Ė▀═©×V▓©öĄō■ĮøintegerŻ©5Ż¼3Ż®×V▓©Ų„╠Ä└Ē║¾Ż¼Ą├ĄĮHLūėĦ║═HHūėĦĄ─ąĪ▓©ūāōQŽĄöĄĪŻūŅ║¾īóūāōQĮY╣¹┤µĘ┼ĄĮ▌ö╚ļŠÅ┤µBufųąĪŻ╚¶ę¬▀MąąŽ┬ę╗╝ēĘųĮŌŻ¼ų╗ąĶī”BufųąLLūėĦ▀Mąą═¼śė╠Ä└Ē

 ╝ė║├ėč
╝ė║├ėč  ░lČ╠ą┼
░lČ╠ą┼

 Post ByŻ║2010-11-20 13:33:55
Post ByŻ║2010-11-20 13:33:55






