ś╦Ņ}Ż║TMS320C6000ŽĄ┴ąDSPĄ─▄ø╝■ā×╗»╝╝ąg
|
1 DSPŽĄĮyĄ─▄ø╝■ā×╗»┴„│╠ DSPŽĄĮyĄ─▄ø╝■ā×╗»┴„│╠╚ńłD1╦∙╩ŠĪŻš¹éĆ╣żū„┴„│╠Ęų×ķ3éĆļAČ╬Ż║
Ą┌1ļAČ╬Ż¼ų▒ĮėĖ∙ō■ąĶę¬ė├Ė▀╝ēCšZčįīŹ¼FDSP╣”─▄Ż¼£yįć┤·┤aĄ─š²┤_ąįĪŻ╚╗║¾Ż¼ęŲų▓ĄĮC6XŲĮ┼_Ż¼└¹ė├C6Xķ_░lŁhŠ│Profile£yįć│╠ą“Ą─▀\ąąĢrķgĪŻ╚¶▓╗ØMūŃę¬Ū¾Ż¼ät▀M╚ļŽ┬ę╗ļAČ╬ĪŻ Ą┌2ļAČ╬Ż¼└¹ė├C6X╠ß╣®Ą─ā×╗»ĘĮ╩Į║═Ųõ╦¹Ė„ĘNā×╗»╝╝Ū╔Ż¼╚ń╩╣ė├▓╗═¼Ą─ŠÄūgŲ„▀xĒŚ╩╣─▄▄ø╝■┴„╦«Ż¼čŁŁhš╣ķ_Ż¼ūų┤µ╚Ī┤·╠µ░ļūų┤µ╚ĪĄ╚Ż¼ā×╗»CšZčį┤·┤aĪŻ╚ń╣¹▀Ć▓╗─▄ØMūŃę¬Ū¾Ż¼ät▀M╚ļĄ┌3ļAČ╬ĪŻ Ą┌3ļAČ╬Ż¼īóCšZčį┤·┤aųą║─ĢrūŅķLĄ─▓┐Ęų│ķ╚Ī│÷üĒŻ¼ė├ŠĆąįģRŠÄšZčįųžīæŻ¼ė├ģRŠÄā×╗»Ų„▀Mąąā×╗»ĪŻ╩╣ė├profile┤_Č©▀@Č╬┤·┤a╩ŪʱąĶę¬▀Mę╗▓Įā×╗»ĪŻ 2 ā×╗»▀^│╠ ╩ūŽ╚Ż¼ė├CšZčįŠÄīæ│╠ą“Ż¼▓ó═©▀^ŠÄūg“×ūCŲõš²┤_ąįĪŻ╚╗║¾Ż¼╩╣ė├ā╚┬ō║»öĄ║═║Ž▀mĄ─ā×╗»▀xĒŚ▀Mąąā×╗»Ż¼▓ó═©▀^CCSųąĄ─profiler┤_Č©╩Ūʱėą║»öĄąĶę¬▒╗▀Mę╗▓Įā×╗»Ż¼╩╣ė├ŠĆąįģRŠÄšZčįųžīæąĶę¬▒╗ā×╗»Ą─║»öĄĪŻūŅ║¾Ż¼╩╣ė├ģRŠÄā×╗»ŠÄ│╠╝╝Ū╔║═ģRŠÄā×╗»Ų„ā×╗»ģRŠÄ┤·┤aĪŻ 2.1 ŠÄūgŲ„ «öā×╗»Ų„▒╗╝ż╗ŅĢrŻ¼īó═Ļ│╔łD2╦∙╩ŠĄ─▀^│╠ĪŻCŻ»C++šZčįį┤┤·┤a╩ūŽ╚═©▀^ę╗éĆ═Ļ│╔ŅA╠Ä└ĒĄ─ĮŌ╬÷Ų„(Parser)Ż¼╔·│╔ę╗éĆųąķg╬─╝■(.if)ū„×ķā×╗»Ų„(Optimizer)Ą─▌ö╚ļĪŻā×╗»Ų„╔·│╔ę╗éĆā×╗»╬─╝■(.opt)Ż¼▀@éĆ╬─╝■ū„×ķ═Ļ│╔▀Mę╗▓Įā×╗»Ą─┤·┤a╔·│╔Ų„(Code generator)Ą─▌ö╚ļŻ¼ūŅĮK╔·│╔ģRŠÄ╬─╝■(.asm)ĪŻ«ö▀xō±ŠÄūg▀xĒŚĢrŻ¼-o2║═-o3īó▒M┐╔─▄Ąžā×╗»▄ø╝■ĪŻ
2.2 ŠÄūgŲ„ā╚┬ō║»öĄ TMS320C6X╠ß╣®┴╦║▄ČÓā╚┬ō║»öĄŻ¼╦³éāų▒Įėė│╔õ×ķā╚ŪČC6XģRŠÄųĖ┴ŅĄ─╠ž╩Ō║»öĄŻ¼▀@śė┐╔čĖ╦┘ā×╗»CšZčį┤·┤aĪŻCŠÄūgŲ„ęįā╚┬ō║»öĄĄ─ą╬╩Įų¦│ų╦∙ėąCšZčį┤·┤a▓╗ęū▒Ē▀_Ą─ųĖ┴ŅĪŻā╚┬ō║»öĄė├Ž┬äØŠĆ"_"ķ_Ņ^Ż¼╚ń└²2Ż¼╩╣ė├Ģr╚ń═¼š{ė├Ųš═©║»öĄę╗śėĪŻŽ┬├µĮY║ŽīŹ└²Ż¼čąŠ┐ę╗Ž┬═Ļ│╔200³c³cĘeĮø▀^╔Ž╩÷Ė„ĘNā×╗»╝╝ągā×╗»║¾Ą─┤·┤aą¦┬╩ĪŻ═Ļ│╔200³cĄ─³cĘe▀\╦ŃCšZčį┤·┤a│╠ą“dotp.c╚ńŽ┬Ż║ 
3 ŠĆąįģRŠÄ┤·┤aĄ─ā×╗» ā×╗»ŠĆąįģRŠÄ┤·┤aŻ¼╩ūŽ╚╩Ū▒M┐╔─▄Ąž╩╣ųĖ┴Ņ▓󹹯¼╩╣Ą├═¼ę╗Ģrķgā╚ČÓéĆ╣”─▄å╬į¬═¼Ģr▒╗╩╣ė├Ż¼╚╗║¾╩Ūš{š¹┤·┤aĒśą“Ż¼┐s£pĄ╚┤²Ģrčė(NOPS)Ż¼╚ń└²5ĪŻĮėŽ┬üĒ╩╣ė├ūųįLå¢shortą═öĄō■Ż¼╚ń└²6Ż¼ūŅ║¾╩╣ė├▄ø╝■┴„╦«╝╝ągĪŻ«ö▀MąąīŹļH▓┘ū„ĢrŻ¼▓ó▓╗╩Ūę¬░┤Ēśą“Ąž═Ļ│╔╔Ž├µĄ─├┐ę╗▓ĮĪŻų╗ę¬▀_ĄĮę¬Ū¾Ż¼Š═┐╔ęįĮY╩°ĪŻ 3.1 CšZčį┤·┤a▐DōQĄĮŠĆąįģRŠÄ┤·┤a Č©³c³cĘeųąŻ¼CšZčį┤·┤aā╚▓┐裣h╩╣ė├ŠĆąįģRŠÄųĖ┴ŅŻ¼╚ń└²3╦∙╩ŠĪŻ
ó┘čb▌dųĖ┴Ņ(LDW)▒žĒÜ╩╣ė├.Då╬į¬ĪŻ ó┌│╦Ę©ųĖ┴Ņ(MPY║═MPYH)▒žĒÜ╩╣ė├.Må╬į¬ĪŻ ó█╝ėĘ©ųĖ┴Ņ(ADD)╩╣ė├.Lå╬į¬ĪŻ ó▄£pĘ©ųĖ┴Ņ(SUB)╩╣ė├.Så╬į¬ĪŻ ó▌╠°▐DųĖ┴Ņ(B)╩╣ė├.Så╬į¬ĪŻ ė╔┤╦Ą├ĄĮ└²4Ą─ģRŠÄ┤·┤aĪŻ 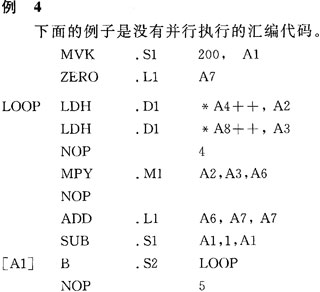 ═Ļ│╔200┤╬裣hĄ³┤·Ż¼Įø▀^profile clockĘų╬÷裣h▓┐ĘųŻ¼ąĶę¬16Ī┴200=3200 cyclesĪŻ 3.3 ╩╣ė├▓óąąųĖ┴Ņ═Ļ│╔³cĘe┤·┤a ╩╣ė├▓óąąųĖ┴Ņ═Ļ│╔³cĘe┤·┤a╚ń└²5╦∙╩ŠĪŻ  ╩╣ė├▓óąąųĖ┴ŅŻ¼čŁŁh¾wā╚ąĶę¬8éĆĢrńŖų▄Ų┌ĪŻ▀@Č╬裣h┤·┤aĄ─ł╠ąąų▄Ų┌×ķ8Ī┴200=1600 cyclesĪŻ 3.4 ╩╣ė├ūų┤µ╚ĪįŁshortą═öĄō■ ×ķ▀Mę╗▓Į╠ßĖ▀ą¦┬╩Ż¼╩╣ė├ūų┤µ╚ĪįŁshortą═öĄō■Ż¼╚ń└²6╦∙╩ŠĪŻ 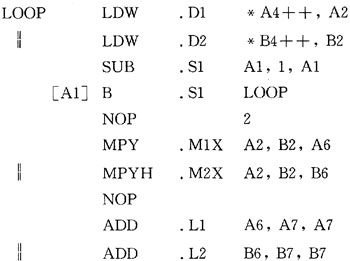 ▀@Č╬┤·┤aį┌裣h¾wā╚╚į╚╗╩Ū8éĆĢrńŖų▄Ų┌Ż¼Ą³┤·100┤╬×ķ8Ī┴100=800 cyclesĪŻ 4 ▄ø╝■┴„╦«╝╝ąg ▄ø╝■┴„╦«╝╝ąg╩Ūė├į┌裣hšZŠõųąš{ė├ųĖ┴ŅĄ─ĘĮĘ©Ż¼╝┤░▓┼┼裣hųąĄ─ČÓéĆĄ³┤·▀\╦Ń▓óąął╠ąąĪŻį┌ŠÄūgCšZčį┤·┤aĢrŻ¼┐╔ęį▀xō±ŠÄūgŲ„Ą─-o2╗“-o3▀xĒŚŻ¼ŠÄūgŲ„īóĖ∙ō■│╠ą“▒M┐╔─▄Ąž░▓┼┼▄ø╝■┴„╦«ĪŻłD3╦∙╩Š×ķ▀\ė├▄ø╝■┴„╦«Ą─裣hĮYśŗŻ¼╦³░³└©AĪóBĪóCĪóDĪóE╬Õ┤╬Ą³┤·Ż¼═¼ę╗ų▄Ų┌ūŅČÓł╠ąą╬Õ┤╬Ą³┤·Ą─▓╗═¼ųĖ┴Ņ(ĻÄė░▓┐Ęų)ĪŻłD3ųąĻÄė░▓┐ĘųĘQ×ķ"裣hā╚║╦"Ż¼║╦ųą▓╗═¼Ą─ųĖ┴Ņ▓óąął╠ąąĪŻ║╦Ū░ł╠ąąĄ─▀^│╠ĘQ×ķ"┴„╦«ŠĆ╠Ņ│õ"Ż¼║╦║¾ł╠ąąĄ─▀^│╠ĘQ×ķ"┴„╦«ŠĆ┼┼┐š"ĪŻ
į┌«ŗŽÓĻPłDĢræ¬ū±čŁŻ║ ó┘«ŗ│÷╣سc║═┬ĘÅĮŻ╗ ó┌īæ│÷═Ļ│╔Ė„ųĖ┴ŅąĶꬥ─CPUų▄Ų┌Ż╗ ó█×ķĖ„╣سcųĖ┼╔╣”─▄å╬į¬Ż╗ ó▄Ęųķ_┬ĘÅĮŻ¼ęį╩╣ūŅČÓĄ─╣”─▄å╬į¬▒╗╩╣ė├ĪŻ Ė∙ō■ŽÓĻPłDīæ│÷─ŻĄ³┤·ķgĖ¶░▓┼┼▒ĒŻ¼╚ń▒Ē1╦∙┴ąĪŻ
 ė╔┤╦Ą├ĄĮĄ─┤·┤a╦∙ąĶCPUĢrńŖų▄Ų┌×ķ7+100+l=108 cyclesĪŻ 5 ┐é ĮY Ė„ĘNā×╗»╝╝ąg╦∙ąĶĢrńŖöĄ╚ń▒Ē2╦∙┴ąĪŻ▒Ēųą└©╠¢ā╚öĄūų×ķ裣hā╚║╦ĢrńŖų▄Ų┌Ż¼└©╠¢Ū░öĄūų×ķ┴„╦«ŠĆ╠Ņ│õĢrńŖų▄Ų┌Ż¼└©╠¢║¾öĄūų×ķ┴„╦«ŠĆ┼┼┐šCPUĢrńŖų▄Ų┌ĪŻ
| |||||||







